







视频与图像情绪分类
1. 视频分类
FER(Facial Expression Recognition),人脸表情识别
情绪标注:包含恐惧…
情感标注:积极,消极,中性
MELD:来源于老友记,多人对话形式,是EmotionLines老友记部分的多模态扩充(文本+视频)。1433段对话,共13708句。标注了7类情绪:Neutral, Happiness, Surprise, Sadness, Anger, Disgust, Fear和3类情感:Positive, Negative, Neutral,非中性情绪占比53%。 MELD是对话情绪识别中常用的数据集之一,优点是数据集质量较高并且有多模态信息,缺点是数据集中的对话涉及到的剧情背景太多,情绪识别难度很大,Github在此
EULA:带注释的知识共享情感数据库,用于情感视频内容分析,需要申请,官网
FER-2013:表征学习的挑战,面部表情识别的挑战,官网,数据怎么得出来不太清楚
MMI Facial Expression Database:MMI面部表情数据库是一个正在进行的项目,其目的是向面部表情分析界提供大量的面部表情视觉数据。阻碍人类行为自动分析领域的新发展,特别是情感识别的一个主要问题是缺乏显示行为和情感的数据库。为了解决这个问题,MMI-面部表情数据库在2002年被设想为建立和评估面部表情识别算法的资源。该数据库解决了其他面部表情数据库中的一些关键遗漏。特别是,它包含了一个面部表情的全部时间模式的记录,从中性开始,经过一系列的起始、顶点和偏移阶段,再返回到中性脸。需要申请,官网
ExpW:丰富的人脸表征来捕捉性别、表情、头部姿势和年龄相关的属性,官网,这是图像与情绪的对应
1.1 MTCNN
- Tensorflow Github
pip install mtcnn
- Pytorch Github
关于cv2.VideoWriter_fourcc函数用法可见此
MTCNN也会出错:

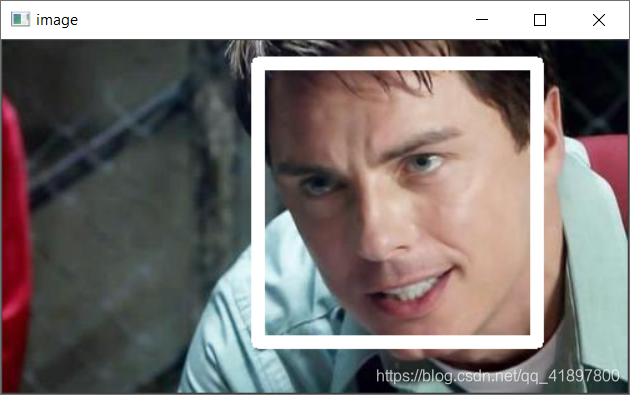
解决方法:每次都取第一个人脸检测的结果,人脸识别代码:
from src import detect_faces
from PIL import Image
import cv2 # 4.5.1
image_path = 'D:/Photos/ysc.jpg'
path = '... your path/MMSA/Datasets/SIMS/Raw/video/video_0001/0001.mp4'
output_path = '... your path/output.avi'
def show_bboxes(image, bounding_boxes, facial_landmarks=[]):
draw = image.copy()
for b in bounding_boxes:
cv2.rectangle(draw, (int(b[0]), int(b[1])), (int(b[2]), int(b[3])), (255, 255, 255), 10)
# print(int(b[2]) - int(b[0]))
# print(int(b[3]) - int(b[1]))
for p in facial_landmarks:
for i in range(5):
cv2.circle(draw, (p[i], p[i + 5]), 1, (0, 0, 255), 10)
return draw
def readtest():
videoname = path
capture = cv2.VideoCapture(videoname)
# frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取视频宽度
# frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取视频高度
fps = capture.get(cv2.CAP_PROP_FPS) # 视频平均帧率
n_fps = capture.get(cv2.CAP_PROP_FRAME_COUNT)
fourcc = cv2.VideoWriter_fourcc('X','V','I','D') # 'X','2','6','4', 'M', 'P', '4', 'V', 'X','V','I','D'
videoWriter = cv2.VideoWriter(output_path, fourcc, fps, (150, 96)) # 150*96(188, 252), , False灰度图
cnt = 0
if capture.isOpened():
while True:
print('\r%d / %d' % (cnt, n_fps), end='')
ret, img = capture.read() # img 就是一帧图片
if not ret: break # 当获取完最后一帧就结束
img_PIL = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # OpenCV => PIL
bounding_boxes, landmarks = detect_faces(img_PIL)
if len(bounding_boxes) == 0:
print(videoname)
# draw = show_bboxes(img, bounding_boxes, landmarks)
# cv2.imshow('Window', draw)
# cv2.waitKey(0)
else:
bounding_boxes = [[int(i) for i in bounding_boxes[0]]]
# landmarks = [[int(i) for i in landmarks[0]]]
# img = show_bboxes(img, bounding_boxes, landmarks)
for b in bounding_boxes:
draw = img[b[1]:b[3], b[0]:b[2]]
draw = cv2.resize(draw, (150, 96)) # 缩放至固定尺寸
# draw = cv2.cvtColor(draw, cv2.COLOR_BGR2GRAY) # 灰度图
videoWriter.write(draw)
cnt += 1
videoWriter.release()
else:
print('视频打开失败!')
