







Hadoop学习笔记
- 一 Hadoop基础概念
- 二 下载安装
- 三 集群搭建
- 四 常用shell命令
- 五 案例
- 六 MapReduce框架原理
- 七 高可用集群搭建
Hadoop是大数据框架之一,提供大数据的存储、计算。是在Lucene的基础上开发的。
一 Hadoop基础概念
Hadoop由common(辅助工具)、HDFS、MapReduce和YARN组成。其中HDFS、MapReduce和YARN又由各个服务组成,每个服务之间使用RPC通信。
1.1 HDFS
HDFS(Hadoop Distributed File System)是Hadoop分布式文件系统,用于存储数据。适合一次写入,多次读出的场景。不能修改已有的数据,只能在文件后面追加新的数据。
1.1.1 组成架构
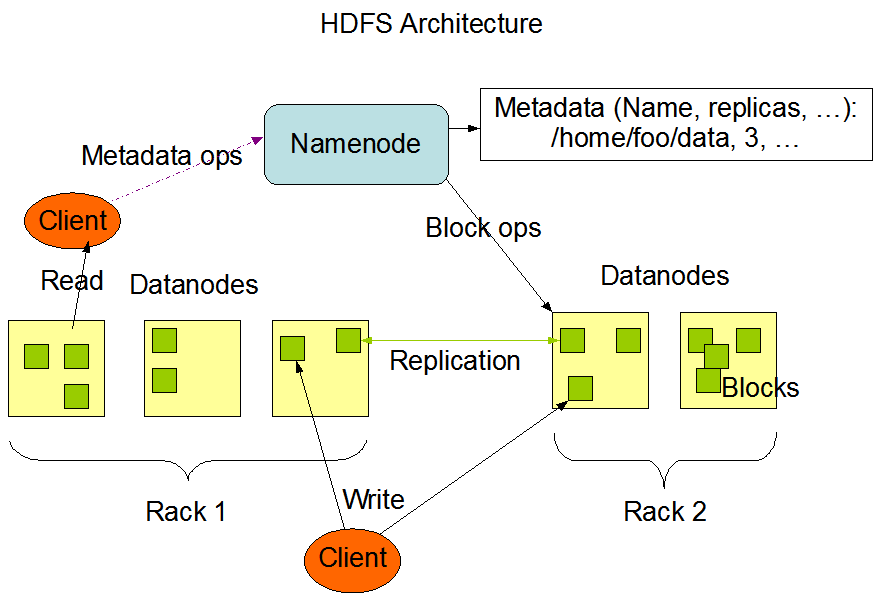
- NameNode(nn):存放DataNode信息。(集群中只有一份,在主节点)
- 管理HDFS的名称空间;
- 配置副本策略;
- 管理数据块(Block)映射信息;
- 处理客户端的读写请求。
- DataNode(dn):存放具体数据。(每个节点都有)
- 存储实际数据;
- 执行数据块的读写操作。
- Secondary NameNode(2nn):辅助NameNode(集群中只有一份,最好放在其他节点)
- 对NameNode部分备份;
- 分担NameNode工作量;
- 辅助恢复NameNode。
- client:客户端
- 文件切分:文件上传HDFS之后,会被切分为一块一块的,每块最大为128M(可调节);
- 与NameNode交互,获取文件位置信息;
- 与DataNode交互,读写数据;
- 提供一些命令用于管理HDFS。比如对NameNode格式化;
- 提供一些命令用于访问HDFS。比如对HDFS进行增删改查。
1.1.2 优缺点
- 优点:
- 高容错性:数据自动保存为多个副本,
- 适合处理大数据:可以处理GB、TB、甚至PB级别的数据。可以处理百万规模以上的文件数量。
- 对部署的机器要求不高。
- 缺点:
- 不适合低延时数据访问
- 无法高效的对大量小文件进行存储
- 不支持并发写入
- 不支持修改历史数据,只支持追加
1.1.3 读写流程
1.1.3.1 写流程
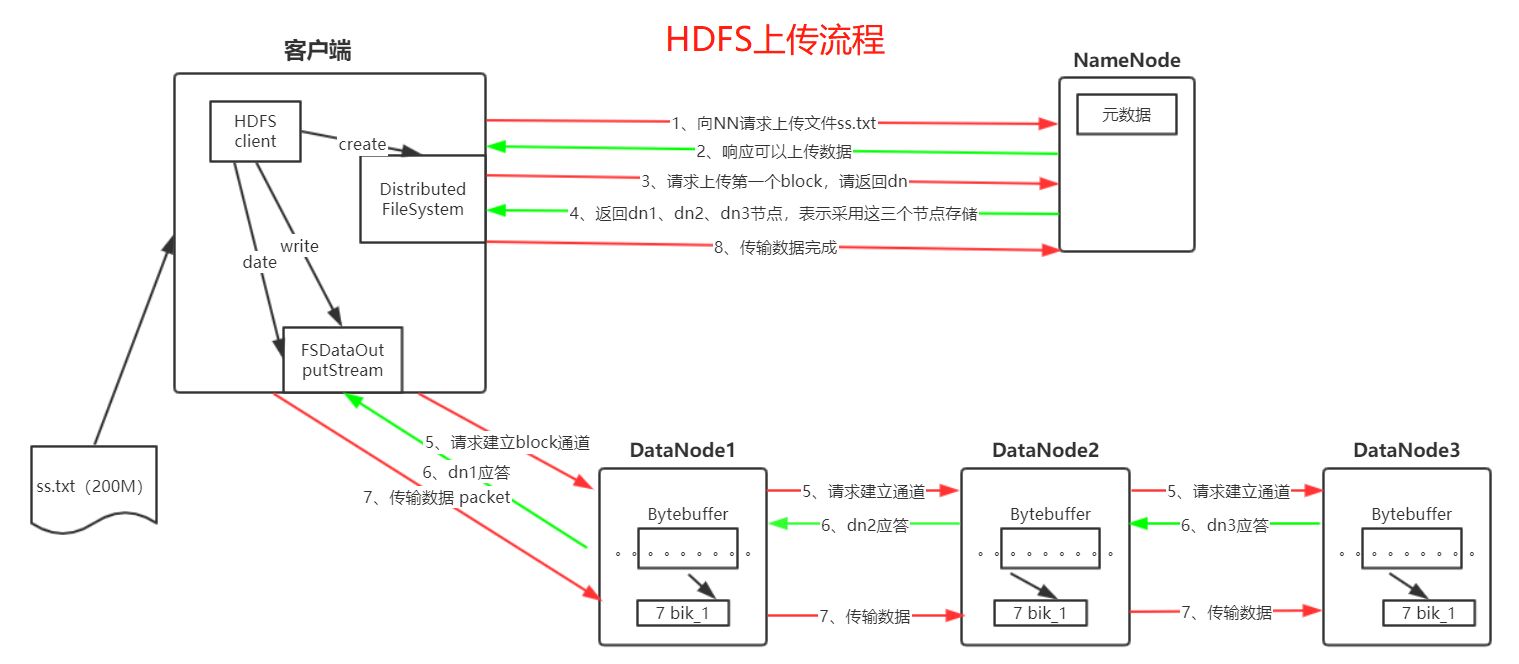
- client向NameNode发送写文件请求;
- NameNode检查权限,检查目录、文件是否已存在;
- NameNode响应client可以上传文件;
- client按照block(块,默认128MB)切分文件;
- client向NameNode请求上传第一个block;
- NameNode返回block存储节点列表,表示块数据存放在哪些节点上;
- client从最近一个节点开始(就近原则),建立pipeline管道(如:client->node1->node2->node3);
- client将block数据写入chunk缓冲区,一个chunk缓冲区为512B数据和4B校验位;
- client将chunk写入packet,packet为64KB;
- client将packet放入DataQueue;
- 根据pipeline管道(如:client->node1->node2->node3)写入DataNode,从DataQueen取出packet写入node1,node1写入node2,node2写入node3;
- packet写完之后返回一个ack packet,放入ack Queue;
- 确认文件是否上传完成;
- client通知NameNode文件上传完成。
1.1.3.2 读流程
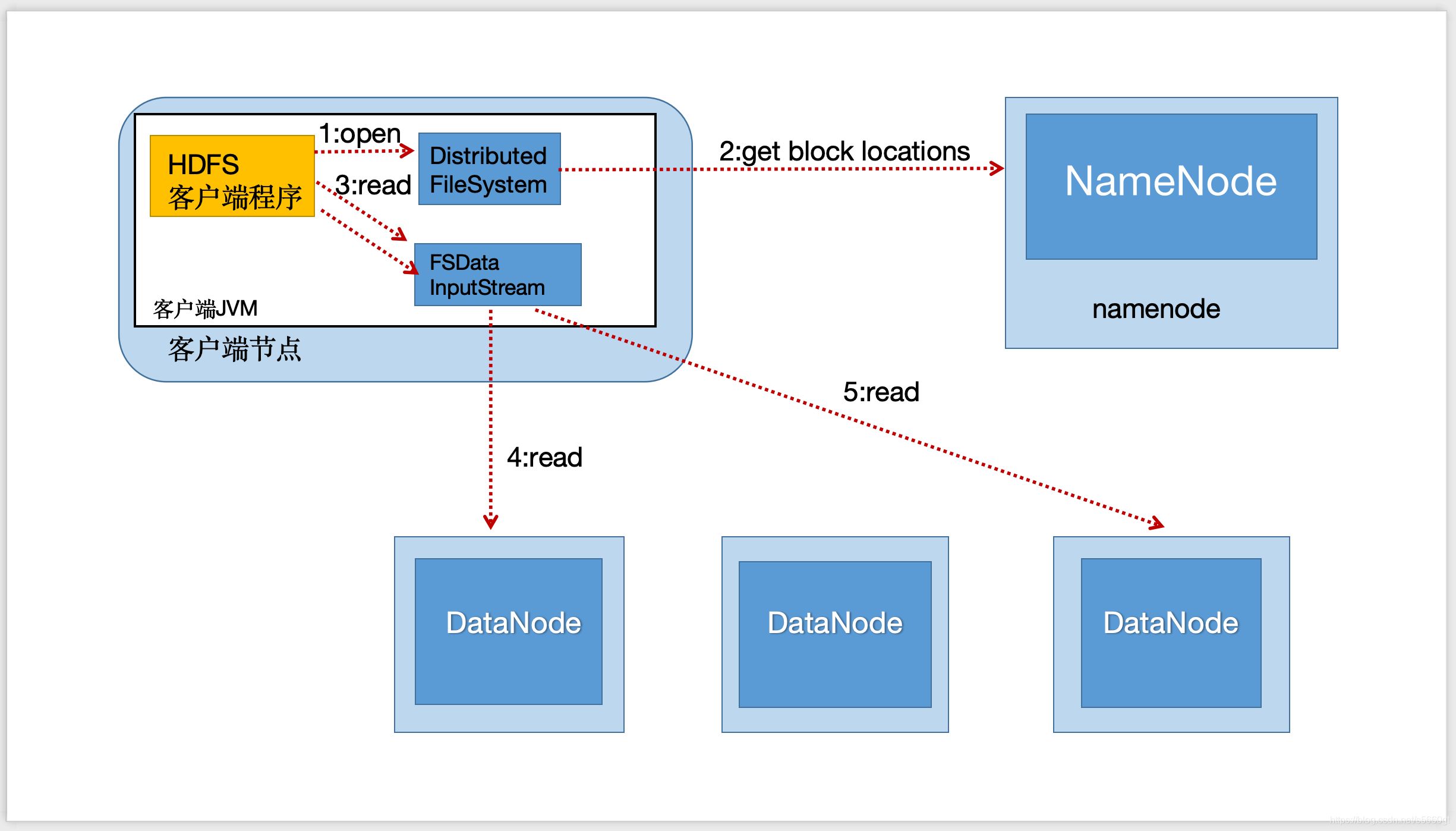
- client向NameNode请求下载文件;
- NameNode查找文件元数据(文件块信息),判断文件是否存在;
- NameNode返回元数据给client;
- client查找DataNode(最近元原则,负载均衡),创建输入流,读取数据;
- 校验数据;
- 关闭输入流。
1.1.4 NN与2NN的工作机制
1.1.4.1 NameNode
- 格式化NameNode后,会生成VERSION(集群版本信息)、镜像文件(fsimage)、seen_txid;
- 如果集群是第一次启动则创建操作日志文件(edits_inprogress);
- 集群启动,NameNode根据seen_txid(存放最新操作日志的标识,一个数字)加载最新操作日志文件(edits_inprogress_01)到内存;
- 元数据的写操作;
- 滚动操作日志,记录操作到操作日志(edits_inprogress_01);
- 当操作日志(edits_inprogress_01)满了,就会生成新的操作日志(edits_inprogress_02),原操作日志改为edits_01;
- 修改内存中的元数据;
1.1.4.2 2NN
- 定时(默认1小时)向NameNode发送请求,询问是否执行CheckPoint;
- 当操作日志(edits_inprogress)满了(默认100W次操作次数),会主动执行CheckPoint;
- Secondary NameNode将镜像文件(如fsimage_01)和操作日志(如edits_01)拷贝过来;
- 根据edits_01修改fsimage_01,生成新的镜像文件fsimage_02;
- 将fsimage_02拷贝到NameNode。
1.1.5 查看fsimage和edits文件
-
fsimage
# 把镜像文件fsimage_0000000000000000000转换为XML格式的文件,输出到/root/fsimage_000.xml hdfs oiv -p XML -i fsimage_0000000000000000000 -o /root/fsimage_000.xml -
edits
