







系列文章目录
参考: 菜狗日常
文章目录
项目结构
-
此项目是自己写的吗?
Github 参考golang 实现的简单数据库,依据项目的基本框架,改造成 Java版 的数据库 -
为什么要做此项目?
- 熟悉数据库的基本原理,并更好的在开发中使用
- 自己的需求无法满足时,可以试着去实现
- 造轮子对自己的思考能力、编码能力都会有很大的帮助
-
整体结构时怎样的?
前端 + 后端,通过socket进行交互
前端:读取用户输入,发送到后端执行,输出返回结果,等待下一次输入
后端: 解析SQL,如果时合法的SQL,尝试执行并返回结果后端划分五个模块,每个模块通过接口向其依赖的模块提供方法
五个模块:

五个模块的依赖关系:
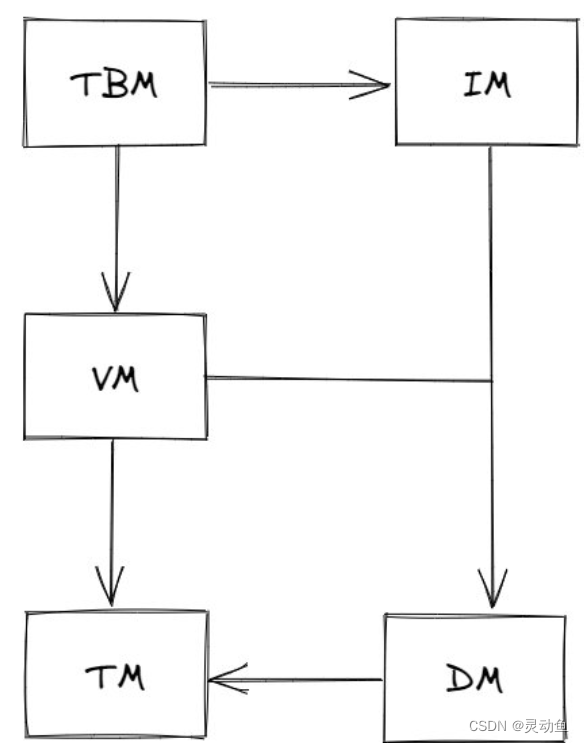
-
五大模块各自的职责(作用)?TM -> DM -> VM -> IM -> TBM
- TM 通过维护 XID 文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态
- DM 管理 DB 文件 + 日志文件
分页管理 DB 文件,并进行缓存
管理日志文件,保证在发生错误的时可以根据日志进行恢复
抽象 DB 文件为 DataItem 共上层模块使用,并提供缓存 - VM 基于两段锁协议实现调度序列的可串行化,并实现 MVCC 以消除读写阻塞。同时实现两种隔离级别
- IM实现基于 B+ 树索引,B树索引,目前where只支持已索引字段
- TBM 实现对字段和表的管理。同时解析 SQL 语句,并根据语句操纵表
-
开发环境
Window 11 + Idea 2021 + JDK 8
事务管理模块 (TM)
基础知识
-
TM 模块作用是什么?
通过 XID 文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态 -
什么是 XID 文件?
XID 文件的开头保存一个 8 字节的数字,记录 XID 文件中事务的个数,然后给每个事务分配 1 字节 , 用来保存事务的状态