readtest()
1.2 安装OpenFace 2.2.0
官网,需要引用以下:
OpenFace 2.0: Facial Behavior Analysis Toolkit
Tadas Baltrušaitis, Amir Zadeh, Yao Chong Lim, and Louis-Philippe Morency,
IEEE International Conference on Automatic Face and Gesture Recognition, 2018
运行报错:
OpenCV: terminate handler is called! The last OpenCV error is:
OpenCV(4.1.0) Error: Assertion failed (type == CV_64FC2) in cv::opt_AVX2::gemmImpl, file c:\build\master_winpack-build-win64-vc15\opencv\modules\core\src\matmul.simd.hpp, line 1066
安装opencv 4.1.0试试,官网下载地址,但试了很久并不能产生示例的output,所以放弃OpenFace,其运行过程
在ubuntu上安装一下试试,但是git很慢,而且可能还需要权限,我可能安装不了
要求如下,但是我dlib安不上,再试试服务器吧:
numpy >= 1.1, < 2.0 # 1.19.2
scipy >= 0.13, < 0.17 # 1.6.0
pandas >= 0.13, < 0.18 # 1.2.3
scikit-learn >= 0.17, < 0.18
nose >= 1.3.1, < 1.4 # 1.3.7
nolearn == 0.5b1
1.3 LSTM
视频转灰度,对于MELD数据集,有’sadness’, ‘disgust’, ‘fear’, ‘joy’, ‘anger’, ‘neutral’, 'surprise’这些情绪,认为:
emo2num = {
'sadness':0,
'disgust':0,
'fear':0,
'joy':1,
'anger':0,
'surprise':1
}
原来总共有9989个视频,转换后有5279个视频,其中标签为0数量:2331,标签为1数量:2948
将总共有2281个视频(Neutral:345),转换后标签为0数量:1238,标签为1的数量:698
LSTM的dim为150×96=14400,95%作为训练集(5015),5%作为测试集(264),最大迭代次数为10,可以发现Loss降得很慢,训练时间很长,结果如下:
当前代数:0,cnt:5007,平均训练集Loss:22.2459,验证集精确度:0.5379,Total time:4m 37s
当前代数:1,cnt:10014,平均训练集Loss:22.0783,验证集精确度:0.5000,Total time:9m 23s
当前代数:2,cnt:15021,平均训练集Loss:22.0122,验证集精确度:0.5909,Total time:13m 35s
当前代数:3,cnt:20028,平均训练集Loss:21.9838,验证集精确度:0.5758,Total time:17m 53s
当前代数:4,cnt:25035,平均训练集Loss:21.9460,验证集精确度:0.5114,Total time:22m 14s
当前代数:5,cnt:30042,平均训练集Loss:21.9223,验证集精确度:0.5530,Total time:26m 29s
当前代数:6,cnt:35049,平均训练集Loss:21.9133,验证集精确度:0.4242,Total time:30m 49s
当前代数:7,cnt:40056,平均训练集Loss:21.9022,验证集精确度:0.5909,Total time:35m 14s
当前代数:8,cnt:45063,平均训练集Loss:21.8852,验证集精确度:0.5909,Total time:39m 37s
当前代数:9,cnt:50070,平均训练集Loss:21.8807,验证集精确度:0.5417,Total time:44m 43s
最大迭代次数100,学习率设为0.005,90%作为训练集(4751):
当前代数:26,平均训练集Loss:22.2553,验证集精确度:0.5844,Total time:121m 1s
Save model!
...