# 把操作日志文件edits_inprogress_0000000000000000010转换为XML格式的文件,输出到/root/edits_inprogress_10.xml hdfs oev -p XML -i edits_inprogress_0000000000000000010 -o /root/edits_inprogress_10.xml
1.1.6 DataNode工作机制
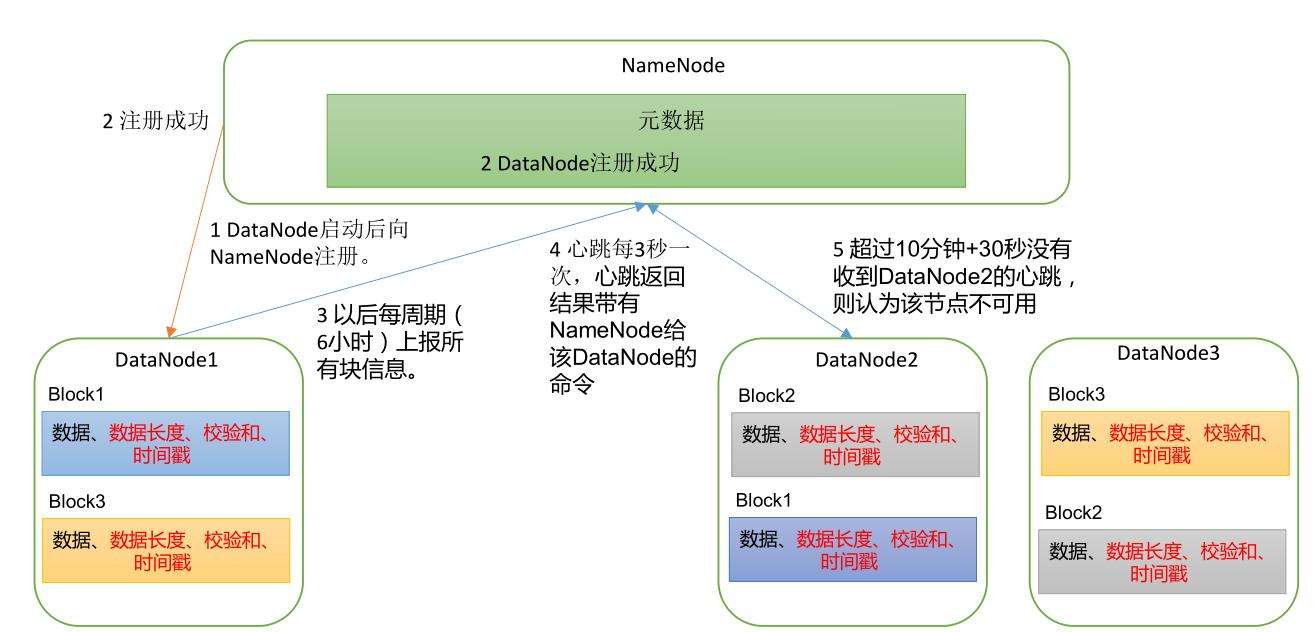
- DataNode启动后,向NameNode注册;
- NameNode返回DataNode,注册成功;
- DataNode周期性向NameNode上报所有块信息;
- 心跳每三秒一次,心跳返回带有NameNode给DataNode的命令;
- 超过10分钟+30秒没有收到DataNode的心跳,则认为该节点不可用。
1.1.7 数据完整性
使用crc32进行校验。
1.2 YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
1.2.1 组成架构
-
ResourceManager(RM):管理整个集群的资源(内存、CPU等),集群中只有一份
- 资源的分配与调度;
- 处理客户端请求;
- 监控NodeManager;
- 启动和监控ApplicationMaster。
-
NodeManager(NM):管理单个节点的资源(内存、CPU等),集群中每个节点都有一个
- 处理ResourceManager的命令;
- 处理ApplicationMaster的命令;
-
ApplicationMaster(AM):管理单个任务的资源(内存、CPU等)
- 为应用程序申请资源并分配给内部烦任务;
- 任务的监控与容错。
-
Container:容器,相当于一台独立的服务器(封装了任务运行所需的资源,如内存、磁盘、CPU、网络等),用来运行任务。单个节点可以开辟多个容器。
1.2.2 工作机制

1.2.3 调度器与调度算法
主要有三种调度器:FIFO(先进先出)、Capacity Scheduler(容量)、Fair Scheduler(公平)调度器。默认调度器是Capacity Scheduler。(CDH框架默认调度器是Fair Scheduler)
1.2.3.1 调度器
- FIFO:先进先出(First In First Out),单队列,根据job的提交顺序来执行;
- Capacity Scheduler:
- 多队列:每个队列配置一定的资源,每个队列内部采用FIFO调度策略;
- 容量保证:管理员可以为每个队列设置资源的上下线,保证每个队列都有任务可以执行;
- 灵活性:如果一个队列的资源有剩余,会暂时借调给其他队列使用;
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一用户提交的job独占队列资源,调度器会对同一用户提交的job所占资源量进行限制。
- Fair Scheduler:
- 多队列:每个队列配置一定的资源,每个队列内部采用Fair调度策略;
- 容量保证:管理员可以为每个队列设置资源的上下线,保证每个队列都有任务可以执行;
- 灵活性:如果一个队列的资源有剩余,会暂时借调给其他队列使用;
- 多租户:支持多用户共享集群和多应用程序同时运行。为了防止同一用户提交的job独占队列资源,调度器会对同一用户提交的job所占资源量进行限制;
- 同队列所有任务共享资源,在时间尺度上获得公平的资源。
1.2.3.2 调度算法
- Capacity Scheduler:
- 队列资源分配:深度优先算法。优先给资源占用率最低的队列分配资源;
- 作业资源分配:先按照job的优先级高的,之后按照提交时间早的;
- 容器资源分配:先按照容器的优先级高的,之后按照数据本地性原则(同一节点 > 同一机架 > 其他机架);
- Fair Scheduler:
- 队列资源分配:先所有队列平分,如果某些队列有多余的资源,则把所有多余的资源给缺少资源的队列平分,直到没有多余的资源或满足所有队列的需求;
- 作业资源分配:
- 不加权:同队列资源分配类似。先所有作业平分资源,如果某些作业有多余的资源则加到一起给缺资源的作业平分;
- 加权:同不加权类似,只是把平分改为按权重占比分配,多余的再给缺资源的按权重占比分配。
- 容器资源分配:
1.2.3.3 资源分配策略
- FIFO策略:先到先得;
- Fair策略:基于最大最小公平算法实现的资源多路复用方式,即同时运行的程序,获得的资源相同;
- DRF策略:Dominant Resource Fairness,在上面调度器中,我们所说的资源,都是只考虑内存,也是Yarn默认的情况。但如果我们需要对内存、CPU、网络带宽等资源进行分配,则使用DRF策略。
1.3 MapReduce
MapReduce是一个分布式运算的编程框架,负责Hadoop的计算。整个计算过程分为Map和Reduce两个阶段。
1.3.1 组成架构
- Map:并行计算
- Reduce:对Map结果进行汇总
1.3.2 优缺点
- 优点
- 易于编程:只要实现框架的接口,编写相关业务逻辑代码;
- 良好的扩展性:可以动态增加服务器,解决计算资源不够的问题;
- 高容错性:任何一台服务器挂掉,可以把任务转移到其他节点;
- 适合海量数据计算(TB/PB)。
- 缺点
- 不擅长实时计算;
- 不擅长流式计算;
- 不擅长DAG有向无环图计算
1.3.3 进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
- MrAppMaster:负责整个程序的过程调度和状态协调;
- MapTask:负责Map阶段的整个数据处理流程;
- ReduceTask:负责Reduce阶段的整个数据处理流程。
1.3.4 常用数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
1.3.5 编程规范
开发编写的主要程序分为Mapper、Reducer、Driver三个部分。
1.3.5.1 Mapper
- 自定义的Mapper类继承org.apache.hadoop.mapreduce.Mapper类;
