








 超级会员免费看
超级会员免费看

 本篇博客介绍了三项人工智能领域的最新成果:MotionLLM通过结合视频和运动数据理解人类行为,RapVerse能从文本生成连贯的声音和全身动作,Streaming Video Diffusion则实现了在线视频编辑。这些研究涵盖了深度学习、扩散模型和计算机视觉等领域,推动了多模态理解和生成技术的发展。
本篇博客介绍了三项人工智能领域的最新成果:MotionLLM通过结合视频和运动数据理解人类行为,RapVerse能从文本生成连贯的声音和全身动作,Streaming Video Diffusion则实现了在线视频编辑。这些研究涵盖了深度学习、扩散模型和计算机视觉等领域,推动了多模态理解和生成技术的发展。
MotionLLM: Understanding Human Behaviors from Human Motions and Videos

本研究提出了一种名为MotionLLM的新型框架,旨在通过结合视频和运动序列(如SMPL序列)的多模态数据,利用大型语言模型(LLMs)的能力来理解人类行为。与以往只针对视频或运动数据的LLMs不同,MotionLLM强调了联合建模的必要性,以更准确、全面地捕捉身体动态和语义。研究团队创建了MoVid数据集,并提出了MoVid-Bench基准测试,用于评估模型对视频和运动中人类行为理解的性能。
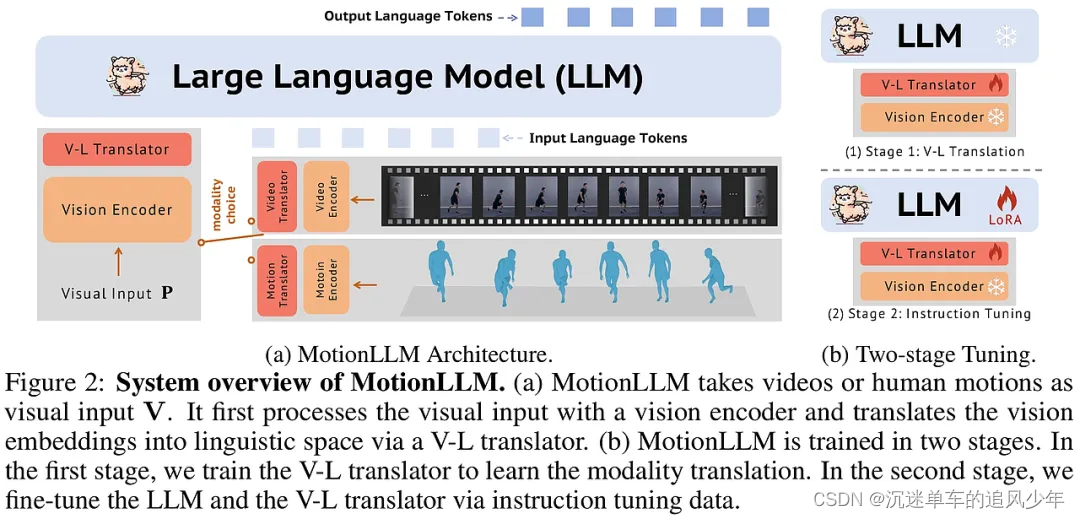
MotionLLM采用统一的视频-运动训练策略,结合了现有粗糙视频-文本数据和精细运动-文本数据的互补优势,以获得丰富的时空洞察。该框架包括两个阶段:第一阶段,通过可训练的运动/视频转换器

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