当前代数:99,平均训练集Loss:22.2550,验证集精确度:0.5370,Total time:447m 57s

最大迭代次数100,学习率还是设为0.001,90%作为训练集(4751):
...
当前代数:99,平均训练集Loss:21.7791,验证集精确度:0.5285,Total time:446m 25s
精确度没有超过0.5844的,可能与参数太少有关,也可能与数据集太少且没做特征提取有关,也可能是batch=1有关…所以还是放弃做视频部分的实验吧~

1.4 卷积神经网络
torch.nn.conv3d官方文档
MaxPool3d官方文档
Loss降得太慢了…
Cuda is available!
当前代数:0,平均训练集Loss:22.0244,验证集精确度:0.4867,Total time:31m 9s
当前代数:1,平均训练集Loss:22.0167,验证集精确度:0.5209,Total time:62m 18s
当前代数:2,平均训练集Loss:22.0122,验证集精确度:0.5209,Total time:93m 22s
当前代数:3,平均训练集Loss:21.9955,验证集精确度:0.5209,Total time:124m 44s
当前代数:4,平均训练集Loss:21.9869,验证集精确度:0.5209,Total time:156m 2s
当前代数:5,平均训练集Loss:21.9884,验证集精确度:0.5209,Total time:187m 23s
当前代数:6,平均训练集Loss:21.9869,验证集精确度:0.5209,Total time:218m 30s
当前代数:7,平均训练集Loss:21.9848,验证集精确度:0.5209,Total time:250m 2s
当前代数:8,平均训练集Loss:21.9827,验证集精确度:0.5209,Total time:281m 41s
当前代数:9,平均训练集Loss:21.9814,验证集精确度:0.5209,Total time:313m 20s
emo2num = {
'sadness':0,
'disgust':0,
'fear':0,
'joy':1,
'anger':0,
'surprise':1
}
import csv
list = []
emo_path = '/mnt/Data1/ysc/MELD.Raw/train/train_sent_emo.csv'
with open(emo_path, 'r', encoding='utf-8') as f:
csv_file = csv.reader(f)
for line in csv_file:
if line[3]=='Emotion':continue
if line[3]=='neutral':continue
list.append([line[5], line[6], emo2num[line[3]]])
# print(list)
# print(path_video)
# print(label)
# print(len(path_video))
# print(len(label))
import torch
import numpy as np
import torch.nn as nn
from torch.utils.data import Dataset # Dataset的抽象类,所有其他数据集都应该进行子类化,所有子类应该override__len__和__getitem__,前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)
import cv2
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from PIL import Image
import torch.nn.functional as F
path = '...your path'
IMAGE_H = 150 # 默认输入网络的图片大小
IMAGE_W = 96
data_transform = transforms.Compose([transforms.ToTensor()]) # H*W*C to C*H*W
class VideoDataset(Dataset):
def __init__(self, mode):
self.mode = mode
self.length = 0
self.path_video = []
self.label = []
path = '/mnt/Data1/ysc/MELD.Raw/train/face/'
for i in list:
if i[0]==811 and i[1]==10: continue
if i[0] == 813 and i[1] == 1: continue
if i[0] == 517 and i[1] == 1: continue
if i[0] == 608: continue
if i[0] == 967 and i[1] == 7: continue
if i[0] == 810 and i[1] == 0: continue
self.path_video.append(path + 'dia{}_utt{}.avi'.format(i[0], i[1]))
self.label.append(i[2])
self.length += 1
def __getitem__(self, item):
if self.mode == 'train':
capture = cv2.VideoCapture(self.path_video[item])
video_tensor = torch.tensor([])
if capture.isOpened():
while True:
ret, img = capture.read() # img 就是一帧图片
if not ret: break # 当获取完最后一帧就结束
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_PIL = Image.fromarray(img)
img_tensor = data_transform(img_PIL)
video_tensor = torch.cat((video_tensor, img_tensor))
n_fps = capture.get(cv2.CAP_PROP_FRAME_COUNT)
if n_fps!=video_tensor.size()[0]: print('Error!')