- Mapper的输入数据是KV键值对的形式,KV的数据类型可自定义;
- 重写org.apache.hadoop.mapreduce.Mapper类的map()方法,写业务逻辑;
- Mapper的输出数据是KV键值对的形式,KV的数据类型可自定义;
- 可以重写setup()和cleanup()方法,进行reduce的前置和后置处理,每个MapTask只会执行一次;
1.3.5.2 Reducer
- 自定义的Reduce类继承org.apache.hadoop.mapreduce.Reducer类;
- Reduce的输入数据是KV键值对的形式,数据类型对应Mapper的输出数据类型;
- 重写org.apache.hadoop.mapreduce.Reducer类的reduce()方法,写业务逻辑;
- 可以重写setup()和cleanup()方法,进行reduce的前置和后置处理,每个ReduceTask只会执行一次;
- 重写reduce()方法时,其中values的迭代器时hadoop专属的简化版。该迭代器只能遍历一次,并且迭代器里面保存的并不是对象本身,而只是内存地址,所以需要copy之后才能转存到其他集合中,
1.3.5.3 Driver
相当于Yarn的客户端,用于提交我们整个程序到Yarn集群,提交的是封装了MapReduce程序相关运行参数的job对象。
- 获取配置信息,获取job对象;
- 指定本程序的jar包所在的本地路径;
- 关联Mapper/Reduce业务类;
- 指定Mapper输出数据的KV类型;
- 指定最终输出的数据的KV类型;
- 指定job的输入原始文件所在目录;
- 指定job的输出结果文件所在目录;
- 提交作业。
1.3.6 数据清洗(ETL)
ETL,是Extract-Transform-Load的缩写,用来描述数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)到目的端的过程。ETL常用在数据仓库,但其对象并不限于数据仓库。
在运行核心业务MapReduce之前,往往需要先对数据进行清洗,清理掉不符合要求的数据。清理过程一般只需要运行Mapper程序,不需要运行Reducer程序。
即在map方法中,只把符合条件的数据写出。
1.3.7 数据压缩
1.3.7.1 优缺点
- 优点:减少磁盘存储空间,减少IO;
- 缺点:增加CPU开销。
1.3.7.2 压缩原则
- 运算密集型任务:少用压缩;
- IO密集型任务:多用压缩。
1.3.7.3 Hadoop压缩算法
| 压缩格式 | Hadoop自带 | 算法 | 扩展名 | 切片 | 压缩对程序的影响 | 压缩效果 | 压缩速度 | 解压速度 | hadoop编码/解码器 |
|---|---|---|---|---|---|---|---|---|---|
| DEFLAT | ✔ | DEFLAT | .deflate | ✘ | 和文本一样处理,无影响 | org.apache.hadoop.io.compress.DeflateCodec | |||
| Gzip | ✔ | DEFLAT | .gz | ✘ | 和文本一样处理,无影响 | 好 | 17.5MB/s | 58MB/s | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | ✔ | bzip2 | .bz2 | ✔ | 和文本一样处理,无影响 | 最好 | 2.4MB/s | 9.5MB/s | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | ✘,需要安装 | LZO | .lzo | ✔ | 需要建索引,指定输入格式 | 一般 | 49.3MB/s | 74.6MB/s | com.hadoop.compression.lzoLzopCodec |
| Snappy | ✔ | Snappy | .snappy | ✘ | 和文本一样处理,无影响 | 一般 | 250MB/s | 500MB/s | org.apache.hadoop.io.compress.SnappyCodec |
1.3.7.4 压缩方式选择
- map输入文件压缩:
- 数据量小于切片大小:考虑压缩、加压速度;
- 数据量非常大:考虑支持切片的。
- map输出文件压缩:
- 考虑压缩与解压速度
- reduce输出文件压缩:
- 保存:考虑压缩效果;
- 作为下一个MapReduce的输入:参考第一点。
1.3.7.5 压缩方式配置
-
map输入文件压缩:
hadoop会根据扩展名使用对应的解压方式,只有使用hadoop默认支持之外的压缩方式,才需要在core-site.xml中配置添加新的压缩方式。或者也可以在Driver类中通过Configuration conf = new Configuration();配置。
-
map输出文件压缩:
map与reduce之间的压缩默认是关闭的,需要在hdfs-site.xml配置开启,默认使用org.apache.hadoop.io.compress.DefaultCodec压缩器。或者也可以在Driver类中通过Configuration conf = new Configuration();配置。
-
reduce输出文件压缩:
reduce之后的压缩默认是关闭的,需要在hdfs-site.xml配置开启,默认使用org.apache.hadoop.io.compress.DefaultCodec压缩器。或者也可以在Driver类中通过Configuration conf = new Configuration();配置。
二 下载安装
Hadoop是用Java写的,所以需要有jdk环境**(注意jdk版本)**
2.1 下载
-
进入官网;

-
选择版本;

-
下载

2.2 安装
-
上传下载的压缩包;
-
解压;
tar -zxvf hadoop-3.3.1.tar.gz rm hadoop-3.3.1.tar.gz -
配置环境变量:
