






 本文介绍了在使用Jupyter读取CSV文件时遇到的两个常见问题:1) 文件名包含中文导致的初始化失败问题,解决方案是避免使用中文命名;2) 文件编码错误引发的解码异常,解决方法包括指定读取时的编码格式或重新以UTF-8格式保存文件。通过这些方法,可以有效解决文件读取过程中的编码问题。
本文介绍了在使用Jupyter读取CSV文件时遇到的两个常见问题:1) 文件名包含中文导致的初始化失败问题,解决方案是避免使用中文命名;2) 文件编码错误引发的解码异常,解决方法包括指定读取时的编码格式或重新以UTF-8格式保存文件。通过这些方法,可以有效解决文件读取过程中的编码问题。
问题1:读取文件名格式错误问题: Initializing from file failed
出现原因:在jupyter读取csv文件时候,最好不要用中文命名
解决方法:更改成中文则问题解决
![]()
问题2:'utf-8' codec can't decode byte 0xbe in position 0: invalid start byte
原因:文件读取编码格式错误
解决方法1:读取csv文件时候增加编码格式
df=pd.read_csv(data_source,encoding='utf-8')
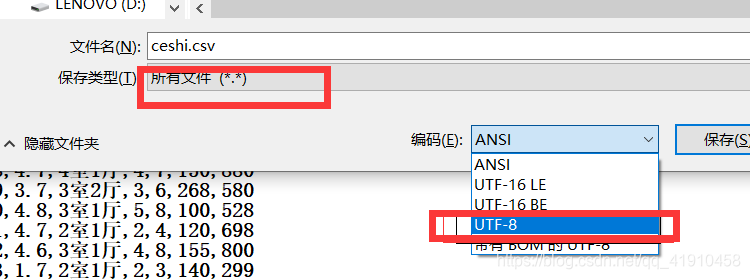
解决方法2:将文件按照utf-8格式另存为
首先将文件用记事本 txt格式打开

然后保存格式选择utf-8即可


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