label_tensor = torch.tensor(self.label[item])
return video_tensor.unsqueeze(0), label_tensor
def __len__(self):
return self.length # 5279
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv3d(1, 2, kernel_size=[1,3,3], padding=[0,1,1])
self.conv2 = nn.Conv3d(2, 4, kernel_size=[1,4,3], padding=[0,1,1])
self.conv3 = nn.Conv3d(4, 8, kernel_size=[1, 4, 3], padding=[0, 1, 1])
self.conv4 = nn.Conv3d(8, 16, kernel_size=[1, 3, 3], padding=[0, 1, 1])
self.conv5 = nn.Conv3d(16, 32, kernel_size=[1, 4, 3], padding=[0, 1, 1])
# self.gru = nn.GRU(input_size=384, hidden_size=HIDDEN_SIZE, num_layers=2, bidirectional=True)
self.gru = nn.GRU(input_size=150*96, hidden_size=HIDDEN_SIZE, num_layers=2, bidirectional=True)
self.liner = nn.Linear(128, 2)
# def forward(self, x): # 1 * 32 * 150 * 96
#
# x = self.conv1(x) # 2 * 32 * 150 * 96
# x = F.relu(x)
# x = F.max_pool3d(x, [1,2,2]) # 2 * 32 * 75 * 48
# x = self.conv2(x) # 4 * 32 * 74 * 48
# x = F.relu(x)
# x = F.max_pool3d(x, [1,2,2]) # 4 * 32 * 37 * 24
# x = self.conv3(x) # 8 * 32 * 36 * 24
# x = F.relu(x)
# x = F.max_pool3d(x, [1,2,2]) # 8 * 32 * 18 * 12
# x = self.conv4(x) # 16 * 32 * 18 * 12
# x = F.relu(x)
# x = F.max_pool3d(x, [1, 2, 2]) # 16 * 32 * 9 * 6
# x = self.conv5(x) # 32 * 32 * 8 * 6
# x = F.relu(x)
# x = F.max_pool3d(x, [1, 2, 2]) # 32 * 32 * 4 * 3
# x = x.permute(2,0,1,3,4).contiguous()
# x = x.view(x.size()[0],x.size()[1],-1) # seq_len * batch * 384
# x, hidden = self.gru(x) # seq_len * batch * (64*2), 4 * batch * 64
# y = hidden.permute(1,0,2).contiguous() # batch * 4 * hidden
# y = y.view(y.size()[0], -1) # batch * 256
# y = self.liner(y)
#
# return y
def forward(self, x): # 1 * 32 * 150 * 96
x = x.permute(2,0,1,3,4).contiguous()
x = x.view(x.size()[0],x.size()[1],-1) # seq_len * batch * 384
x, hidden = self.gru(x) # seq_len * batch * (64*2), 4 * batch * 64
y = hidden.permute(1,0,2).contiguous() # batch * 4 * hidden
y = y.view(y.size()[0], -1) # batch * 256
y = self.liner(y)
return y
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for wave, label in dataloader:
if len(wave.size()) != 5: continue
wave, label = wave.cuda(), label.cuda()
predicted_label = model(wave)
# print(predicted_label.argmax(1))
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += 1
model.train()
return total_acc / total_count
HIDDEN_SIZE = 32
BATCH_SIZE = 1
from torch.utils.data.dataset import random_split
import time
import matplotlib.pyplot as plt
datafile = VideoDataset('train')
dataloader = DataLoader(datafile)
n_train = int(len(datafile) * 0.9)
split_train, split_valid = random_split(dataset=datafile, lengths=[n_train, len(datafile) - n_train])
train_dataloader = DataLoader(split_train, batch_size=BATCH_SIZE, shuffle=True)
valid_dataloader = DataLoader(split_valid, batch_size=BATCH_SIZE, shuffle=True)
print(len(train_dataloader))
print(len(valid_dataloader))
model = Net()
acc_min = 0.5844
cnt = 0
if torch.cuda.is_available() == True:
print('Cuda is available!')
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 107186
start_time = time.time()
losses = 0
loss_plot = []
for epoch in range(100): # 最大迭代次数
for video, label in train_dataloader:
if len(video.size()) != 5: continue
video, label = video.cuda(), label.cuda()
# print(cnt)
out = model(video)
loss = criterion(out, label)
losses += loss
if (cnt+1) % 32 == 0:
losses.backward()
loss_plot.append(losses)
# print(losses)
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.25)
optimizer.step()
optimizer.zero_grad()
losses = 0
# if (cnt+1) % 500 == 0:
# print(losses)
# print((cnt+1)/500)
# acc_valid = evaluate(valid_dataloader)
cnt += 1
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
acc_valid = evaluate(valid_dataloader)
print('当前代数:{},平均训练集Loss:{:.4f},验证集精确度:{:.4f},Total time:{}m {}s'.format(epoch,
sum(loss_plot) / len(loss_plot),
acc_valid, epoch_mins, epoch_secs))
if acc_valid > acc_min:
acc_min = acc_valid
torch.save(model.state_dict(), 'model_video.pth')
print('Save model!')