修改/etc/profile或者/etc/profile.d/目录下的自定义.sh文件(如my_env.sh),添加# hadoop环境变量 export HADOOP_HOME=/usr/local/big-data/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
刷新配置
source /etc/profile -
验证,查看Hadoop版本
hadoop version
三 集群搭建
默认配置文件在官网最下面

3.1 修改Hadoop配置
- NameNode、Secondary NameNode、ResourceManager都比较耗内存,建议放在不同节点上
- 在所有节点上修改下面的配置
3.1.1 核心配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/core-site.xml
-
必要配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.10.102:8020</value> <description>配置NameNode所在服务器,NameNode所在节点也是主节点</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/big-data/hadoop-3.3.1/data</value> <description> 配置Hadoop数据的存储目录,存放NameNode和Data数据。默认是一个临时目录 </description> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> <description> 配置HDFS网页使用的静态用户为root,配置为集群启动时使用的Linux用户。 如果不配置,则在web页面无法操作数据 </description> </property> <!-- 回收站 --> <property> <name>fs.trash.interval</name> <value>60</value> <description> 设置文件在回收站的保存时间,默认为0,表示禁用,这里设置为1小时 </description> </property> <property> <name>fs.trash.checkpoint.interval</name> <value>60</value> <description> 设置多久检查一次回收站,是否有文件要删除。默认为0,表示和上面fs.trash.interval保持一致, 该值不能大于上面fs.trash.interval的值。这里设置为1个小时 </description> </property> </configuration> -
可选配置
<configuration> <property> <name>io.compression.codecs</name> <value></value> <description>在hadoop默认支持的基础上,增加新的压缩/解压缩方式</description> </property> </configuration>
3.1.2 HDFS配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/hdfs-site.xml
-
必要配置
<configuration> <property> <name>dfs.namenode.http-address</name> <value>192.168.10.102:9870</value> <description>配置NameNode的web访问地址</description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.10.104:9868</value> <description>配置Secondary NameNode的web访问地址</description> </property> <property> <name>dfs.hosts</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop/whitelist</value> <description> 配置允许连接到NameNode的主机列表的文件(白名单),默认为空,即允许所有主机连接到 NameNode。配置的路径必须是全路径。文件名可自定义 </description> </property> <property> <name>dfs.hosts.exclude</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop/blacklist</value> <description> 配置不允许连接到NameNode的主机列表的文件(黑名单),默认为空,即不限制任何主机连接 到NameNode。配置的路径必须是全路径。文件名可自定义 </description> </property> <!-- 根据集群性能配置 --> <property> <name>dfs.namenode.handler.count</name> <value>21</value> <description> NameNode处理DataNode和客户端请求的线程数,默认10个,三个节点配21个线程 </description> </property> <property> <name>dfs.namenode.handler.count</name> <value>10</value> <description>NameNode处理DataNode和客户端请求的线程数,默认10个</description> </property> </configuration> -
可选配置
