







索引是帮助MySQL高效获取数据的排好序的数据结构
1. 索引的数据结构
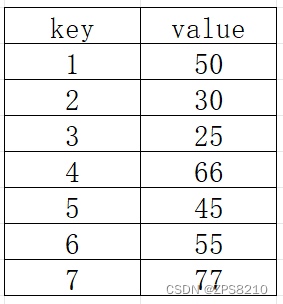
select * from t where t.value = 55
● 直接查询这个列表,需要依次查询,查询 6次。时间复杂度O(n)
● 查询需要多次磁盘IO, 数组还需要占用连续的存储空间
1.1 二叉树
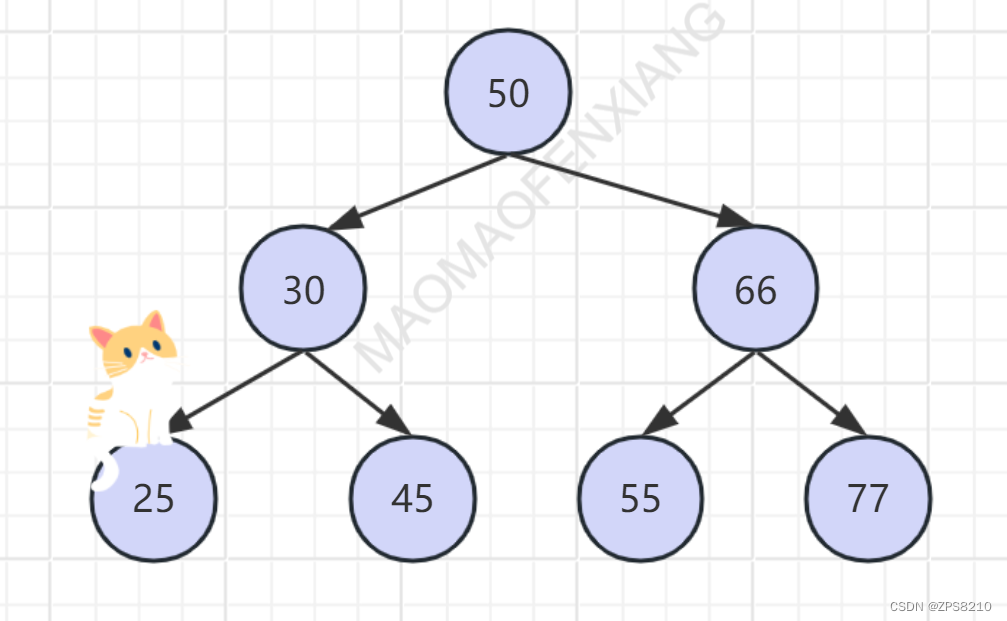
使用二叉树查询(二分查找法)则需查询3次。时间复杂度 O(log n)
问题: mysql底层索引为什么不使用二叉树呢?
● 如果value插入顺序为1,2,3,4,5,6,7。二叉树会退化成链表

1.2 红黑树
处理二叉树退化成链表的问题,尝试使用红黑树。 树的高度明显降低,查询效率提升
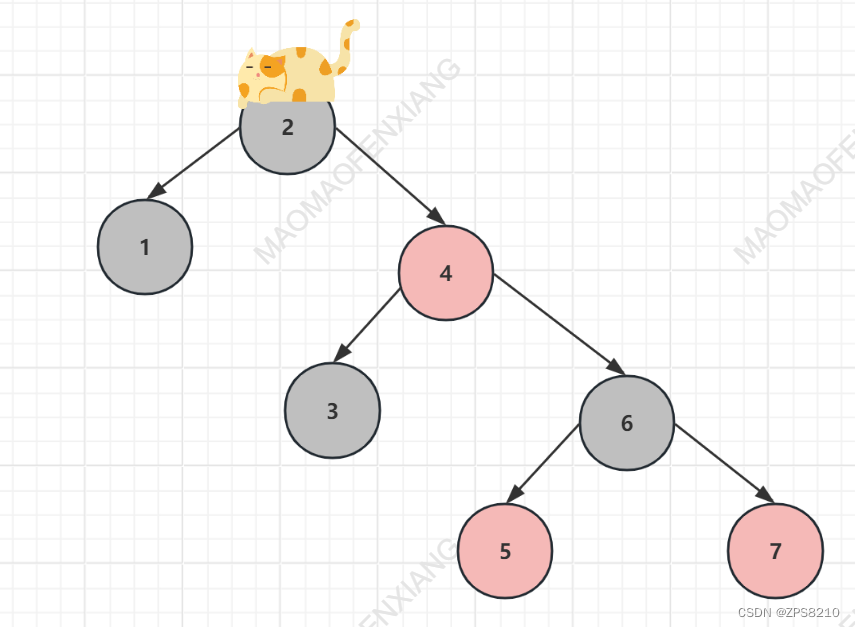
问题: mysql底层索引为什么不使用红黑树呢?
