







正则表达式
通过匹配规则来获取或者验证字符串中的数据
应用场景:
- 判断一个字符串是否符合规则
- 取出制定数据
- 爬虫核心的技术
- 彩票网站匹配彩票信息
匹配字符串的需要条件:
- 正则表达式模块-re
- 匹配的规则,即正则表达式
- 被匹配的字符串
正则表达式中特殊字符

例:
import re
a = 'my name is zs,age is 18'
print(f'字符串:{a}')
# 匹配字符串开头和结尾
# 匹配到则返回列表(列表中有匹配到的字符串),匹配不到则显示空列表
b1 = re.findall('\Amy', a)
print(f'\A匹配字符串开头my:{b1}')
b2 = re.findall('\Amy1', a)
print(f'\A匹配字符串开头my1:{b2}')
b3 = re.findall('18\Z', a)
print(f'\Z匹配字符串结尾18:{b3}')
b4 = re.findall('\w', a)
print(f'\w匹配字符串数字字母和下划线:{b4}')
b5 = re.findall('\s', a)
print(f'\s匹配任意空白字符:{b5}')
b6 = re.findall('\d', a)
print(f'\d匹配任意数字:{b6}')
结果:

正则表达式中的符号

例:
import re
a = 'my name is zs,age is 18'
print(f'字符串:{a}')
b1 = re.findall('^my', a)
print(f'^匹配字符串开头my:{b1}')
b2 = re.findall('^my1', a)
print(f'^匹配字符串开头my1:{b2}')
b3 = re.findall('18$', a)
print(f'$匹配字符串结尾18:{b3}')
# 或的关系,匹配到的数据只按字符串顺序返回,而不是按照匹配规则返回
b4 = re.findall('am|ag|my', a)
print(f'|,或的关系,存在就捕获:{b4}')
b5 = re.findall('\w*', a)
print(f'\w*匹配0次或多次数字字母:{b5}')
b6 = re.findall('\w+', a)
print(f'\w+匹配1次或多次数字字母:{b6}')
b7 = re.findall('\w{2}', a)
print(f'\w{2}匹配2次数字字母:{b7}')
b8 = re.findall('\w{2,3}', a)
print(f'\w{2,3}匹配2到3次数字字母:{b8}')
b9 = re.findall('[a1]', a)
print(f'[a1]匹配a或1:{b9}')
b10 = re.findall('[0-9]', a)
print(f'[0-9]匹配数字:{b10}')
结果:

贪婪与非贪婪
- 0次或多次属于贪婪模式
- 通过?组合变成非贪婪模式
组的概念:
- ():只要指定的数据进行匹配
例:
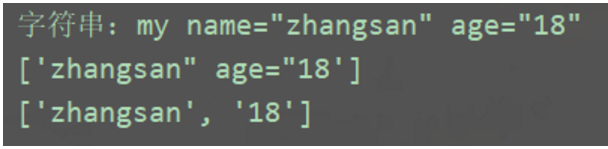
import re
a = 'my name="zhangsan" age="18"'
print(f'字符串:{a}')
# .*表示匹配0次或多次任意字符(除换行符)
# 这种是贪婪模式,匹配的是第一个"到最后一个"之间的内容
b1 = re.findall('="(.*)"', a)
print(b1)
# 加上?非贪婪模式,匹配第一个"到第二之间,再第二到第三之间的...
b2 = re.findall('="(.*?)"', a)
print(b2)
结果:
findall()
- 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表
findall(pattern, string[,flags])
参数:
- pattern:正则表达式
- string:被匹配的字符串
- flags:选填参数,额外匹配规则
re的额外匹配要求

例:
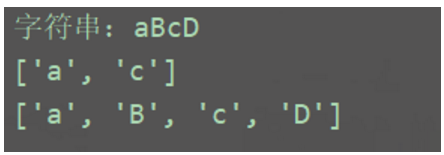
import re
a = 'aBcD'
print(f'字符串:{a}')
# 匹配小写字母
b1 = re.findall('[a-z]', a)
print(b1)
# 匹配小写字母,使用特殊符合忽略大小写
b2 = re.findall('[a-z]', a, re.I)
print(b2)
结果:
search()
- 使用可选标记搜索字符串中第一次出现的正则表达式模式。
- 若匹配成功,则返回匹配对象;
- 若失败,则返回None
search(pattern,string,flags=0)
参数:
- pattern:正则表达式
- string:被匹配的字符串
- flags:选填参数,额外匹配规则
group()与groups()
- group(num):返回整个匹配对象,或者编号为num的特定子组
- groups():返回一个包含所有匹配子组的元组,若没有匹配成功,则返回一个空元组
例:
import re
a = 'my name is zhangsan,age is 18'
print(f'字符串:{a}')
b1 = re.search('my name is (.*),age is (.*)', a)
print(b1.groups())
print(b1.group(1))
print(b1.group(2))
结果:

split()
- 根据正则表达式的模式分隔符,split函数将字符串分割为列表,然后返回成功匹配的列表,分割最多操作max次(max默认为0,表示分割所有匹配成功的位置)
split(pattern,string[, maxsplit=0, flags=0])
参数:
- pattern:正则表达式
- string:被匹配的字符串
- maxsplit:选填参数,最多分割次数
- flags:选填参数,额外匹配规则
例:
import re
a = 'a1b2c3d'
print(f'字符串:{a}')
# 匹配小写字母
b1 = re.findall('[a-z]', a)
print(b1)
# 使用小写字母进行切割,若前后默认为空
b2 = re.split('[a-z]', a)
print(b2)
结果:

match
- 尝试从字符串的起始位置匹配一个模式
- 如果匹配成功, 就返回匹配对象; 如果失败, 就返回 None
match(pattern,string,flags=0)
例:
import re
a = 'a1b2c3d'
print(f'字符串:{a}')
# 在起始位置匹配成功
b1 = re.match('a1', a)
print(b1)
print(b1.group())
print('---------')
# 在起始位置匹配失败
b2 = re.match('a2', a)
print(b2)
结果:

compile
- 定义一个匹配规则的对象
compile(pattern,flags=0)
例:
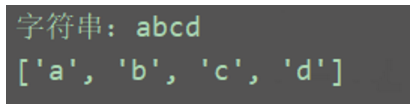
import re
a = 'abcd'
print(f'字符串:{a}')
# 匹配小写字母
c = re.compile('[a-z]')
b1 = re.findall(c, a)
print(b1)
结果:















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