<configuration> <!-- 集群监控配置 --> <property> <name>dfs.blockreport.intervalMsec</name> <value>21600000</value> <description> DataNode向NameNode周期性上报的间隔时间,默认6小时(21600000ms) </description> </property> <property> <name>dfs.blockreport.intervalMsec</name> <value>21600s</value> <description> DataNode扫描自己节点块信息的间隔时间,默认6小时(21600s) </description> </property> <!-- 下面两个定义超时(认为节点不可用)时间:2 * 300000ms + 10 * 3s = 10分钟 + 30s。下这里两个为默认值 --> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> <description>NameNode检查DataNode是否有问题的间隔时间</description> </property> <property> <name>dfs.heartbeat.interval</name> <value>3s</value> <description> datanode心跳间隔。可以使用以下后缀(不区分大小写):ms(毫秒)、s(秒)、 m(分钟)、h(小时)、d(天)来指定时间(如2s、2m、1h等)。或者以秒为单位提供 完整的数字(例如30代表30秒)。如果未指定时间单位,则假定为秒。 </description> </property> <!-- 压缩相关配置 --> <property> <name>mapreduce.map.output.compress</name> <value>true</value> <description>开启Map输出结果的压缩,默认false关闭</description> </property> <property> <name>mapreduce.map.output.compress.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>配置Map输出结果的压缩器,默认DefaultCodec</description> </property> <property> <name>mapreduce.output.fileoutputformat.compress</name> <value>true</value> <description>开启reduce输出结果的压缩,默认false关闭</description> </property> <property> <name>mapreduce.output.fileoutputformat.compress.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>配置reduce输出结果的压缩器,默认DefaultCodec</description> </property> <!-- NameNode和DataNode多目录配置 --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value> <description> NameNode数据在本地的保存位置,可以配置多个,提高可靠性。 默认是 file://${hadoop.tmp.dir}/dfs/name 其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置 </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>[SSD]file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value> <description> DataNode数据在本地的保存位置,可以配置多个,多个目录保存的数据不同。 默认是 file://${hadoop.tmp.dir}/dfs/data 其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置. 其中file表示本地文件系统,前面的中括号以及里面配置的SSD表示该目录的存储策略 </description> </property> <!-- 性能调优配置 --> <property> <name>dfs.replication</name> <value>3</value> <description>配置副本数,默认为3。如果有配置纠删码,则副本数只会有1份</description> </property> <property> <name>dfs.storage.policy.enabled</name> <value>true</value> <description>允许用户更改目录的存储策略,默认true</description> </property> </configuration>
3.1.3 YARN配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/yarn-site.xml
-
必要配置
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>指定MapReduce使用shuffle</description> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.10.103</value> <description>配置ResourceManager服务所在的服务器地址或主机名</description> </property> <property> <name>yarn.application.classpath</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop:/usr/local/big-data/hadoop-3.3.1/share/hadoop/common/lib/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