







Redis的实际操作的相关命令,不同版本之间命令存在差异。
全部命令请查看https://redis.io/commands/
基础命令
连接客户端
#直接连接
> redis-cli
> auth #密码认证
#指定连接信息
> redis-cli -h host -p port -a password
keys命令
set
赋值
set key value
> set k b
ok
get
获取值
get key
> get k #获取存在的key
b
> get k1 #获取不存在的key
null
del
删除(多个)
del key [key…]
> del k #删除存在的key,删除成功
1
> del k1 #删除不存在的key,删除失败
0
keys
查找所有符合给定模式(pattern)的key
keys pattern
> keys * #匹配任意key, 即获取全部key
1) "1550289148972261376&8"
2) "1:follow"
3) "init:tender"
> keys init* #匹配init开头的key
1) "init:tender"
> keys *tender #匹配tender结尾的key
1) "init:tender"
persist
移除key的过期时间
当过期时间移除成功时,返回 1 。 如果 key 不存在或 key 没有设置过期时间,返回 0 。
persist key
> persist k
1
> persist kk
0
exists
检查key是否存在
exists key
> exists k #存在返回1
1
> exists k1 #不存在返回0
0
expire
设置key过期时间,单位秒
expire key seconds
> expire k 30 #key存在,设置成功返回1
1
> expire kr 30 #key不存在,设置失败返回0
0
pexpire
设置key过期时间,单位毫秒
pexpire key milliseconds
> pexpire k1 30000
1
ttl
获取key的过期时间
ttl key
> ttl k
-1 #没有设置过期时间
> ttl k
23932 #秒
move
将当前数据库的key移动到指定的数据库db中
move key db
> move k 1 #成功
1
randomkey
从当前数据库随机返回一个key
> randomkey
k
rename
修改key的名称
rename key newkey
> rename k3 k
OK
renamenx
仅当newkey不存在时,在将key更名为newkey
renamenx key newkey
> renamenx k3 k
1
type
返回key的数据类型
type key
> type k3
string
scan
迭代数据库中的键,
scan是一个基于游标的迭代器,每次被调用后,都会向用户返回新的游标,用户在下次迭代时需要以新游标作为scan命令的游标参数,以此来延续之前的迭代过程。
scan命令返回一个包含两个元素的数组,第一个元素是用于进行下一次迭代的的新游标,而第二个元素是一个数组,这个数组中包含了所有被迭代的元素,如果新游标返回0代表迭代已结束。
相关子命令:
- sscan:迭代集合键中的元素
- hscan:迭代哈希键中的键值对
- zscan:迭代有序集合中的元素,包含元素成员和分值
scan key cursor [match pattern] [count count]
- cursor:游标
- match:匹配模式
- count:指定从数据集里返回多少条数据,默认10
> scan 0 # 以0开始
7 # 返回新游标
ceshi
phone
hset
names
123
2022
zset
zset2
zset1
zset3
> scan 0 count 1 # 以0开始,返回1个
12 # 返回新游标
ceshi
> scan 12 count 1 # 以12开始
10 # 返回新游标
phone
> scan 10 # 以10开始
0 # 返回0代表迭代结束
hset
names
123
2022
zset
zset2
zset1
zset3
字符串String
set
get
getrange
返回key的字符串的子字符串(截取)
getrange key start end
> set k 123456 #length=6
1
> getrange k 4 5 #从第四位截取到尾
56
> getrange k 1 -1 #从第一位截取到尾
23456
> getrange k -3 -1
456
substr
返回截取后的指定key的字符串值
同:getrange
substr key start end
> substr s 0 1
22
> get s
22ss
> substr s -3 -1
2ss
getset
将key设置value,并返回key的旧值
getset key value
> getset k aaaa
123456
getbit
获取key的字符串值的指定偏移量的位(bit)
getbit key offset
> getbit k 23
1
# 01100001 01100001 01100001 01100001 = aaaa
setbit
设置key的字符串上指定偏移量的位
setbit key offset value
- value:0/1
> setbit k 3 1
1
# 011 0 0001 01100001 01100001 01100001 -->
# 011 1 0001 01100001 01100001 01100001
setex
设置key的值和过期时间
setex key seconds value
> setex s 30 sdfg
OK
setnx
只有当可以不存在时才设置key
setnx key value
> setnx s qq #key不存在
1
> setnx s qq #key存在
0
setrange
将key值中从指定偏移量上开始的值覆盖
setrange key offset value
> get s
qq
> setrange s 1 123456
7
> get s
q123456
strlen
返回key的字符串的长度
strlen key
> get s
q123456
> strlen s
7
mset
同时设置一个或多个k-v对
mset key value [key value …]
> mset f f g g
OK
msetnx
同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
msetnx key value [key value …]
> msetnx f f k k #f存在
0
> msetnx k k l l
1
psetex
和setnx类似,但是时间单位是毫秒
> psetex p 30000 p
OK
incr
将key的数字值+1
incr key
> set s 123
OK
> incr s
124
incrby
对key的数字值进行增加值
incrby key incrment
> incrby s 12 #加
136
> incrby s -12 #减
124
incrbyfloat
对key的数字值增加浮点值
注:对key进行incrbyfloat后不能在进行incr/decr, incrby/decrby
incrbyfloat key float