plt.plot(loss_plot)
plt.show()
1.5 Gabor小波变化
2. 图像分类
还是基于图像做好了,对每一帧来判断
2.1 百度paddle
2.2
利用图片数据集,处理一下数据后大概是这样:
"0" "angry"
"1" "disgust"
"2" "fear"
"3" "happy"
"4" "sad"
"5" "surprise"
"6" "neutral"
剔除人脸识别的置信度在10%以下的结果,忽略neutral,将以上分别对应为0、1,最终的得到的n_pos,n_neg数量分别为:25775、16518
85%作为训练集:Length of train set is 35949, Length of valid set is 6344,最大迭代次数为10,batch=32,每50次迭代(1600)张图片打印一次结果:
当前代数:9,batch:0.425,平均训练集Loss:0.6041,验证集精确度:0.7070,Total time:158m 52s
Save model!
...
当前代数:9,batch:0.55,平均训练集Loss:0.6028,验证集精确度:0.7015,Total time:161m 49s
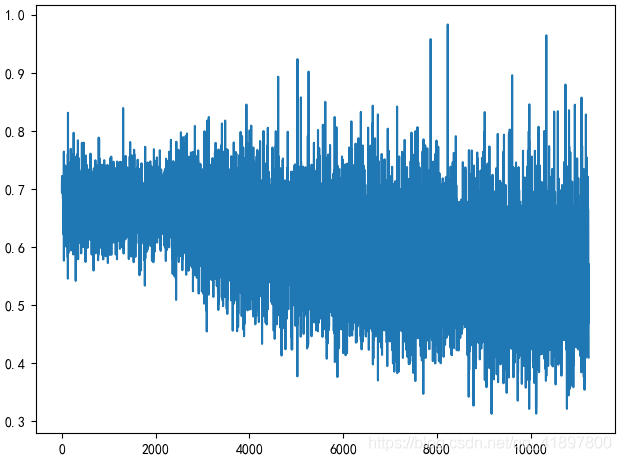
最大迭代次数改为100,增加学习率修剪,并没有很好的样子,LOSS降不下去,可能是学习率衰减的太小了,那我们就不要修剪学习率:
...
当前代数:46,batch:13.0,平均训练集Loss:0.6693,验证集精确度:0.6125,Total time:618m 53s
当前代数:46,batch:14.0,平均训练集Loss:0.6693,验证集精确度:0.6125,Total time:619m 33s
每200次迭代(6400)判断一次结果:
当前代数:14,batch:1.0,平均训练集Loss:0.5851,验证集精确度:0.7071,Total time:109m 39s
Save model!
...
当前代数:18,batch:2.0,平均训练集Loss:0.5701,验证集精确度:0.7112,Total time:130m 23s
Save model!
...
当前代数:99,batch:5.0,平均训练集Loss:0.4519,验证集精确度:0.6734,Total time:540m 50s
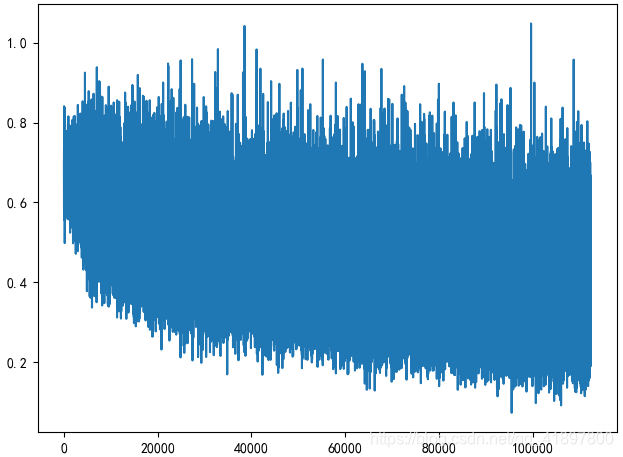
可见效果还是一般,剔除人脸识别的置信度在25%以下的结果,再次运行:
得到的n_pos,n_neg数量分别为:23008,14383
剔除人脸识别的置信度在40%以下的结果,19048,11229,Length of train set is 25735, Length of valid set is 4542,每100次迭代(3200)判断一次结果:
当前代数:8,batch:8.0,平均训练集Loss:0.6128,验证集精确度:0.7197,Total time:48m 4s
Save model!
