







 超级会员免费看
超级会员免费看
前言:之前绝大多数Diffusion数字人都是基于AnimateDiff基础模型的,基于SVD基础模型的非常少。最近腾讯发布了基于SVD的数字人技术Sonic,效果非常好,甚至比基于CogVideox的Hallo3的还要惊艳,值得深入研究。
目录
2、Context-enhanced audio learning
贡献概述
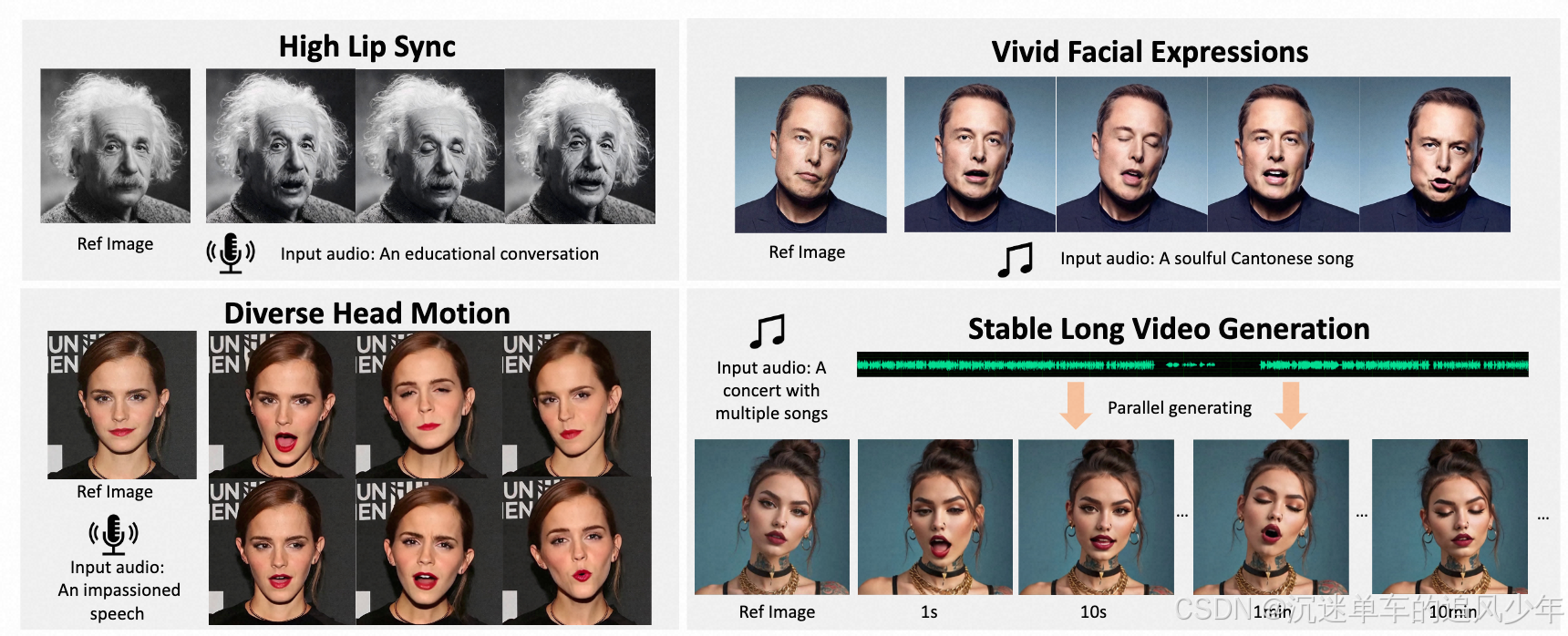
作者自己总结的四点贡献:
- 我们提出了一种新颖的统一范式,没有视觉运动的
前言:之前绝大多数Diffusion数字人都是基于AnimateDiff基础模型的,基于SVD基础模型的非常少。最近腾讯发布了基于SVD的数字人技术Sonic,效果非常好,甚至比基于CogVideox的Hallo3的还要惊艳,值得深入研究。
目录
2、Context-enhanced audio learning
作者自己总结的四点贡献:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