/common/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/hdfs:/usr/local/big-data/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/hdfs/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/mapreduce/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/yarn:/usr/local/big-data/hadoop-3.3.1/share/hadoop/yarn/lib/*:/usr/local/big-data/hadoop-3.3.1/share/hadoop/yarn/*</value> <description> 配置yarn任务的环境变量。执行:hadoop classpath 查看获取路径 </description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description> 开启日志聚合功能,将分散在各个节点的日志聚集起来,方便查看,默认false </description> </property> <property> <name>yarn.log.server.url</name> <value>http://192.168.10.102:19888/jobhistory/logs</value> <description>配置日志聚集服务器地址</description> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> <description>配置日志保留时间,默认为-1(禁用),单位:秒</description> </property> <!-- 根据集群中各节点性能配置 --> <property> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>50</value> <description>配置ResourceManager处理调度程序接口的线程数,默认50个</description> </property> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> <description> 是否将虚拟核数当做CPU核数,默认false(各节点CPU不同时开启) </description> </property> <property> <name>yarn.nodemanager.resource.pcores-vcores-multiplier</name> <value>1.0</value> <description> 虚拟核数和物理核数乘数,即将当前节点的物理核数当做几倍的虚拟核数使用,默认1.0 </description> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> <description>NodeManager最多使用系统多少内存,默认(8GB)</description> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> <description>NodeManager最多使用的CPU核数,默认8个</description> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> <description> 容器的最大内存,默认8192MB。 不能小于2G,不然无法申请容器,因为运行单个容器至少1.5G以上 </description> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> <description>容器的最大CPU核数,默认4</description> </property> </configuration> -
可选配置
<configuration> <!-- ResourceManager --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> <description> 配置资源调度器,默认CapacityScheduler,并发要求高则选择公平调度器 </description> </property> <!-- NodeManager --> <property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> <description>是否让yarn对节点内存、CPU等进行自动检测,默认false</description> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> <description>是否对容器实施物理内存限制。默认true</description> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>true</value> <description>是否对容器强制执行虚拟内存限制。默认true</description> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> <description>设置容器的内存限制时,虚拟内存与物理内存之间的比率。默认2.1</description> </property> <!-- Container --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> <description>容器的最小内存,默认1024MB</description> </property> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> <description>容器的最小CPU核数,默认1</description> </property> <property> <name>yarn.cluster.max-application-priority</name> <value>0</value> <description> 配置集群中任务的最高优先级,即任务的优先级有几级。默认0,即没有优先级差别,都相同 </description> </property> </configuration>