...
当前代数:19,batch:7.0,平均训练集Loss:0.5486,验证集精确度:0.7472,Total time:100m 19s
Save model!
...
前代数:99,batch:8.0,平均训练集Loss:0.3421,验证集精确度:0.7078,Total time:552m 51s
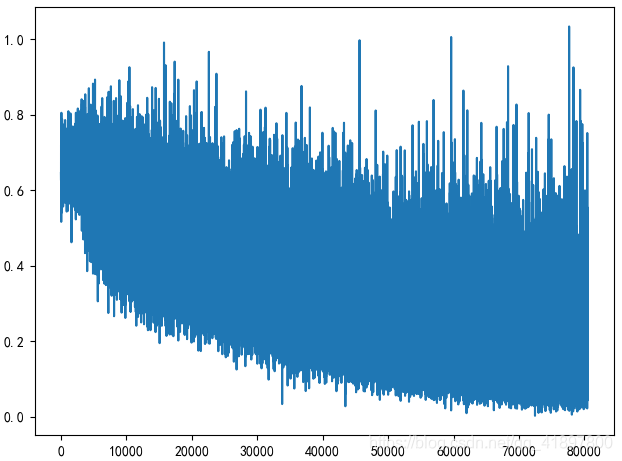
剔除人脸识别的置信度在50%以下的结果,15787 8752,Length of train set is 20858, Length of valid set is 3681,每100次迭代(3200)判断一次结果:
当前代数:29,batch:6.0,平均训练集Loss:0.4824,验证集精确度:0.7691,Total time:108m 51s
Save model!
...
当前代数:99,batch:6.0,平均训练集Loss:0.2892,验证集精确度:0.7205,Total time:343m 55s
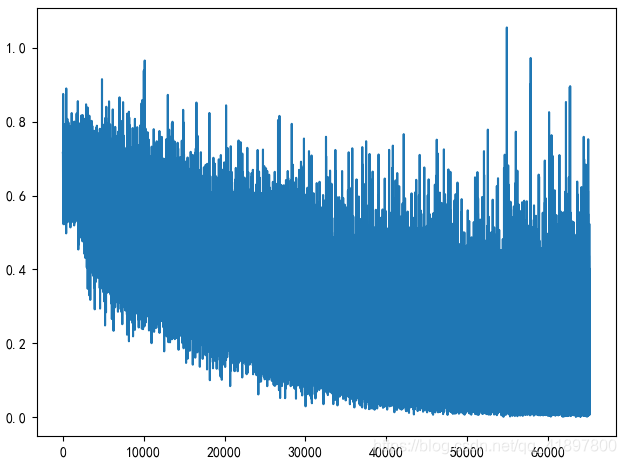
剔除人脸识别的置信度在60%以下的结果,12329 6177,Length of train set is 15730, Length of valid set is 2776,结果如下:
当前代数:37,batch:4.0,平均训练集Loss:0.5150,验证集精确度:0.7777,Total time:80m 35s
Save model!
...
当前代数:99,batch:4.0,平均训练集Loss:0.3353,验证集精确度:0.7504,Total time:207m 50s
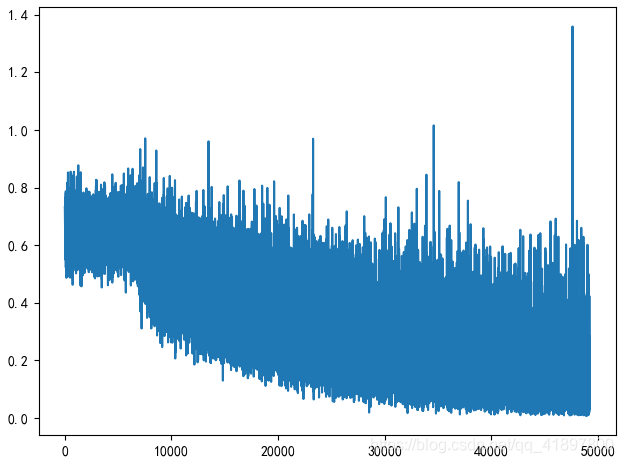
剔除人脸识别的置信度在70%以下的结果,8647 3919,Length of train set is 10681, Length of valid set is 1885,结果如下:
...
