







 本文介绍了基于UFORMER的单通道语音增强和去混响技术,该技术结合了复数谱建模和时空注意力机制。通过Encoder、Decoder和Dilated dual-path conformer模块,UFORMER在保持端到端训练的同时,提升了语音处理的性能,尤其在对比DCCRN、TasNet等模型时表现出优越的增强和去混响效果。
本文介绍了基于UFORMER的单通道语音增强和去混响技术,该技术结合了复数谱建模和时空注意力机制。通过Encoder、Decoder和Dilated dual-path conformer模块,UFORMER在保持端到端训练的同时,提升了语音处理的性能,尤其在对比DCCRN、TasNet等模型时表现出优越的增强和去混响效果。
作者:Yihui Fu, Yun Liu, Jingdong Li, Dawei Luo, Shubo Lv, Yukai Jv, Lei Xie
1.动机
近年来,研究者开始尝试采用复数谱,对输入语音频谱的实部和虚部同时进行建模,能够获得更高的理论上限,从而逐渐成为研究的热点方向。但此前的工作没有对这两个域的特征进行联合优化以发掘其潜在的内部联系。由于空间信息的丢失,在单通道场景下的语音去混响充满了挑战。另一方面,从Transformer模型进化而来的Conformer模型因其强大的时序建模能力而在端到端语音识别任务中取得了优异的效果。然而对于语音前端处理模型,不同于语音识别模型,不能只关注时序信息而忽略频带信息,因为不同频带包含不同的能量和信息,需要更精细化的建模方式。因此研究者对自注意力机制进行了双路(Dual-path)改造,即在时频两个维度分别进行注意力机制学习。
2.网路架构
Uformer包含Encoder、Decoder和Dilated dual-path conformer三个主要的模块。如下图
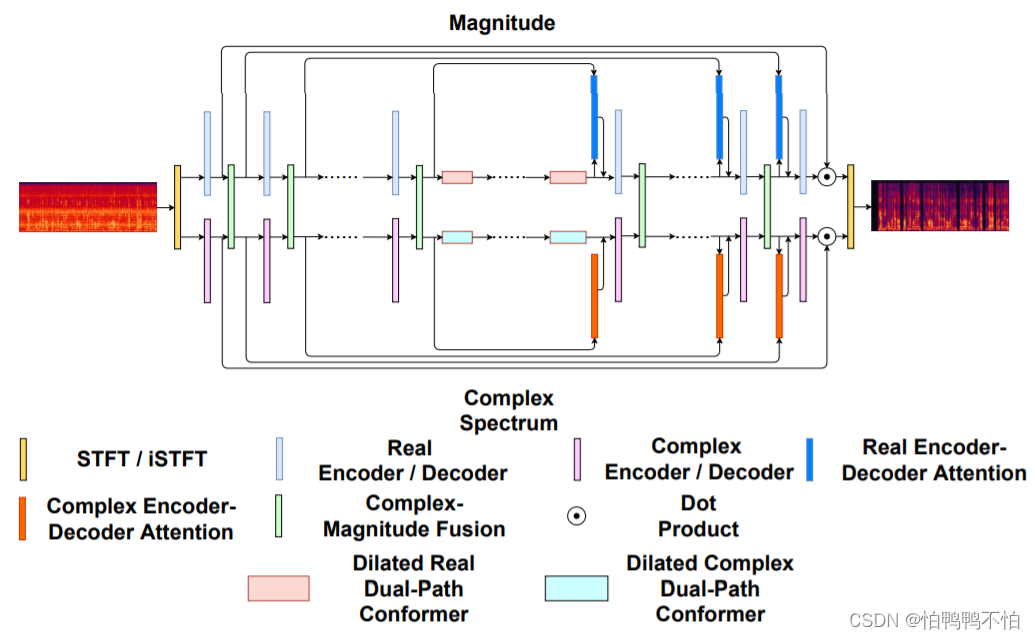
Encoder通过卷积层的堆叠以学习到语音的高维特征,Decoder通过反卷积层的堆叠以将高维特征映射到与输入相同维度。每层Encoder和Decoder都使用了Hybrid Encoder and Decoder架构来同时进行复数谱和幅度谱的建模和信息融合,每层Encoder和Decoder之间都使用了Encoder Decoder Attention机制来学习到对应层之间的相关性。对于Dilated dual-path conformer,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