3.1.4 MapReduce配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/mapred-site.xml
-
必要配置
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>指定MapReduce运行在YARN上。默认本地</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.10.102:10020</value> <description> 配置历史服务器地址。 历史服务器:用来查看程序的历史运行情况 </description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.10.102:19888</value> <description>配置历史服务器的web端地址</description> </property> </configuration> -
可选配置
<configuration> <property> <name>mapreduce.task.io.sort.mb</name> <value>100</value> <description>环形缓冲区大小,默认100MB</description> </property> <property> <name>mapreduce.map.sort.spill.percent</name> <value>0.80</value> <description>环形缓冲区溢写阈值,默认0.80</description> </property> <property> <name>mapreduce.task.io.sort.factor</name> <value>10</value> <description>一次merge的文件数,默认10个</description> </property> <property> <name>mapreduce.map.memory.mb</name> <value>-1</value> <description>MapTask内存,默认1G。</description> </property> <property> <name>mapreduce.map.cpu.vcores</name> <value>1</value> <description>MapTask的CPU核数,默认1个</description> </property> <property> <name>mapreduce.map.maxattempts</name> <value>4</value> <description>MapTask任务失败重试次数,默认4次</description> </property> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>5</value> <description>ReduceTask去Map拉取数据的并行数。默认5</description> </property> <property> <name>mapreduce.reduce.shuffle.input.buffer.percent</name> <value>0.7</value> <description>Buffer占ReduceTask内存的比例,默认0.7</description> </property> <property> <name>mapreduce.reduce.shuffle.merge.percent</name> <value>0.66</value> <description> 当ReduceTask中Buffer占总内存的百分比达到阈值,就会开启merge合并,默认0.66 </description> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>-1</value> <description>ReduceTask内存,默认1G</description> </property> <property> <name>mapreduce.reduce.cpu.vcores</name> <value>1</value> <description>ReduceTask,默认1个</description> </property> <property> <name>mapreduce.reduce.maxattempts</name> <value>4</value> <description>ReduceTask失败的重试次数,默认4次</description> </property> <property> <name>mapreduce.job.reduce.slowstart.completedmaps</name> <value>0.05</value> <description>当MapTask完成的比例达到该值才会为ReduceTask申请资源,默认0.05</description> </property> <property> <name>mapreduce.task.timeout</name> <value>600000</value> <description>apReduce任务超时时间,默认10分钟。</description> </property> <!