当前代数:99,batch:3.0,平均训练集Loss:0.2360,验证集精确度:0.7353,Total time:128m 58s
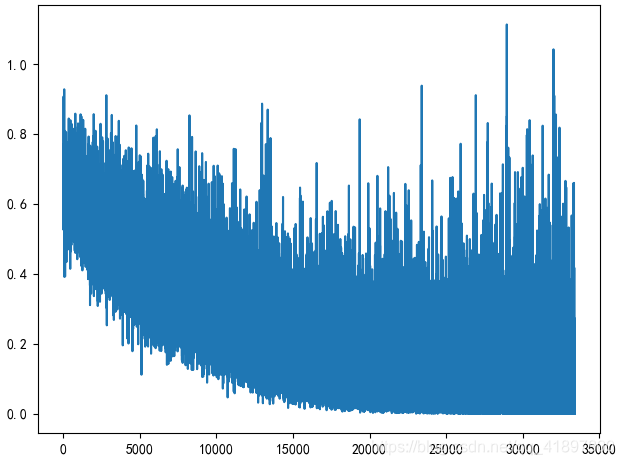
batch=64,每30代(1920张)图片判断一下验证集精确度:
当前代数:99,batch:5.0,平均训练集Loss:0.2479,验证集精确度:0.7480,Total time:160m 3s
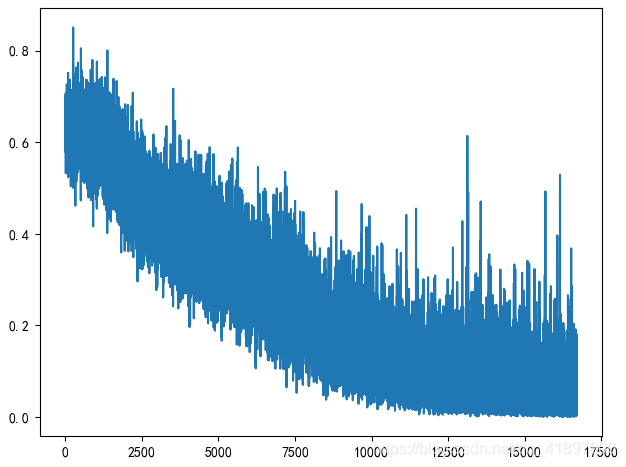 剔除人脸识别的置信度在75%以下的结果,6899 2961 Length of train set is 8381, Length of valid set is 1479 batch=32,每30代(960张)图片判断一下验证集精确度,但是训练三代都没有变化
剔除人脸识别的置信度在75%以下的结果,6899 2961 Length of train set is 8381, Length of valid set is 1479 batch=32,每30代(960张)图片判断一下验证集精确度,但是训练三代都没有变化
这里进行数据增强,把NEG的直接扩展一遍:6899 5922 Length of train set is 10897, Length of valid set is 1924,结果如下:
当前代数:90,batch:8.0,平均训练集Loss:0.1941,验证集精确度:0.8784,Total time:219m 38s
Save model!
...
当前代数:99,batch:11.0,平均训练集Loss:0.1819,验证集精确度:0.8555,Total time:242m 34s
图片分类代码
import torch
import numpy as np
import torch.nn as nn
from torch.utils.data import Dataset # Dataset的抽象类,所有其他数据集都应该进行子类化,所有子类应该override__len__和__getitem__,前者提供了数据集的大小,后者支持整数索引,范围从0到len(self)
import cv2
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.nn.functional as F
from PIL import Image
import time
from torch.utils.data.dataset import random_split
import matplotlib.pyplot as plt
path_image = '/mnt/Data1/ysc/image/origin/'
path_label = '/mnt/Data1/ysc/image/label/label.lst'
def show_bboxes(path, bounging_boxes = None):
b = bounging_boxes
# print(b)
# print(path)
image = cv2.imread(path)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# draw = image.copy()
# cv2.rectangle(draw, (int(b[1]), int(b[0])), (int(b[2]), int(b[3])), (255, 255, 255), 10)
draw = image[b[0]:b[3], b[1]:b[2]]
draw = cv2.resize(draw, (96, 150)) # 缩放至固定尺寸
# cv2.namedWindow('image')
# cv2.imshow('image', draw)
# cv2.waitKey()
return draw
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3, padding=1)
self.conv2 = nn.Conv2d(2, 4, [4,3], padding=1)
self.conv3 = nn.Conv2d(4, 8, [4, 3], padding=1)
self.conv4 = nn.Conv2d(8, 16, 3, padding=1)
self.conv5 = nn.Conv2d(16, 32, [4,3], padding=1)
self.fc1 = nn.Linear(384, 64)
self.fc2 = nn.Linear(64, 16)
self.fc3 = nn.Linear(16, 2)
def forward(self, x): #
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # batch * 2, 75, 48
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # batch * 4, 37, 24
x = self.conv3(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # batch * 8, 18, 12
x = self.conv4(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # batch * 16, 9, 6
x = self.conv5(x)
x = F.relu(x)
x = F.max_pool2d(x, 2) # batch * 32, 4, 3
x = x.view(x.size()[0], -1) # batch * 384
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
emo2num = {
'4':'0',
'1':'0',
'2':'0',
'3':'1',
'0':'0',
'5':'1'
}
label_list={}
with open(path_label, 'r', encoding='utf-8') as f:
for line in f.readlines():
tmp = line.strip().split(' ')
if eval(tmp[-2]) < 10: continue
if tmp[-1] == '6': continue
tmp[-1] = emo2num[tmp[-1]]
label_list[tmp[0]] = [eval(i) for i in tmp[2:]]
data_transform = transforms.Compose([transforms.ToTensor()])
class ImageDataset(Dataset):
def __init__(self):