> incrbyfloat s 1.2
125.2
> incrbyfloat s -1.2
124
> incrbyfloat s 1.23333333333333333333333333333
125.23333333333333
> incrbyfloat s -1.23333333333333333333333333333
123.76666666666667
> incrby s 2
ERR value is not an integer or out of range
decr
将key的数字值减1
decr key
> set s 23
OK
> decr s
22
decrby
将key的数字值减去指定值
decrby key
> decrby s 1 #减
21
> decrby s -1 #加
22
append
如果key存在并且值是字符串,append将指定的value追加到该key原来的值的末尾
append key value
> append s ss
4
> get s
22ss
哈希Hash
Redis hash 是一个string类型的field(字段)和value(值)的映射表,hash特别适合用于存储对象。
每个hash可以存储232-1键值对(40多亿)
部分string的命令加上前缀h就是hash的命令
hset
对key的field字段赋值
hset key field value
> hset h name 123
1
> hgetall h
name #field
123 #value
hmset
对key的多个field赋值
hmset key field value [field value …]
> hmset h name 于寅星 sex 男
OK
> hgetall h
name #field
aaa #value
sex #field
男 #value
hsetnx
只有字段field不存在时,才将key的field赋值
hsetnx key field value
> hsetnx h sex 4
0
> hsetnx h sex1 4 #设置成功
1
> hkeys h
name
sex
addr
sex1 #增加的field
hget
获取key的field值
hget key field
> hget h name
aaa
hmget
获取key中的多个field字段的值value
hmget key field [field…]
> hmget h name sex
aaa
1
hgetall
获取整个key的全部field
hgetall key
> hgetall h
name #field
aaa #value
sex #field
男 #value
hdel
删除key中的部分字段field
hdel key field [field…]
> hdel h sex #删除成功,返回1
1
> hgetall h
name
于寅星
hexists
检查key中field存不存在
hexists key field
> hexists h name
1
hkeys
获取该key的哈希表中的所有字段field
hkeys key
> hmset h name aaa sex 1 addr 地球
OK
> hkeys h
name
sex
addr
hlen
获取key中的field数量
hlen key
> hkeys h #获取所有的field
name
sex
addr
> hlen h #field数量
3
hincrby
为key的field字段的整数值增加上指定的增量increment
hincrby key field increment
> hget h sex
3
> hincrby h sex -1
2
hincrbyfloat
为key的field字段的整数值增加上指定的浮点增量increment
注:hincrbyfloat执行后无法在执行hincrby
hincrbyfloat key field increment
> hincrbyfloat h sex 1.2
3.2
> hincrby h sex 1.2
ERR value is not an integer or out of range
> hincrby h sex 1
ERR hash value is not an integer
hvals
获取key中的所有field的值
hvals key
> hgetall h
name
aaa #value
sex
3.2 #value
addr
地球 #value
sex1
4 #value
> hvals h
aaa
3.2
地球
4
hscan
用于迭代hash表中的键值对,可用于redis扫描
hscan key cursor [match pattern] [count count]
- cursor:游标
- match:匹配模式
- count:指定从数据集里返回多少条数据,默认10
> hscan hset 0
0
a
a
b
b
c
c
d
d
e
e
> hscan hset 0 match a*
0
a
a
> hscan hset 0 match a* count 1
0
a
a
> hmset hset ab ab ac ac bc bc abc abc
OK
> hscan hset 0 match a*
0
a
a
ab
ab
ac
ac
abc
abc
> hscan hset 0 match a* count 1
0
a
a
ab
ab
ac
ac
abc
abc
列表List
redis列表是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边),
一个列表可以包含232-1个元素(约40多亿个)
lpush
向列表的头部添加元素(往左插入),成功返回列表长度
lpush key value [value…]
> lpush list a #如果list的key已存在且数据类型不是List,就会报错
1
> lpush list b
2
> lpush list c d
4
lpushx
向已存在的list中添加元素,不存在则操作无效,操作成功返回列表长度
lpushx key value
> lpushx list e #存在
5
> lpushx list1 e #不存在
0
lrange
获取列表指定范围的元素
lrange key start end
> lrange list 0 -1 #获取全部
e
d
c
b
a
> lrange list 2 2 #指定范围
c
> lrange list 2 9 #下限超过列表长度时返回全部
c
b
a
> lrange list -3 -1 #从倒数第3位到倒数第1位
c
b
a
lset
设置列表中指定位置上的元素
lset key index value
> lset list 4 s
OK
> lrange list 0 -1
e
d
c
b
s #a -> s
lpop
移除并获取列表的第一个元素
lpop key
> lrange list 0 -1
e
d
c
b
s
> lpop list #移除第一个
e
> lrange list 0 -1
d
c
b
s
lindex
通过索引获取列表中的元素
lindex key index
> lrange list 0 -1
s
a
d
b
s
> lindex list 2
d
linsert
在列表的pivot元素前/后插入元素,只会在从头部(左边)开始检索到的第一个元素前后插入,pivot不存在则插入失败
