







文章目录
https://github.com/2NaCl/kafka-demo
本文涉及到的代码已上传到github
Kafka现在不仅仅可以当做消息队列去使用,也可以进行流处理计算的平台。
其主要功能如下:
- 发布和订阅:将消息流作为一个发布订阅的信息传递系统。
- 处理:数据流可以高效且实时响应事件
- 存储:将数据流安全的存储在一个多副本的分布式的系统内。

Kafka®用于构建实时数据管道和流应用程序。它具有水平可扩展性,容错性,快速性。
好,官网首页翻译完了,下面进入对于Kafka本身的概述。
Kafka概述
Kafka和我们之前所学过的MQTT,或者AMQ之类的有些类似地方,并且其主要的角色是消息中间件。
消息中间件:说白话的话,老板做肉夹馍给我吃,我一秒吃一个,老板一秒做五个,我没办法在一秒内吃完那四个,所以得把那四个放碗里,这个碗就相当于中间件,一个碗是中间件,两个碗就是中间件扩容。

Kafka架构方面共有以下几个主要角色:
- producer:生产者,也就是卖肉夹馍的老板
- consumer:消费者,也就是吃肉夹馍的我
- broker:也就是Kafka本身的容器,也就是放肉夹馍的碗
- topic:主题,你点餐之后,老板给你个牌,意思就是牌成了给你吃肉夹馍的header
Kafka通常用于两大类应用:
- 构建可在系统或应用程序之间可靠获取数据的实时流数据管道
- 构建转换或响应数据流的实时流应用程序
此外,Kafka还有三个特点:
- Kafka作为一个集群运行在一个或多个可跨多个数据中心的服务器上。
- Kafka集群以称为主题的类别存储记录流。
- 每条记录由一个键,一个值和一个时间戳组成。
然后开始进入一下入门的案例
目标一:部署及使用单节点单Broker
首先启动Kafka 这里也可以启动在后台,看个人了。
[centos01@linux01 config]$ kafka-server-start.sh
$KAFKA_HOME/config/server.properties
其次创建topic
[centos01@linux01 config]$ kafka-topics.sh \
--create \
--zookeeper linux01:2181 \
--replication-factor 1\
--partitions 1 \
--topic test
也可以查看一下现有的topic
[centos01@linux01 config]$ kafka-topics.sh \
--list \
--zookeeper linux01:2181
然后对着这个topic发送消息
[centos01@linux01 config]$ kafka-console-producer.sh \
--broker-list linux01:9092 \
--topic test
然后发送消息就可以直接发送到broker内了:
可以用一个消费者来监控到生产者发送的信息(–from-beginning代表从生产者开始的时候就开始监控,不然就只能监控到启动这条命令之后的信息)
[centos01@linux01 config]$ kafka-console-consumer.sh \
--zookeeer linux01:2181 \
--topic test \
--from-beginning
另外也可以查看所有topic的详细信息
[centos01@linux01 config]$ kafka-topics.sh \
--describe \
--zookeeper linux01:2181
和一个topic的详细信息
[centos01@linux01 config]$ kafka-topics.sh \
--describe \
--zookeeper linux01:2181\
--topic test
目标二:部署及使用单节点多Broker
按照官网的案例,我们也创建一个集群下的三个节点,先首先复制一下我们的properties

然后修改①端口号和②roker_id还有③输出的日志文件的名字修改一下,下面只展示server1.properties的关键地方的配置
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
其他配置文件雷同,配置之后,分别在后台启动三个broker
[centos01@linux01 config]$ kafka-server-start.sh server1.properties &
[centos01@linux01 config]$ kafka-server-start.sh server2.properties &
[centos01@linux01 config]$ kafka-server-start.sh server3.properties &
然后老套路,创建topic,但是这次的规格是一个分区三个副本
[centos01@linux01 ~]$ kafka-topics.sh \
--create \
--zookeeper linux01:2181 \
--replication-factor 3 \
--partitions 1 \
--topic test2
Created topic "test2".
创建成功
然后看一下我们创建的topic的详细信息

然后和之前一样,创建我们的消息生产者
[centos01@linux01 ~]$ kafka-console-producer.sh \
--broker-list linux01:9093,linux01:9096,linux01:9095 \
--topic test2
消费者
kafka-console-consumer.sh --zookeeper linux01:2181 --topic test2
测试方法同上。
有兴趣的可以去看看创建出来的日志文件,.index是索引文件 .log是日志文件
目标三:Kafka API编程–Producer端开发
接下来用IDEA编程的方式来进行分布式消息队列Kafka的编写,也就是创建producer consumer为重点。
- 依赖自行导入
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.11.0.2</version>
</dependency>
- 对Kafka相关的zookeeper,topic,broker-list进行配置