self.image = []
self.label = []
self.n_pos = 0
self.n_neg = 0
cnt = 0
for key in label_list:
# if cnt == 2000:break
# else:cnt += 1
self.image.append(key)
# img = show_bboxes(path_image + 'shocked_expression_190.jpg', [47, 111, 206, 142, 70.0982, 1])
if label_list[key][-1] == 1: self.n_pos += 1
elif label_list[key][-1] == 0:self.n_neg += 1
self.label.append(label_list[key][-1])
# print('\r{}'.format(cnt), end='')
# cnt += 1
print(self.n_pos, self.n_neg)
def __getitem__(self, item):
key = self.image[item]
img = show_bboxes(path_image + key, label_list[key]) # numpy.ndarray, (150, 96)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_PIL = Image.fromarray(img)
img_tensor = data_transform(img_PIL)
lab = torch.LongTensor([self.label[item]])
return img_tensor, lab
def __len__(self):
return self.n_pos+self.n_neg
def evaluate(dataloader):
model.eval()
total_acc, total_count = 0, 0
with torch.no_grad():
for i, (wave, label) in enumerate(dataloader):
wave, label = wave.cuda(), label.cuda()
predicted_label = model(wave)
# print(predicted_label.argmax(1))
# print(predicted_label.argmax(1))
# print(label)
total_acc += (predicted_label.argmax(1) == label.squeeze()).sum().item()
# print(total_acc)
total_count += label.size(0)
# print(total_count)
model.train()
return total_acc / total_count
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
model = Net()
BATCH_SIZE = 32
datafile = ImageDataset()
n_train = int(len(datafile) * 0.85)
split_train, split_valid = random_split(dataset=datafile, lengths=[n_train, len(datafile) - n_train])
train_dataloader = DataLoader(split_train, batch_size=BATCH_SIZE, shuffle=True)
valid_dataloader = DataLoader(split_valid, batch_size=BATCH_SIZE, shuffle=True)
print('Length of train set is {}, Length of valid set is {}'.format(len(split_train), len(split_valid)))
if __name__ == '__main__':
acc_min = 0.7070
if torch.cuda.is_available() == True:
print('Cuda is available!')
model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 学习率
criterion = nn.CrossEntropyLoss()
# scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=0.9)
losses = []
start_time = time.time()
for epoch in range(100): # 最大迭代次数
cnt = 0
for img, label in train_dataloader:
img, label = img.cuda(), label.cuda()
# print(img.size(), label.size())
out = model(img)
loss = criterion(out, label.squeeze())
losses.append(loss)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.25)
optimizer.step()
optimizer.zero_grad()
if (cnt+1) % 200 == 0:
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
acc_valid = evaluate(valid_dataloader)
print('当前代数:{},batch:{},平均训练集Loss:{:.4f},验证集精确度:{:.4f},Total time:{}m {}s'.format(epoch,
(cnt+1)/200,
sum(losses) / len(losses),
acc_valid, epoch_mins,
epoch_secs))
if acc_valid > acc_min:
acc_min = acc_valid
torch.save(model.state_dict(), 'model_image.pth')
print('Save model!')
# else:
# scheduler.step()
cnt += 1
plt.plot(losses)
plt.show()
小结
最近没时间做视频的情绪分类了,所以应该就这样吧


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