linsert key before|after pivot value
> lrange list 0 -1
s
a
d
b
s
> linsert list before s in
6
> lrange list 0 -1
in #插入
s #被检索到的元素
a
d
b
s
> linsert list after s ina
7
> lrange list 0 -1
in
s #被检索到的元素
ina #插入
a
d
b
s
lrem
移除列表元素
lrem key count value
根据参数count的值,移除列表中与value相同的元素
- count > 0:从表头开始向表尾搜索,移除与value相等的元素,移除的数量为count
- count < 0:从表尾开始向表头搜索,移除与value相等的元素,移除的数量为count的绝对值
- count = 0:移除表中所有与value相等的元素
> lrange list 0 -1
c #1.被移除
c #2.被移除
d
c
s
a
c
d
c
b
s
a
> lrem list 2 c
2
> lrange list 0 -1
d
c
s
a
c
d
c
b
s
a
> lrange list 0 -1
d
c
s
a
c
d
c #1.被移除
b
s
a
> lrem list -1 c
1
> lrange list 0 -1
d
c
s
a
c
d
b
s
a
> lrange list 0 -1
d
c #被移除
s
a
c #被移除
d
b
s
a
> lrem list 0 c
2
> lrange list 0 -1
d
s
a
d
b
s
a
ltrim
对列表元素进行截取
ltrim key start end
> lrange list 0 -1
d
s
a
d
b
s
a #被舍弃
> ltrim list 0 5
OK
> lrange list 0 -1 #结果
d
s
a
d
b
s
> ltrim list 0 -1 #截取全部,等于脱裤子放屁
OK
> lrange list 0 -1
d #被舍弃
s
a
d
b
s
> ltrim list -5 -1 #从倒数第5位开始截取到倒数第1位
OK
> lrange list 0 -1
s
a
d
b
s
llen
获取列表长度
llen key
> lrange list 0 -1
s
a
d
b
s
> llen list
5
rpop
移除列表的最后一个元素,并返回被移除的元素
rpop key
> rpop list
s
rpoplpush
移除列表的最后一个元素,并将被移除的这个元素添加到另一个列表的头部并返回
rpoplpush sourcekey targetkey
> lrange list 0 -1
in
s
ina
a
d
b #被移除
> rpoplpush list list1
b #被返回
> lrange list 0 -1
in
s
ina
a
d
> lrange list1 0 -1
b #被添加到list1
rpush
在列表尾部添加元素,返回列表长度
rpush key value [value…]
> lrange list1 0 -1
b
> rpush list1 c d
3
> lrange list1 0 -1
b
c
d
rpushx
为已存在的列表添加值
rpushx key value
> rpushx list1 f #成功
4
> rpushx list2 a #失败
0
阻塞操作
列表被阻塞时收到的命令都会在解除阻塞后执行
blpop
移除列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或者发现可弹出的元素为止
返回两个元素:
- 弹出元素所在的key
- 弹出的元素
blpop key timeout
> blpop list list1 10 #只会执行第一个key
list #key
s #弹出元素
> blpop list2 10 #1. list2不存在,阻塞10s
> rpushx list2 a #2. 10秒后执行
null #1.返回nil
0 #2.插入失败
brpop
移除列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或者发现可弹出的元素为止
返回两个元素:
- 弹出元素所在的key
- 弹出的元素
brpop key timeout
> lrange list 0 -1
in
s
ina
a
d #被弹出
> brpop list 10
list #key
d #弹出的元素
> brpop list1 10
list1 #key
f #弹出的元素
> brpop list2 10
null #阻塞10s后返回nil
brpoplpush
移出队列1的最后一个元素,并将该元素插入到另一个队列2的头部,如果队列1不存在改元素,会阻塞队列1直到等待超时或者发现可弹出的元素为止,返回被弹出的元素
brpoplpush key1 key2 timeout
> brpoplpush list list1 10
a #返回被弹出的元素
集合Set
redis的set是string类型的无序集合,集合成员是唯一的,不能出现重复的数据。
redis中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1),
集合的数量也是232-1
sadd
向集合添加一个或者多个元素,key不存在时会创建key,返回集合长度
sadd key member [member…]
> sadd set 1 2 3
3
scard
获取集合成员数量
scard key
> scard set
3
sdiff
返回第一个集合与其他集合元素的差异
sdiff key1 [key2…]
#set={0,1,2}
> sadd set1 2 3 4 5
4
> sdiff set set1
0
1
sdiffstore
将给定所有集合的差集并存储在指定集合中,返回差异元素的数量
sdiffstore targetset key…
#set={a,b,c}
#set2={c,d}
> sdiffstore set3 set set2
2
> smembers set3
a
b
sinter
返回给定集合的交集
sinter key1 key2…
#set={a,b,c}
#set1={b,c,d}
> sinter set set1
c
b
sinterstore
获取给定集合的交集,并存储在给定集合中,返回交集的元素数量
sinterstore targetkey key1 key2…
#set={a,b,c}
#set1={b,c,d}
> sinterstore set3 set set1
2
> smembers set3
b
c
sunion
获取所有集合的并集
sunion key…
> sunion set set1
b
a
c
e
f
sunionstore
将所有集合的并集存入一个新的集合中,返回新集合的长度
sunionstore target key…
> sunionstore set4 set set1
5
> smembers set4
b
a
c
e
f
sismember
判断指定值是否是集合的成员
sismember key value
> smembers set3
b
c
> sismember set3 c
1
> sismember set3 d
0
smembers
获取集合中的所有成员
smembers key
> smembers set3