3. 编写生产者类,写一个循环,不断向指定端口发送message
/**
* kafka生产者,需要topic和broker-list
*/
public class KafkaProducer extends Thread{
private String topic;
private Producer<Integer, String> producer;
public KafkaProducer(String topic) {
this.topic = topic;
Properties properties = new Properties();
//建立握手机制:要求服务器端对客户端的消息进行反馈
// 0:不等待握手机制反馈
// 1:服务端将请求写入日志,然后立刻响应握手 为了不丢失数据,大多数都选择1
// -1:同步等待所有副本的握手机制,最安全
properties.put("request.required.acks", "1");
//设置序列化
properties.put("serializer.class", "kafka.serializer.StringEncoder");
//建立broker-list
properties.put("metadata.broker.list", KafKaProperties.BROKER_LIST);
producer = new Producer<Integer, String>(new ProducerConfig(properties));
}
//用线程的方式开始测试
@Override
public void run() {
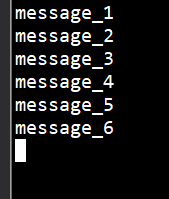
int messageNo = 1;
while (true) {
String message = "message_" + messageNo;//获取消息内容
producer.send(new KeyedMessage<Integer, String>(topic, message));
System.out.println("Sent" + message);
messageNo++;
try {
Thread.sleep(2000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
- 后台启动consumer收集生产者的消息
[centos01@linux01 ~]$ kafka-console-consumer.sh \
--zookeeper linux01:2181 \
--topic test
目标四:Kafka API编程–Consumer端开发
-
还是先设置我们的配置文件,在原来的基础上加一个group_id

-
然后编写我们的Consumer类。
/**
* 消费的时候主要用的是zookeeper
* 生产主要依靠broker-list
*/
public class KafkaComsumer extends Thread{
private String topic;
public KafkaComsumer(String topic) {
this.topic = topic;
}
private ConsumerConnector createConnector() {
Properties properties = new Properties();
properties.put("zookeeper.connect", KafKaProperties.ZK);
properties.put("group.id", KafKaProperties.GROUP_ID);
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
@Override
public void run() {
ConsumerConnector consumerConnector = createConnector();
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
// String:topic
// List<KafkaStream<byte[], byte[]>>对应的数据流
Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumerConnector.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> messageAndMetadata = messageStreams.get(topic).get(0);//获取每一次的数据
ConsumerIterator<byte[], byte[]> iterator = messageAndMetadata.iterator();//使用迭代器遍历得到每次的数据
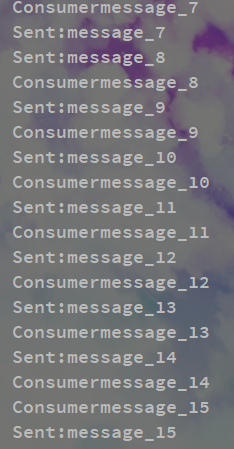
while (iterator.hasNext()) {
String s = new String(iterator.next().message());
System.out.println("Consumer"+s);
}
}
}
- 从后台检测是否消息是同步接收的。
目标五:Kafka API编程–整合Flume完成实时数据采集
- 整体架构
Flume直接用kafka Sink作为Producer给kafka consumer消费

- 配置新的avro-memory-kafka.conf
# Name the components on this agent
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# Describe/configure the source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = linux01
avro-memory-kafka.sources.avro-source.port = 44444
# Describe the sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.topic = test
avro-memory-kafka.sinks.kafka-sink.kafka.bootstrap.servers = linux01:9092
avro-memory-kafka.sinks.kafka-sink.kafka.producer.acks=1
avro-memory-kafka.sinks.kafka-sink.flumeBatchSize = 1
# Use a channel which buffers events in memory
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# Bind the source and sink to the channel
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
- 启动avro-memory-kafka。
[centos01@linux01 conf]$ flume-ng agent \
--name avro-memory-kafka \
--conf ./ \
--conf-file avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
- 再启动exec-memory-avro
flume-ng agent \
--name avro \
--conf ./ \
--conf-file avro-memory-kafka.conf \
-Dflume.root.logger=INFO,console
- 从后台启动一个消费者
[centos01@linux01 ~]$ kafka-console-consumer.sh \
--zookeeper linux01:2181 \
--topic test
- 写入修改flume配置文件中的文件

注:有必要说明一下,在avro-memory-kafka.conf内我们设置了一个flumeBatchSize,这个属性是说明,当发送信息的条数超过多少才会在控制台上打印,我这里设置的是1所以没问题,建议测试的时候数值调低。
然后就打印出来了。















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