- 500W数据 --> 至少需要20次遍历查找
- 树的高度不可控
扩展
● 红黑树和平衡二叉树区别
1、AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,AVL是严格的平衡二叉树,平衡条件必须满足所有节点左右子树高度不超过1。
不管我们执行插入还是删除操作,只要不满足上述条件,就要通过旋转来保持平衡,而且因为旋转非常耗时,因此我们知道AVL平衡树适用于插入、删除比较少的情况,查找比较多的情况
由于维护这种高度平衡所付出的代价比从中获取的效率收益还大,故而实际的应用不多,更多地方用的是追求局部而不是非常严格整体平衡红黑树,当然,如果应用场景中插入删除不频繁,查找较多,还是用AVL树优于红黑树。
2、红黑树是一种弱平衡二叉树(由于是弱平衡,可以看到,在相同节点情况下,AVL树的高度低于红黑树),相对于严格的AVL树来说,它的旋转次数较少,所以对于搜索,插入,删除操作较多的情况下,我们就用红黑树。
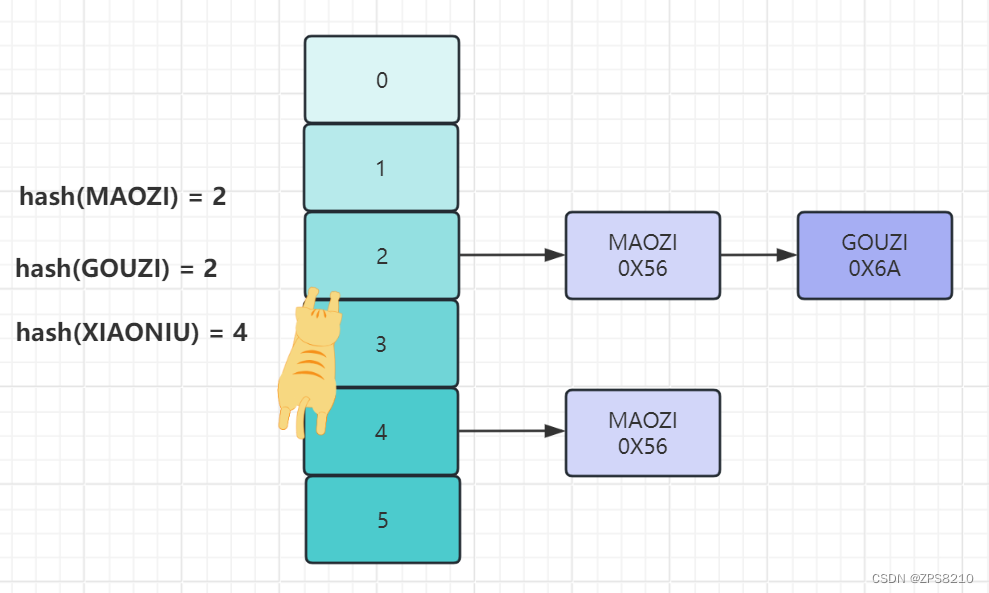
1.5 Hash表
对索引的key进行一次hash运算,就能定位出数据存储的位置,某些时候Hash索引 要比B+Tree索引更高效,但是仅能满足"=","in"查询,不支持范围查找,并且还会有hash冲突问题。
缺点:涉及到范围查询,效率就非常低