b
c
smove
将member元素从一个集合移动到另一个集合
smove key target member
> smembers set3
b
c
> smembers set2
c
ej
f
> smove set2 set3 f #将set2中的f移动到set3
1
> smembers set3
b
c
f
spop
随机移出集合中的一个元素并返回
spop key
> smembers set3
b
c
f
> spop set3
c
> smembers set3
b
f
sramdmember
也是用于随机返回集合中的元素,可选的参数count
- count > 0:
- count小于集合长度:返回一个包含count个元素的数组,数组中的元素各不相同
- count大于等于集合长度:返回整个集合
- count < 0:返回一个数组数组中的元素可能会重复出现多次,而数组的长度为count的绝对值
该命令与spop类似,但是spop会对原集合进行修改,srandmember仅仅返回随机元素,不对原集合进行修改
srandmember key [count]
> srandmember set3 3
b
f
> srandmember set3 1
b
> srandmember set3 -3
f
b
b
srem
移除集合中的一个或多个元素
srem key member…
> srem set3 f
1
sscan
迭代set集合中的成员,sscan继承自scan,返回新游标和数组列表
SSCAN key cursor [MATCH pattern] [COUNT count]
> sscan set1 0
0
b
e
c
f
有序集合ZSet(sorted set)
与集合一样,也是string类型的集合,且不允许重复。
不同的是每一个元素都会关联一个double的分数,redis正是通过分数来为集合中的元素进行排序。
有序集合的元素是唯一的,但是分数却可以重复。
zadd
向有序集合添加一个或多个成员,或者更新一个已存在的成员的分数
返回被成功添加的成员的数量,不包括更新、已存在的成员
zadd key score1 member1 [score2 member2 …]
> zadd zset 1 a
1
> zadd zset 1 a 2 b 3 c
2
zcard
获取有序集合的成员数
zcard key
> zcard zset
3
zcount
计算在有序集合中指定分数范围内的成员数量
zcount key min max
范围: m i n ≤ s c o r e ≤ m a x 范围:min \le score \le max 范围:min≤score≤max
> zrange zset 0 -1 withscores
a
1.1000000000000001
b
2.1000000000000001
c
3
> zcount zset 2 3
2
zincrby
增加指定成员的分数并返回
zincrby key increment member
> zrange zset 0 -1 withscores
a
1.1000000000000001
b
2.1000000000000001
c
3
> zincrby zset -1 c
2
> zrange zset 0 -1 withscores
a
1.1000000000000001
c
2
b
2.1000000000000001
zinterstore
计算给定一个或多个有序的集合的交集,其中给定集合的数量必须numkeys指定(即集合的数量必须与numkeys相等),并将该交集存储到指定集合。
默认情况下,结果集中的某个成员的分数值是所有所有给定集合中该成员的分数之和
zinterstore target numkeys key… [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
- weights 权重,设置权重后每个成员的分数要乘以权重
- aggregate 最终分数获取规则
- sum 求总和,默认
- min 取最小
- max 取最大
> zadd zset1 2 b 3 c 4 d
3
> zinterstore zset2 2 zset zset
3
> zrange zset2 0 -1 withscores
a
2.2000000000000002
c
4
b
4.2000000000000002
> zinterstore zset2 2 zset zset weights 1 2
3
> zrange zset2 0 -1 withscores
a
3.3000000000000003
c
6
b
6.3000000000000007
> zinterstore zset2 2 zset zset weights 1 2 aggregate min
3
> zrange zset2 0 -1 withscores
a
1.1000000000000001
c
2
b
2.1000000000000001
zlexcount
计算在有序集合中指定字典区间的成员数量
zlexcount key min max
min/max 格式:
- [ min/max:表示闭区间,返回值包含min/max,[min、[max 可以用 -、+代替
- [ min/max:表示开区间,返回值不包含min/max
> zrange zset2 0 -1
a
c
b
> zlexcount zset2 - +
3
> zlexcount zset2 [a [b
1
> zlexcount zset2 [a [c
3
> zlexcount zset2 [a (c
1
> zlexcount zset2 [a (b
1
> zlexcount zset2 (a (b
0
zrange
按从小到大的顺序,返回指定区间内的成员
zrange key start end [withscores]
- withscores:展示分数
> zrange zset2 0 -1 withscores
a
1.1000000000000001
c
2
b
2.1000000000000001
> zrange zset2 0 1 withscores
a
1.1000000000000001
c
2
zrevrange
按从大到小的顺序,获取指定区间内的成员
zrevrange key start end [withscores]
> zrevrange zset2 0 -1 withscores
b
2.1000000000000001
c
2
a
1.1000000000000001
zrangebylex
返回集合中指定区间内的成员
zrangebylex key min max [ limit offset count ]
offset:起始位置
count:数量
> zrangebylex 2022 - +
3
2
1
asd
> zrangebylex 2022 - + limit 1 2
2
1
> zadd phone 0 13100111100 0 13110114300 0 13132110901
3
> zadd phone 0 13200111100 0 13210414300 0 13252110901
3
> zadd phone 0 13300111100 0 13310414300 0 13352110901
3
> zrangebylex phone [132 [133
13200111100
13210414300
13252110901
