







 超级会员免费看
超级会员免费看

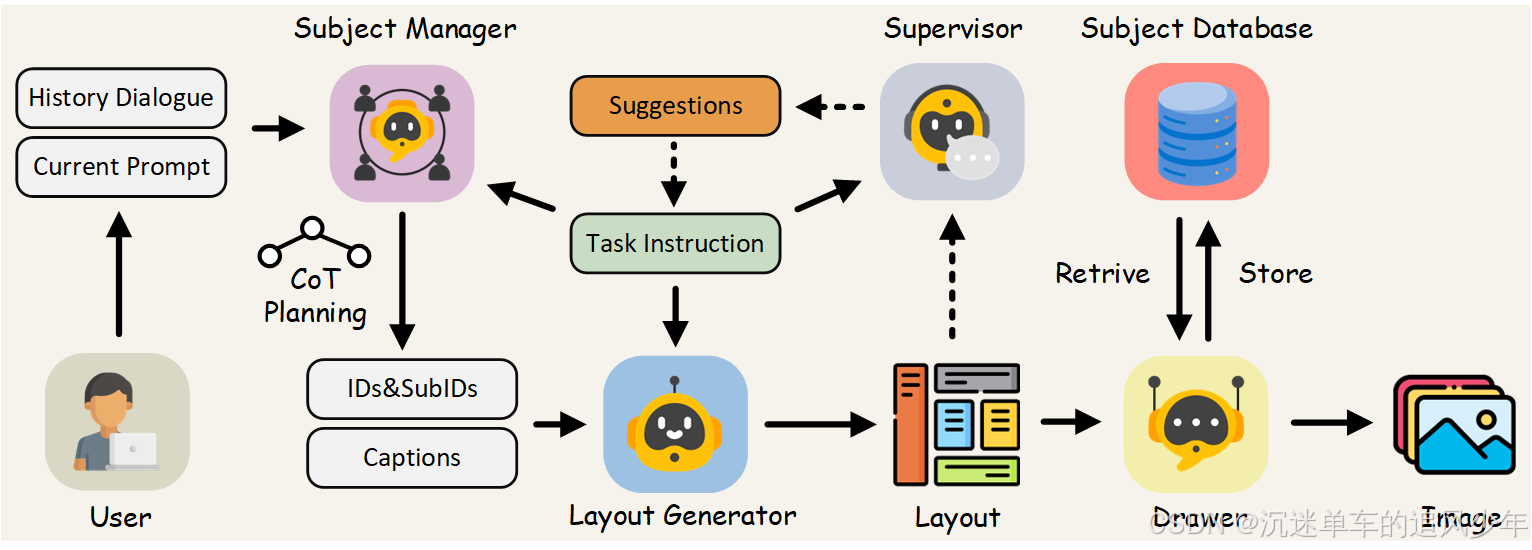
由于尖端的文本到图像(tt2i)生成模型已经擅长于生成出色的单幅图像,一项更具挑战性的任务,即多回合交互式图像生成开始引起相关研究团体的关注。这项任务要求模型在多个回合中与用户交互,以生成连贯的图像序列。然而,由于用户可能频繁切换主题,目前的努力是在生成不同图像的同时保持主题的一致性。为了解决这个问题,我们引入了一个无需训练的多智能体框架AutoStudio。AutoStudio使用三个基于大型语言模型(llm)的代理来处理交互,以及一个基于稳定扩散(SD)的代理来生成高质量的图像。具体来说,AutoStudio包括

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