1.6 B-Tree
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右依次递增
- 非叶子节点也存储数据
- 相邻节点之间 没有双向指针,范围查找相对复杂
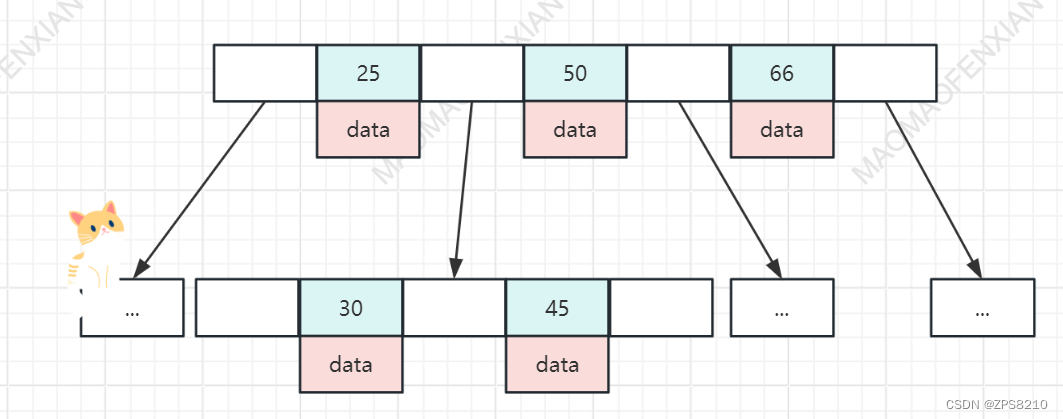
1.7 B+Tree
- 非叶子节点上不存储数据,只存储冗余索引(相同的空间可以放更多的索引,降低树的高度,B+Tree树的高度是由非叶子节点上能存储多少个元素决定的),每个非叶子节点的索引是下层节点的首个索引。
- 叶子节点包含所有索引
- 相邻叶子节点之间有双向指针连接提高区间访问的性能(Mysql优化)
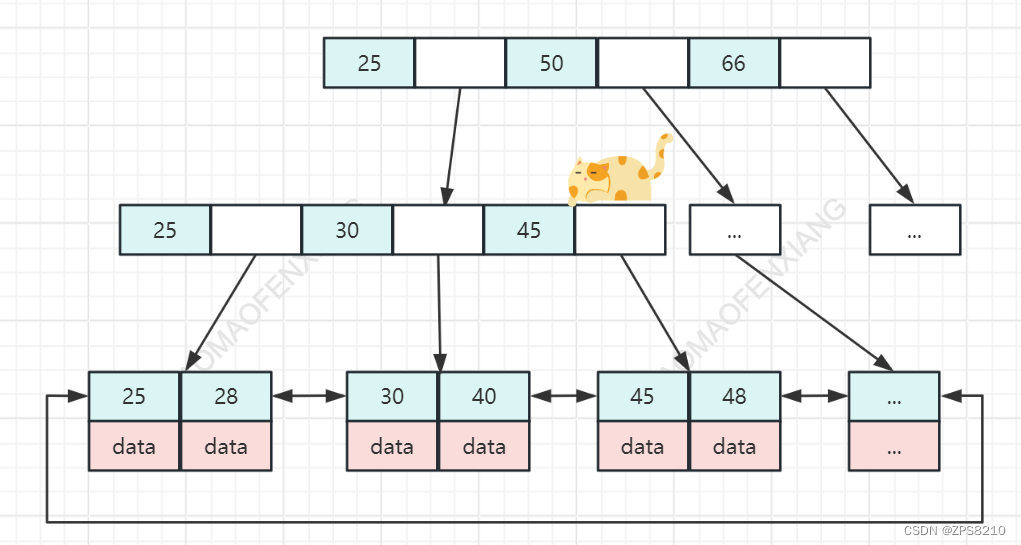
查询过程:
比如需要查询30这个元素,首先将25 50 66 数据load到内存,然后查询到25 30 45 然后load内存… 直到查找到30获取data。查询三次就可以定位到。如果根节点放内存,速度更快。
一个页大概16KB —> 大概可以放1170元素,3层高度的树大概可以放 1170 X 1170 X 16 (2000W) 个元素















 2362
2362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