> zrangebylex phone [132 (133
13200111100
13210414300
13252110901
> zrangebylex phone [132 (134
13200111100
13210414300
13252110901
13300111100
13310414300
13352110901
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
6
> zrangebylex names [a [b #空
> zrangebylex names [A [B
Aidehua
Aimini
zrangebyscore
返回指定分数区间的成员,默认闭区间,可通过添加 ( 符号设置开区间
zrangebyscore key min max [withscores] [limit offset count]
> zrange zset1 0 -1 withscores
b
2
c
3
d
4
> zrangebyscore zset1 (2 4
c
d
> zrangebyscore zset1 2 4 limit 0 1
b
> zrangebyscore zset1 2 4 withscores limit 0 1
b
2
zrank
按从小到大的顺序,返回集合中指定成员的索引(不是分数)
zrank key member
> zrange zset1 0 -1
b #0
c #1
d #2
> zrank zset1 b
0
> zrank zset1 c
1
> zrank zset1 d
2
zrevrank
按从大到小的顺序,返回集合中指定成员的索引
zrevrank key member
> zrevrange zset1 0 -1 withscores
i #0
9
h #1
8
g #2
7
f #3
6
e
5
d
4
> zrevrank zset1 f
3
zrem
移除集合中指定成员
zrem key member…
> zrem zset1 b
1 #成功
> zrem zset1 b
0 #失败
zremrangebylex
移除指定范围内的所有成员
zremrangebylex key min max
> zremrangebylex zset1 [f [g
2
zremrangebyrank
移除指定排名内的所有成员,返回实际移除的数量
zremrangebyrank key start end
> zremrangebyrank zset1 2 3
1
> zremrangebyrank zset1 1 3
1
> zadd zset1 2 b 3 c 4 d 5 e 6 f 7 g
5
> zremrangebyrank zset1 0 2
3
zremrangebyscore
移除指定分数区间的所有成员,返回实际移除的数量
zremrangebyscore key min max
> zremrangebyscore zset1 2 3
2
zscore
获取指定成员的score
zscore key member
> zscore zset1 f
6
zunionstore
获取指定集合的并集,并生成新集合,返回新集合的长度
默认情况下,新集合的成员分数是该成员分数之和
> zrange zset 0 -1 withscores
a
1.1000000000000001
c
2
b
2.1000000000000001
> zrange zset1 0 -1 withscores
d
4
e
5
f
6
g
7
h
8
i
9
> zunionstore zset3 2 zset zset1
9
> zrange zset3 0 -1 withscores
a
1.1000000000000001
c
2
b
2.1000000000000001
d
4
e
5
f
6
g
7
h
8
i
9
zdiff
获取第一个集合与其他集合的差集
zdiff numkey key… [withscores]
> ZDIFF 2 zset1 zset2 WITHSCORES
1) "three"
2) "3"
zdiffstore
获取第一个集合与其他集合的差集,并生成新集合
zdiffstore target numkey key…
> ZDIFFSTORE out 2 zset1 zset2
(integer) 1
> ZRANGE out 0 -1 WITHSCORES
1) "three"
2) "3"
zinter
获取第一个集合与另外集合的交集
zinter numkey key… [weights weight…] [aggregate sum|min|max] [withscores]
- numkey:需指定集合数量
- weights:权重,使用权重时,各集合中的成员得分需要乘以权重
- aggregate :得分规则,求和 | 最小 | 最大
- withscores:该命令用于展示成员得分
redis:6379> zrange zset1 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
redis:6379> zrange zset2 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis:6379> ZINTER 2 zset1 zset2 WITHSCORES
1) "one"
2) "2"
3) "two"
4) "4"
zinterstore
获取第一个集合与其他集合的交集,并将结果存储在新的集合,其他命令的用法与zinter一致。
zinterstore target numkey key… [weights weight…] [aggregate sum|min|max] [withscores]
redis:6379> zrange zset1 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
redis:6379> zrange zset2 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis:6379> ZINTERSTORE out 2 zset1 zset2 WEIGHTS 2 3
(integer) 2
redis:6379> ZRANGE out 0 -1 WITHSCORES
1) "one"
2) "5"
3) "two"
4) "10"
zintercard
获取第一个集合与其他集合的交集,返回交集的成员数量
zintercard numkey key… [limit count]
- limit : 返回的数量上限
redis:6379> zrange zset1 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
redis:6379> zrange zset2 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis:6379> ZINTERCARD 2 zset1 zset2
(integer) 2
redis:6379> ZINTERCARD 2 zset1 zset2 LIMIT 1
(integer) 1
zpopmax
弹出集合中得分最高的成员
zpopmax key [count]
- count :弹出数量
redis:6379> zrange myzset 0 -1 withscores
