







[文献阅读笔记]:SEPT: TOWARDS EFFICIENT SCENE REPRESENTATION LEARNING FOR MOTION PREDICTION
文章目录
文章地址:https://arxiv.org/pdf/2309.15289.pdf
1. 概述
SEPT所做的工作和Forecast-MAE总体很像,同样都是采用了自监督学习的方式对模型进行预训练,在此基础上进行fine-tune来预测轨迹输出,感兴趣的小伙伴可以看一下之前的这篇文章,
1.1 模型解决问题的方向
- 训练方法:自监督学习+监督学习,通过设计不同的三个子学习任务来对模型的结构进行预训练。
- 网络结构设计:两个不同的transformer模块来依次提取时序和空间交互特征,使用Learnable query与交互特征做cross-attention,输出最后的预测结果。
1.2 主要结论和贡献
-
作者设计了三种不同的自监督学习方法,分别是
- *Marked Trajectory Modeling (MTM),*随机mask掉轨迹中的部分点,通过预训练任务,旨在预训练时序特征提取模块,使模块可以更有效的建模时序特征。
- Masked Road Modeling (MRM),随机mask掉输入道路特征的部分点,旨在训练空间特征提取模块。
- Tail Prediction (TP),将轨迹分为头部和尾部,旨在通过前半部分的轨迹特征,预测后半部分的轨迹特征,算是简化版的轨迹预测。
SEPT与Forecast在SSL应用上的区别和联系:
相同点:
二者都是通过SSL,对模型的结构进行预训练,旨在获得模型在时序交互、空间交互上特征提取的能力。
不同点:
对于轨迹的mask:fmae,mask掉一部分比例的历史或者未来轨迹;sept则是mask掉历史轨迹中的部分轨迹点
对于轨迹的预测:fmae,是预测被mask掉的历史或者未来轨迹;sept则是预测mask掉的轨迹点
预训练任务:fmae,将车道与轨迹的重建,放到一个预训练任务中,通过一个任务,完成车道线与轨迹 mask部分的重建;
sept,则是分别预测轨迹、车道获取模型对时序以及空间建模的能力以及通过TP任务完成时空特征的交互。
2. 模型
2.1 模型架构
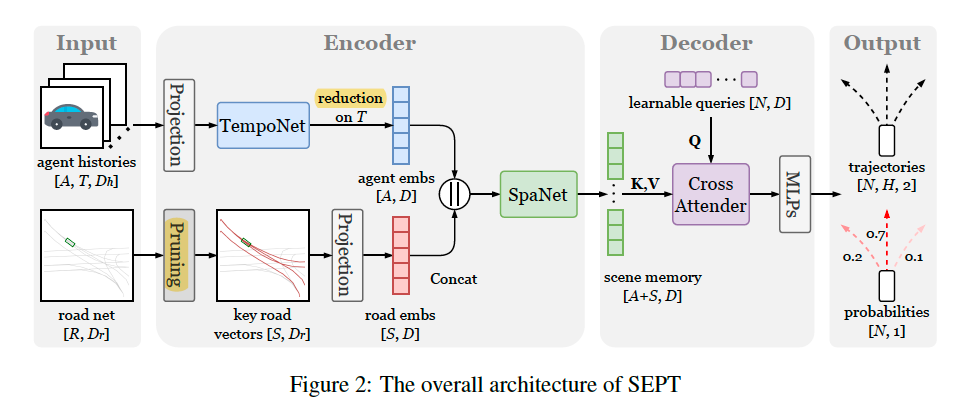
Input
轨迹:历史轨迹 [ A , T , D h ] [A,T,D_h] [A,T,Dh],其中A为周围障碍物的数量,T为时间序列的长度,特征包括轨迹点坐标,时间戳,类型和其他数据集属性
车道:车道线 [ R , D r ] [R,D_r] [R,D
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