举个例子:第 2 个事务(xid, id =2)在文件中的状态就存储在 (xid - 1) + 8 字节处,因为 第 1 个事务是超级事务
,永远是已提交状态(committed),不需要记录
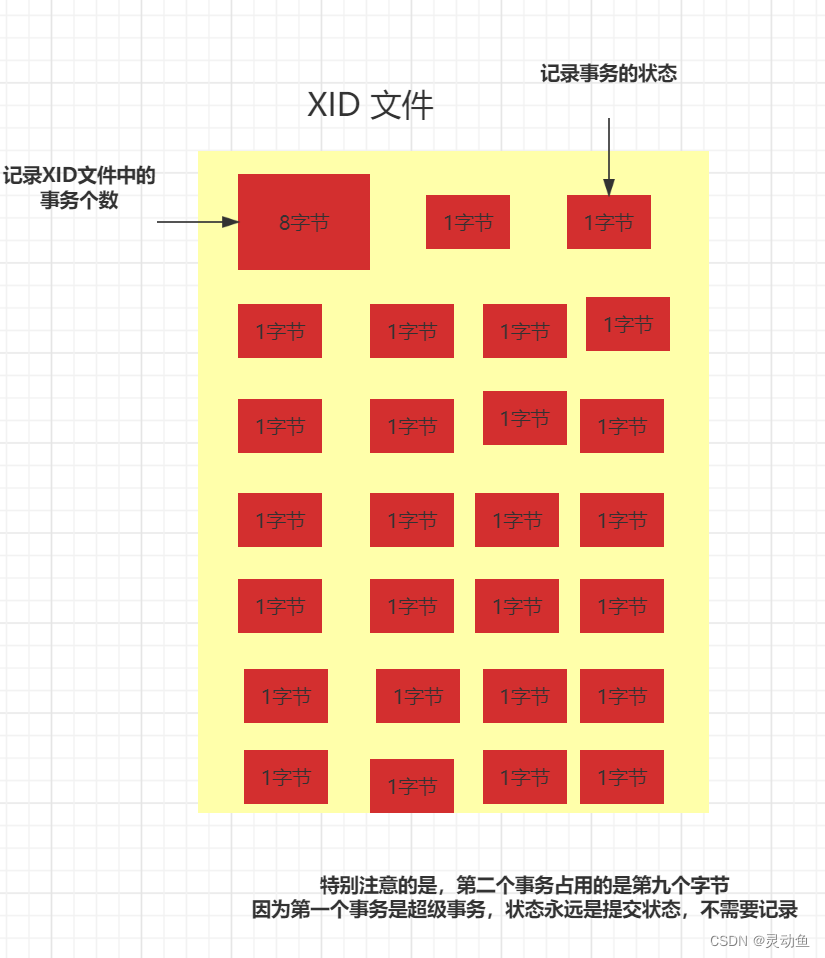
-
事务有哪几种状态?
- active 正在进行,尚未结束
- committed 已提交
- absorted 已撤销(回滚)
-
xid 有那些特点?
每个事务对应一个xid(唯一性)
xid是从1开始标号,并自增(不可重复性)
第1个事务 是超级事务,操作在没有事务下进行,操作的xid 设成 0 永远是committed状态 (特殊性)
代码实现
接口就是以下七个方法:
1. 开始事务、提交事务、回滚事务
2. 事务是否进行、事务是否提交、事务是否撤销
3. TM 关闭
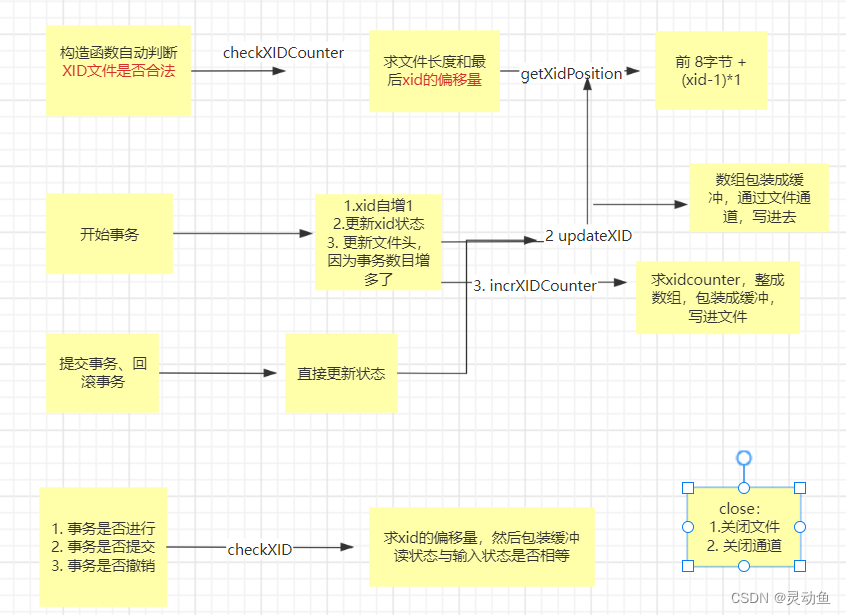
- 如何写和读 XID 文件?
采用 NIO 方式 的 FileChannel
数据管理模块 (DM)
前言
DM 模块是最底层的模块
- DM 模块的作用?
直接管理 DB 文件和日志文件:
1. 分页管理 DB 文件 ,并进行缓存
2. 管理日志文件,保证发生错误时可以根据日志进行恢复
3. 抽象 DB 文件为 DataItem 供上层模块使用,并提供缓存
简单地说:
上层模块和文件系统之间的一个抽象层,向下直接读写文件,向上提供数据的包装;
日志功能
引用计数缓存框架
分页管理和数据项管理涉及缓存,需要设计缓存框架
-
为什么用引用计数缓存而不是LRU呢?
LRU 策略中,资源驱逐不可控,上层模块无法感知
引用计数缓存只有上层模块主动释放引用,缓存在确保没有模块在使用这个资源时,才会驱逐资源 -
缓存满,引用计数无法释放缓存会报什么错?
OOM 内存溢出 -
引用计数器有哪些方法?
get(key) release(key) -
引用计数的功能?
- 缓存
- 计数
实现