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
7) "four"
8) "4"
9) "five"
10) "5"
redis:6379> zpopmax myzset 2
1) "five"
2) "5"
3) "four"
4) "4"
zpopmin
与zpopmax相反,弹出得分最小的成员
zpopmin key [count]
redis:6379> zpopmin myzset 2
1) "one"
2) "1"
3) "two"
4) "2"
zmpop
该命令与zpopmin、zpopmax相似,不同之处在于,zmpop支持多个key
ZMPOP numkeys key [key …] MIN | MAX [COUNT count]
- min|max:取最小|取最大
- count:弹出数量
ZMPOP 2 myzset myzset2 MIN COUNT 10
1) "myzset2"
2) 1) 1) "four"
2) "4"
2) 1) "five"
2) "5"
3) 1) "six"
2) "6"
zscan
迭代有序集合中的元素,返回的也是有序集合元素,包含成员和分值。
ZSCAN key cursor [MATCH pattern] [COUNT count]
> zscan zset3 0
0
a
1.1000000000000001
c
2
b
2.1000000000000001
d
4
e
5
f
6
g
7
h
8
i
9
> zscan zset3 0 count 1
0
a
1.1000000000000001
c
2
b
2.1000000000000001
d
4
e
5
f
6
g
7
h
8
i
9
阻塞操作
bzmpop
弹出有序集合中指定数量的成员,没有元素时会阻塞直到超时或者有可弹出的元素为止
BZMPOP timeout numkeys key [key …] MIN | MAX [COUNT count]
- timeout:超时时间,单位秒
- numkeys:指定key的数量
- min | max :取最小|最大
- count:指定弹出数量
bmpopmin
相当于:
BZMPOP timeout numkeys key [key …] MIN [COUNT count]
bzpopmax
相当于:
BZMPOP timeout numkeys key [key …] MAX [COUNT count]
开发规范
阿里云Redis开发规范
从一下几个方面说明,减少使用redis过程中带来的问题
- 一、键值设计
- 1、key名设计
- 2、value设计
- 命令使用
- 客户端使用
- 相关工具
- 删除bigkey
一、键值设计
1、key设计
- (1)【建议】:可读性和可管理性
以业务名(数据库名)为前缀(防止key冲突),用冒号分隔,比如业务:表名:id
ugc:video:1
- (2)【建议】:简洁性
保证语义的前提下,尽量控制key的长度,当key较多时,内存占用也不容易忽视
user:{uid}:friends:messages:{mid}简化为u:{uid}:fr:m:{mid}
- (3)【强制】:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符。
详细解析
2、value设计
- (1)【强制】:拒绝bigkey(防止网卡流量,慢查询)
string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
反例:一个包含200万个元素的list。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会不出现在慢查询中(latency可查)),查找方法和删除方法
详细解析
- (2)(推荐):选择合适的数据类型
例如:实体类型(要合理控制和使用数据结构内存编码优化配置,例如ziplist,但也要注意节省内存和性能之间的平衡)
反例:
set user:1:name tom
set user:1:age 19
set user:1:favor football
正例:
hmset user:1 name tom age 19 favor football
3、【推荐】:控制key的生命周期,redis不是垃圾桶
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期),不过期的数据重点关注idletime。
二、命令使用
1、【推荐】:O(N)命令关注N的数量
例如hgetall,lrange,smembers,zrange,sinter等并非不能使用,但是需要明确N的值,有遍历的需求可以使用hscan,sscan,zscan代替。
2、【推荐】:禁用命令
线上禁止使用keys,flushall,flushdb等命令,通过redis的rename机制禁掉命令,或者使用scan的方式渐进处理。
3、【推荐】:合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务使用多数据库还是单线程处理,会有干扰。
4、【推荐】:使用批量操作提高效率
原生命令:如mget,mset
非原生命令:如可以使用pipeline提高效率
但要注意控制一次批量操作的元素个数(例如500以内,实际也是和元素字节数有关)
但注意两者不同:
- 原生是原子操作,pipeline是非原子操作。
- pipeline可以打包不同的命令,原生做不到
- pipeline需要客户端和服务端同时支持。
5、【建议】:redis事务功能较弱(不支持回滚),不建议过多使用
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上(可以使用hashtag功能解决)
6、【建议】:redis集群版本在使用lua上有特殊要求
- 1.所有key都应该由 KEYS 数组来传递,redis.call/pcall 里面调用的redis命令,key的位置,必须是KEYS array, 否则直接返回error,“-ERR bad lua script for redis cluster, all the keys that the script uses should be passed using the KEYS array”
- 2.所有key,必须在1个slot上,否则直接返回error, “-ERR eval/evalsha command keys must in same slot”
7、【建议】:必要情况下使用monitor命令时,注意不要长时间使用
三、客户端使用
1、【推荐】:应避免多个应用使用同一个Redis实例
正例:不相干的业务拆分,公共数据做服务化。
2、【推荐】:使用带有连接池的数据库
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
执行命令如下:
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
//具体的命令
jedis.executeCommand()
} catch (Exception e) {
logger.error("op key {} error: " + e.getMessage(), key, e);
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}
下面是JedisPool优化方法的文章:
