






直接进入正题(记录我初学爬虫的一些心得):
我爬的是豆瓣的电影,具体项目有电影名称、导演名、演员名、影片类型、影片海报、还有部分关于电影的短评(太多了的话爬一次时间太长,不太好往数据库里存)
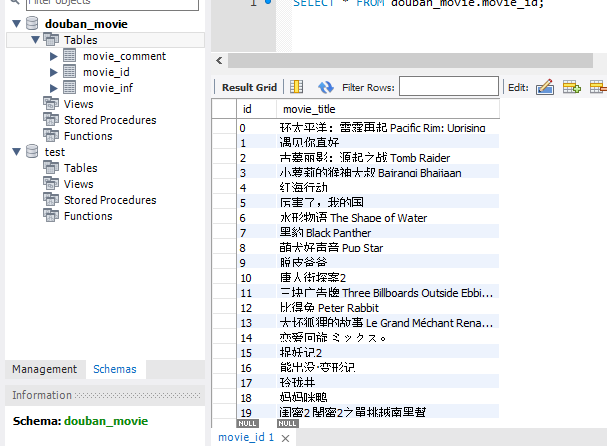
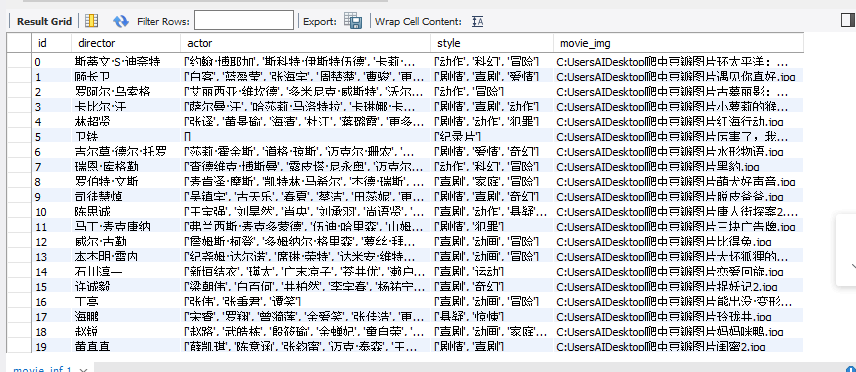
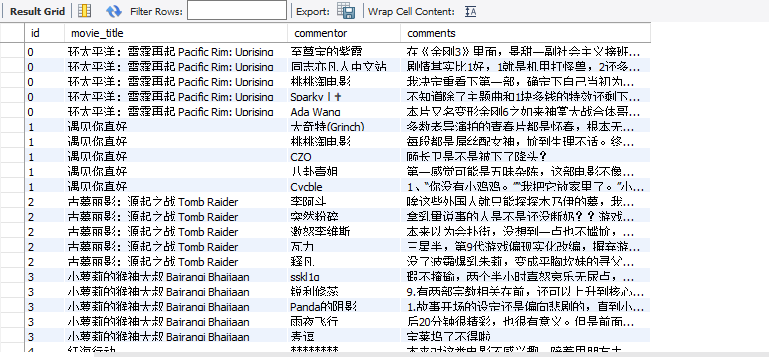
先上最后结果吧:
首先,
先明确爬虫思路:①伪装成浏览器访问豆瓣网(https://movie.douban.com/),通过Google浏览器的网页编辑功能(具体操作就是F12),找到浏览器信息,然后访问
②在返回的html.text中,找到下面的“

直接进入正题(记录我初学爬虫的一些心得):
我爬的是豆瓣的电影,具体项目有电影名称、导演名、演员名、影片类型、影片海报、还有部分关于电影的短评(太多了的话爬一次时间太长,不太好往数据库里存)
先上最后结果吧:
首先,
先明确爬虫思路:①伪装成浏览器访问豆瓣网(https://movie.douban.com/),通过Google浏览器的网页编辑功能(具体操作就是F12),找到浏览器信息,然后访问
②在返回的html.text中,找到下面的“
 2151
574
450
2151
574
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