共享内存数组
Java将数组看成一个对象,在内存中是以对象的形式存储的,无法实现共享内存数组,单纯松散地规定数组的可使用范围
public class SubArray {
public byte[] raw;
public int start;
public int end;
public SubArray(byte[] raw, int start, int end) {
this.raw = raw;
this.start = start;
this.end = end;
}
}
前言
主要内容: DM 模块向下对文件系统的抽象部分
DM 将文件系统抽象成页面,每次对文件系统的读写都是以页面为单位,同样,从文件系统读进去的数据也是以页面为单位进行缓存的
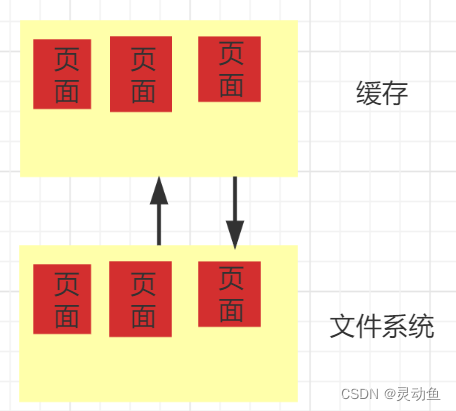
页面缓存
-
默认数据页的大小为 8 K。如果想要提升数据库写入大量数据情况下的性能的话,可以适当增大此值 -
缓存页面直接借用上一节的缓存框架
-
页面的结构是怎样的?【PageImpl Page】
- 页号
- 实际包含的字节数据
- 是否为脏页,在缓存驱逐时,脏页需要写回磁盘
- 页面缓存的引用,可以快速对页面进行释放操作
接口:

- 页面缓存【PageCacheImpl PageCache】

getPage方法: 求页数
close方法:往中存页面关闭
release方法:强行释放某页的缓存
flushPage方法:将某页刷新到磁盘
getPageNumber方法:获得页数
truncateByBgno方法: 将某页截断,即删除
- 同一条数据是不允许跨页存储,即单页数据的大小不能超过数据库页面的大小
数据页管理
第一页
-
存储一些元数据、用来做启动检查
-
原理:
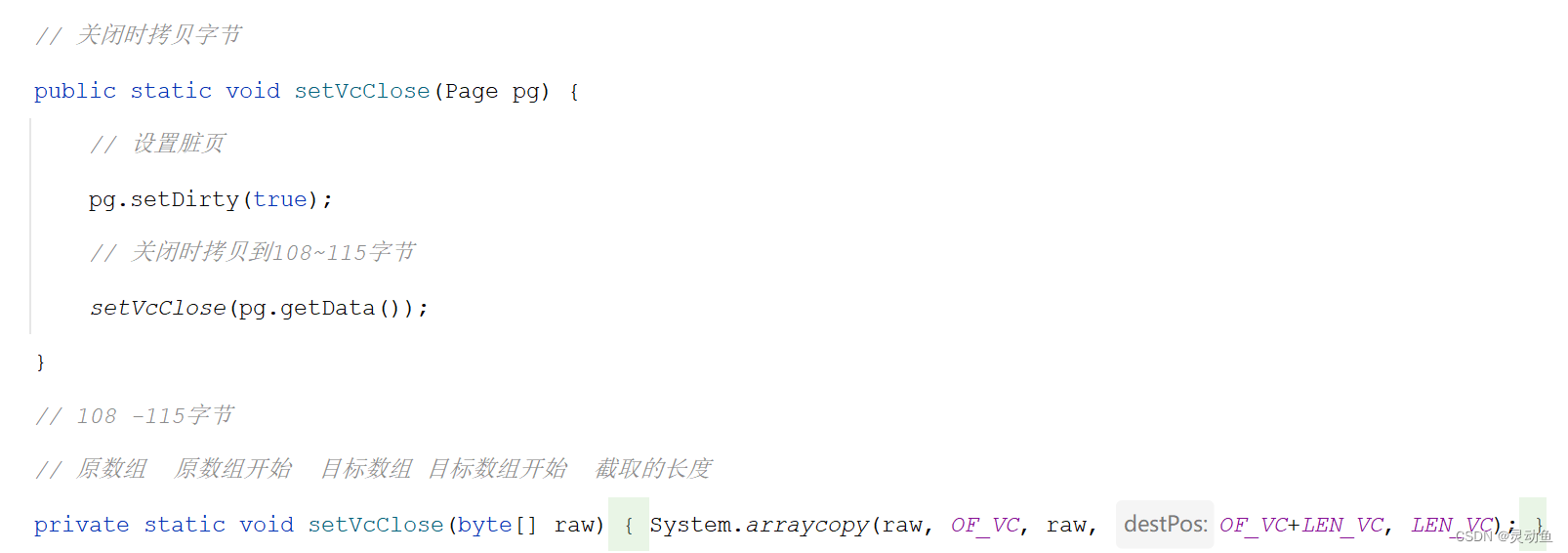
- 在每次数据库启动时,会生成一串随机字节,存储在 100-107字节,在数据库关闭时,会将这串字节,拷贝到第一页的108-115字节
- 数据库在每次启动时,就会检查一页两处的字节是否相同,依次来判断上一次是否正常关闭,如果是异常关闭,就需要执行数据的恢复流程
-
过程
-
启动时设置初识字节