3、【建议】:熔断
高并发下建议客户端添加熔断功能(例如netflix hystrix)
4、【推荐】:密码
设置合理的密码,如有必要可以使用SSL加密访问(阿里云Redis支持)
5、【建议】:内存淘汰策略
根据自身业务,选好maxmemory-policy(最大内存淘汰策略),设置好过期时间。
默认策略是volatile-lru,即超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
其他策略如下:
- volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰;
- volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰;
- volatile-random:从已设置过期时间的数据集中随机挑选数据淘汰;
- allkeys-lru:从所有数据中选择最近最少使用的数据淘汰;
- allkeys-random:从所有数据中选择任意数据淘汰;
- no-enviction**:**当内存不足时,新写入数据会报错;
四、相关工具
1、【推荐】:数据同步
redis间数据同步可以使用:redis-port
2.【推荐】:big key搜索
3.【推荐】:热点key寻找(内部实现使用monitor,所以建议短时间使用)
阿里云Redis已经在内核层面解决热点key问题。
五、附录:删除bigkey
- 下面操作可以使用pipeline加速。
- redis 4.0已经支持key的异步删除,欢迎使用
1、Hash删除: hscan + hdel
public void delBigHash(String host, int port, String password, String bigHashKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<Entry<String, String>> scanResult = jedis.hscan(bigHashKey, cursor, scanParams);
List<Entry<String, String>> entryList = scanResult.getResult();
if (entryList != null && !entryList.isEmpty()) {
for (Entry<String, String> entry : entryList) {
jedis.hdel(bigHashKey, entry.getKey());
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigHashKey);
}
2. List删除: ltrim
public void delBigList(String host, int port, String password, String bigListKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
long llen = jedis.llen(bigListKey);
int counter = 0;
int left = 100;
while (counter < llen) {
//每次从左侧截掉100个
jedis.ltrim(bigListKey, left, llen);
counter += left;
}
//最终删除key
jedis.del(bigListKey);
}
3. Set删除: sscan + srem
public void delBigSet(String host, int port, String password, String bigSetKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<String> scanResult = jedis.sscan(bigSetKey, cursor, scanParams);
List<String> memberList = scanResult.getResult();
if (memberList != null && !memberList.isEmpty()) {
for (String member : memberList) {
jedis.srem(bigSetKey, member);
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigSetKey);
}
4. SortedSet删除: zscan + zrem
public void delBigZset(String host, int port, String password, String bigZsetKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<Tuple> scanResult = jedis.zscan(bigZsetKey, cursor, scanParams);
List<Tuple> tupleList = scanResult.getResult();
if (tupleList != null && !tupleList.isEmpty()) {
for (Tuple tuple : tupleList) {
jedis.zrem(bigZsetKey, tuple.getElement());
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigZsetKey);
}
应用场景
缓存
例如:
热点数据缓存,对象缓存,劝业缓存,可以提升热点数据的访问数据
数据共享分布式
String类型
redis是分布式的独立服务器,可以在多个应用之间共享。
例如:分布式session
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
分布式锁
String类型,setnx方法,只有不存在时才能添加成功。redis原生的setnx方法是不能直接添加过期时间,
推荐:可通过三方工具或者自己封装方法(setnx后紧跟着expire)实现锁过期自动释放,避免死锁
public static boolean getLock(String key) {
Long flag = jedis.setnx(key, "1");
if (flag == 1) {
jedis.expire(key, 10);
}
return flag == 1;
}
public static void releaseLock(String key) {
jedis.del(key);
}
public boolean setIfAbsent(String key, T value, Long timeout, TimeUnit unit) {
try {
boolean flag;
if (timeout != null && unit != null) {
flag = this.redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit);
} else {
flag = this.redisTemplate.opsForValue().setIfAbsent(key, value);
}
return flag;
} catch (Exception var7) {
