







 超级会员免费看
超级会员免费看
 本文介绍了一种使用预训练的VGG16作为编码器和LSTM作为解码器的模型,用于image-to-text任务。在CNN编码图像后,LSTM解码器通过预处理步骤(如添加开始和结束标记、padding、词到索引和embedding)将向量解码成文本。实验基于COCO数据集,并提供了代码和预训练模型链接。
本文介绍了一种使用预训练的VGG16作为编码器和LSTM作为解码器的模型,用于image-to-text任务。在CNN编码图像后,LSTM解码器通过预处理步骤(如添加开始和结束标记、padding、词到索引和embedding)将向量解码成文本。实验基于COCO数据集,并提供了代码和预训练模型链接。
前言:text-image配对数据集并不是珍贵的,OpenAI为了训练GLIDE等大模型,曾经使用十亿量级的text-image数据集,而这些数据集主要是从互联网上爬取过滤的。image-to-text作为image-to-text的镜像问题,相关的研究少了很多。我们可以用CNN+LSTM搭建一个成功的模型用于完成这一任务。
目录
方法详解
整体流程
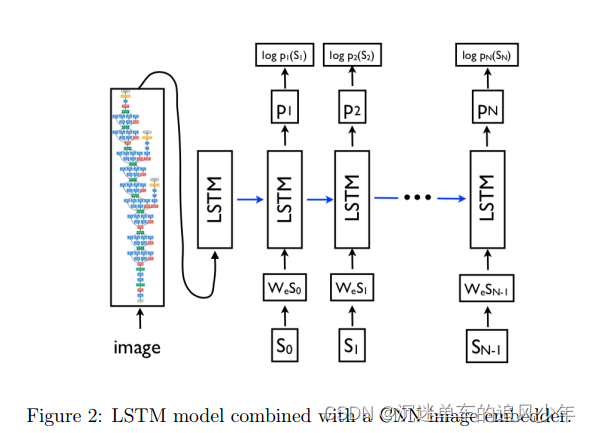
目前的模型是受Sequence2Sequence的启发,Seq2Seq是自然语言处理中机器翻译中常用的序列模型。利用循环神经网络保留时间信息,将文本嵌入到向量空间。在传统机器翻译中,输入和输出是不同语言的文本。因此,RNN被用作Sequence2Sequence模型中的编码器/解码器。编码器将输入文本编码为公共向量空间,解码器将向量空间解码以生成输出文本。对于图像描述,输入是

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