-
关闭时拷贝字节
-
校验字节

-
普通页
- 以 2 字节无符号数启始,表示这一个页空闲位置处得偏移,其他就是存储实际的数据
- 对普通页的管理,基本都是围绕着对 FSO(Free Space Offset)进行的
此块比较难,代码在 PageX
- insert
- recoverInsert
- recoverUpdate
前言
- 崩溃后的数据恢复功能
- DM 层在每次对底层数据操作时,都会记录一条日志在磁盘上,在数据库崩溃时,再次启动,可以根据日志的内容,恢复数据文件,保证其一致性
日志读写
- 日志是二进制文件,按照如下格式进行排布:

XChecksum: 4字节的整数 后序所有日志计算的校验和
Log1 ~ LogN 常规的日志数据
BadTail 数据库崩溃时,没来得及写完的日志数据(不一定存在)
-
每条日志的格式:

Size: 四字节整数,标志Data段的字节数
Checksum: 该日志的校验和 -
单条日志的校验和,通过指定种子实现
-
所有日志校验和进行求和操作,就能得到日志文件的校验和
-
calChecksum: 对所有日志求校验和,就能得到日志文件的校验和
-
internNext: 不断从文件中读取下一条日志,并将其中的 Data 解析出来并返回
-
checkAndRemoveTail: 检查并移除bad tail
-
log : 将数据包裹成日志格式,写入文件后,再更新文件的校验和,更新校验和时,会刷新缓冲区,保证内容写入磁盘
恢复策略
- 插入新数据(I) 、更新现有数据(U)
- 两种数据操作,DM 记录日志如下:

日志策略:
在进行I 和 U 操作之前,必须先进行对应的日志操作,以保证日志写入磁盘后,才能进行数据操作
- 不考虑并发情况下,在某一时刻,只可能有一个事务在操作数据库,日志的格式为:

单线程恢复策略
- 对于单线程,Ti、Tj 和 Tk 的日志永远不会相交,假设日志中最后一个事务是 Ti,日志恢复过程如下:
1. 对 Ti 之前所有事务的日志,进行重做(redo)
2. 接着检查Ti 的状态(XID),如果 Ti 的状态是已完成(committed 和 absorted) ,就将 Ti 重做,否则进行撤销(undo)
- 是如何对事务T 进行 redo?

- 是如何对事务T 进行 undo?