log.warn(var7.getMessage(), var7);
return false;
}
}
全局id
int型,利用原子性
incr:每次加1;
incrby:自定义增量;
例如:incrby userId 1000 分库分表的场景,一次性拿一段
public Long incr(String key, long delta) {
try {
return this.redisTemplate.opsForValue().increment(key, delta);
} catch (Exception var5) {
log.warn(var5.getMessage(), var5);
return 0L;
}
}
public Long incr(String key) {
try {
return this.redisTemplate.opsForValue().increment(key);
} catch (Exception var3) {
log.warn(var3.getMessage(), var3);
return 0L;
}
}
计数器
int型,
incr:每次加1
例如:文章的阅读量,点赞数,这种数据一般允许一定延时,在定时同步到数据库。
public Long incr(String key) {
try {
return this.redisTemplate.opsForValue().increment(key);
} catch (Exception var3) {
log.warn(var3.getMessage(), var3);
return 0L;
}
}
限流
int型,incr方法
例如:以访问者的ip和其他关键信息作为key,访问一次增加一次计数,达到一定次数返回false
位统计
String类型或者bitmap,字符是以8位二进制存储的,所以String和bit位数字之间可以相互转换
setbit、getbit、bitcount等
set k1 a
setbit k1 6 1
setbit k1 7 0
get k1
/* 6 7 代表的a的二进制位的修改
a 对应的ASCII码是97,转换为二进制数据是01100001
b 对应的ASCII码是98,转换为二进制数据是01100010
因为bit非常节省空间(1 MB=8388608 bit),可以用来做大数据量的统计。
*/
例如:在线用户统计,留存用户统计,一般是将用户表的id设置成自增主键,然后将主键对应的bit为设置成1,这样就能统计到用户数量,雪花id时暂不好处理设置bit为
setbit onlineusers 01
setbit onlineusers 11
setbit onlineusers 20
支持按位与,按位或等操作
BITOP AND destkey key[key...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。
BITOP OR destkey key[key...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey 。
BITOP XOR destkey key[key...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。
BITOP NOT destke ykey ,对给定 key 求逻辑非,并将结果保存到 destkey 。
计算出7天都在线的用户(按位与)
BITOP "AND" "7_days_both_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users"
购物车
String 或hash。所有String可以做的hash都可以做。
hincrby:可以给hash表中执行对象中的字段加减值。
hgetall:获取全部字段
hlen:获取字段数量
hdel:删除字段
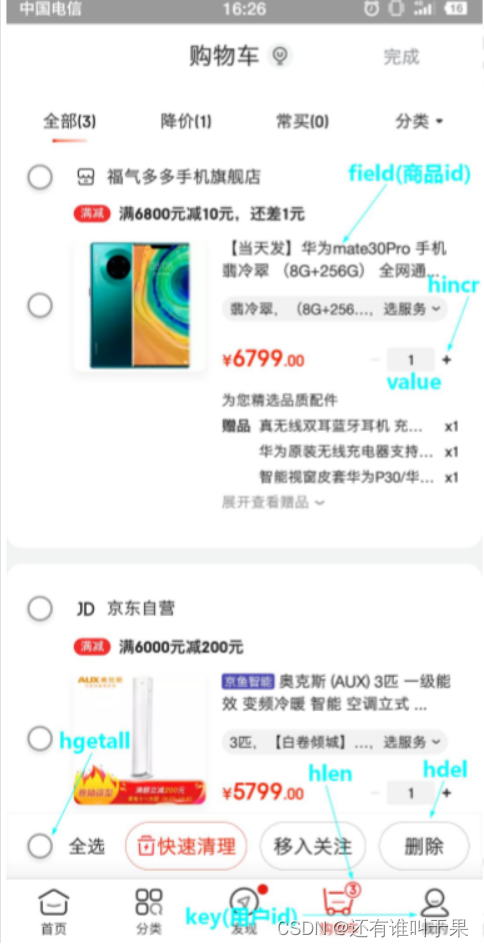
- key:用户id;field:商品id;value:商品数量。
- +1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen。
用户消息时间线timeline
list类型,双向链表,直接作为时间线插入即可,插入有序。
消息队列
List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
- blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
上面的操作。其实就是java的阻塞队列。学习的东西越多。学习成本越低
- 队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
- 栈:先进后出:rpush brpop
抽奖
set类型
spop:
随机移出集合中的一个元素并返回
点赞,签到,打卡
假如上面的微博ID是t1001,用户ID是u3001
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
- 点赞了这条微博:sadd like:t1001 u3001
- 取消点赞:srem like:t1001 u3001
- 是否点赞:sismember like:t1001 u3001
- 点赞的所有用户:smembers like:t1001
- 点赞数:scard like:t1001
是不是比数据库简单多了。
商品标签
set类型

老规矩,用 tags:i5001 来维护商品所有的标签。
- sadd tags:i5001 画面清晰细腻
- sadd tags:i5001 真彩清晰显示屏
- sadd tags:i5001 流程至极
商品筛选
set类型
// 获取差集
sdiff set1 set2
// 获取交集(intersection )
sinter set1 set2
// 获取并集
sunion set1 set2
假如:iPhone11 上市了
sadd brand:apple iPhone11
sadd brand:ios iPhone11
sad screensize:6.0-6.24 iPhone11
sad screentype:lcd iPhone 11
赛选商品,苹果的、ios的、屏幕在6.0-6.24之间的,屏幕材质是LCD屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd
用户关注,推荐模型
set类型
follow 关注 fans 粉丝
相互关注:
- sadd 1:follow 2
- sadd 2:fans 1
- sadd 1:fans 2
- sadd 2:follow 1
我关注的人也关注了他(取交集):
- sinter 1:follow 2:fans
可能认识的人:
- 用户1可能认识的人(差集):sdiff 2:follow 1:follow
- 用户2可能认识的人:sdiff 1:follow 2:follow
排行榜
zset类型
id 为6001 的新闻点击数加1:
zincrby hotNews:20190926 1 n6001
获取今天点击最多的15条:
zrevrange hotNews:20190926 0 15 withscores















 5860
5860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