多线程恢复策略
多线程下情况怎么样?
- 第一种:

在系统崩溃时,T2仍然是活跃状态,那么当数据库重启,执行恢复例程时,会撤销T2,他对数据库的影响会被消除。
但是由于T1 读取 了 T2 更新的值,既然 T2 被撤销了,那么 T1 也应当被撤销,这种情况,就是级联回滚,但是,T1已经commit,所有commit的事务,已经持久化,这就造成了矛盾
如何避免以上问题?
规定1: 正在进行的事务,不会读取其他任何未提交的事务产生的数据
- 第二种情况: 假设 x 的初值 是 0

在系统崩溃时,T1 仍然是活跃状态。那么当数据库重新启动,执行恢复例程时,会对 T1 进行撤销,对 T2 进行重做,但是,无论撤销和重做的先后顺序如何,x 最后的结果,要么是 0,要么是 2,这都是错误的
如何避免以上问题?
规定2: 正在进行的事务,不会修改其他任何未提交的事务修改或产生的数据
并发情况下日志恢复?
在不会发生规定1或者规定2的基础(VM层会满足)上:
重做所有崩溃时已完成(committed或aborted)的事务撤销所有崩溃时未完成(active)的事务
实现
- redoTranscations
- undoTranscations
- doUpdateLog、doInsertLog
前言
- 实现简单的页面索引,并且实现 DM 层对上层的抽象
页面索引
-
页面索引,
缓存了每一页的空闲空间, 用于在上层模块进行插入操作时,能够快速找到一个合适空间的页面,而无需从磁盘或者缓存中检查每一个页面的信息 -
页面索引实现:
- 将一页的空间划分成了 40 个区间
2.在启动时,就会遍历所有的页面信息,获取页面的空闲空间,安排到这 40 个区间中
- insert 在请求一个页时,会首先将所需的空间向上取整,映射到某一个区间,随后取出这个区间的任何一页,都可以满足需求
到这了!!!
DataItem
版本管理模块(VM)
- 基于两段锁协议实现了调度序列的可串行化,并实现了 MVCC 以消除读写阻塞。同时实现了两种隔离级别。
冲突 与 2PL
-
数据库冲突定义:
只看更新操作(U) 和 读操作®,两操作只要满足以下三条件
1. 两操作是由不同的事务执行
2. 两操作操作的是同一数据项
3. 两操作至少有一个是更新操作
就可以这两个操作相互冲突 -
数据库冲突的两种情况?
1. 两个不同事务的 U 操作冲突
2. 两个不同事务的 U 、 R 操作冲突 -
定义数据冲突的意义?
交换两个互不冲突的操作的顺序,不会对最终结果造成影响,而交换两个冲突操作的顺序,则是会有影响例子:在并发情况下,两个事务同时操作 x , 假设 x 的初值为 0,最后的 x 的结果是 1
xxxx

– 两段锁协议( 2PL )
当采用 2PL 时,如果某个事务 i 已经对 x 加锁,且另一个事务 j 也想操作 x,如果 两操作相互冲突的话, 事务 j 就会进行相应阻塞
例子: T1 已经因为 U1(x) 锁定 x,那么 T2 对 x进行读或者写操作都会被阻塞, T2 必须等 T1 释放 对 x 的锁
- 2PL 确实保证了调度序列的可串行话,但是不可避免地导致了事务间的相互阻塞,甚至可能导致死锁
MVCC
- 提高事务处理效率、降低阻塞概率
- DM 层向上层提供了数据项(Data Item)的概念,VM 通过管理所有的数据项,向上层提供了**记录(Entry)**的概念
- 上层模块通过 VM 操作数据的最小单位,就是记录,VM 则在其内部,为每个记录,维护了多个版本(Version),每当上层模块对某个记录进行修改时,VM 就会为这个记录创建一个新的版本
例子: T1 想要更新记录 X 的值,T1 首先获取 X 的锁,接着更新,也就是创建了一个新的 X 的版本,假设为 x3。假设 T1 还没有释放 X 的锁时, T2 想要读取 X 的值,这时候就不会阻塞,会返回一个较老版本的X,例如 x2,这样最后的执行结果,就等价于,T2先执行,T1后执行,调度序列依然是串行化的,如果 X 没有一个更老的版本,那只能等待 T1 释放锁,所以说只是降低概率
为保证数据的可恢复性,VM 层传递到 DM 的操作序列需要满足:
规则1: 正在进行的事务,不会读取其他任何未提交的事务产生的数据
规则2:正在进行的事务,不会修改其他任何未提交的事务或修改或产生的数据
由于 2PL 与 MVCC 这两个条件就很轻易满足
记录的实现
Entry类维护

- XMIN 创建该条记录(版本)的事务编号
- XMAX 删除该条记录(版本)的事务编号
- DATA 记录持有的数据
事务的隔离级别
读提交
- 事务在读取数据时, 只能读取已经提交事务产生的数据














 2265
2265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