-- uber模式配置 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> <description>开启uber模式,默认false</description> </property> <property> <name>mapreduce.job.ubertask.maxmaps</name> <value>9</value> <description>uber模式中MapTask的最大数量,默认9个,只能调小</description> </property> <property> <name>mapreduce.job.ubertask.maxreduces</name> <value>1</value> <description>uber模式中ReduceTask的最大数量,默认1个,只能调小</description> </property> <property> <name>mapreduce.job.ubertask.maxbytes</name> <value></value> <description>uber模式中最大的输入数据量,默认为块大小,只能改小</description> </property> </configuration>
3.1.5 集群工作节点配置
配置文件路径:hadoop-3.3.1/etc/hadoop/workers。
添加集群所有主机名(加入集群启动、停止等命令的操作范围)
hadoop102
hadoop103
hadoop104
3.2 集群机器的配置
-
配置集群间ssh免密登录
# 生成秘钥,三次回车 ssh-keygen -t rsa # 分发公钥到集群其他所有(包括自己)机器 ssh-copy-id 192.168.10.102 ssh-copy-id 192.168.10.103 ssh-copy-id 192.168.10.104 -
配置启动用户:添加环境 变量
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
配置主机名与IP的映射关系:vim /etc/hosts
192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 -
关闭防火墙:hadoop集群有许多内部通信端口和外部查询端口
systemctl stop firewalld systemctl disable firewalld -
集群时间同步:如果集群无法连接外网,为了使集群所有节点的时间保持一致,需要配置所有节点的时间,以其中一个节点的时间为准,进行同步
yum install ntp -y # 安装ntp systemctl status ntpd systemctl start ntpd systemctl is-enabled ntpd # 查看ntpd是否开机自启动 systemctl enable ntpd # 开启ntpd开机自启动以192.168.10.102节点为时间服务器,则需要安装ntp,设置为开机自启动并开启,修改配置文件:vim /etc/ntp.conf
# 当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步 server 127.127.1.0 fudge 127.127.1.0 stratum 10

让硬件时间与系统时间同步,修改配置文件:vim /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes其他节点需要关闭ntp并关闭ntp的开机自启动,或直接卸载ntp:
yum remove ntp -y # 卸载ntp systemctl stop ntpd # 关闭ntpd systemctl disable ntpd # 关闭ntpd的开机自启动编写定时任务,每分钟与时间服务器192.168.10.102同步一次时间:
# 创建定时任务 crontab -e # 定时任务内容:每分钟与192.168.10.102服务器同步一次时间 */1 * * * * /usr/sbin/ntpdate 192.168.10.102
3.3 单节点启动
根据Hadoop配置文件所配置的IP,在对应机器上机器上启动
3.3.1 启动HDFS
启动HDFS,总共会启动NameNode、DataNode、Secondary NameNode三类服务。有需要时也可以单独启动:
hdfs --daemon start namenode hdfs --daemon start datanode hdfs --daemon start secondarynamenode
-
格式化集群:如果是第一次启动,需要格式化NameNode,在配置NameNode所在机器上执行
hdfs namenode -format查看集群版本号

如果不是刚搭建好集群的时候,要格式化集群,需要先删除历史数据,即hadoop根目录下的data和logs文件夹。
-
启动集群
sbin/start-dfs.sh
-
查看进程是否启动
jps -
查看HDFS的web页面:为HDFS配置文件中指定NameNode地址,192.168.10.102:9870

3.3.2 启动YARN
启动YARN,会启动ResourceManager、NodeManager两类服务。有需要时也可以单独启动:
yarn --daemon start resourcemanager yarn --daemon start nodemanager
-
会启动ResourceManager和NodeManager两个进程
sbin/start-yarn.sh
-
查看ResourceManager的web页面:IP为YARN配置文件中ResourceManager的配置地址,端口为8088

3.3.3 启动历史服务
mapred --daemon start historyserver

3.4 测试
-
创建文件夹
# 在根目录下创建文件夹input hadoop fs -mkdir /input
-
上传文件、文件夹
# 创建文件work.txt vim word.txt # 上传文件work.txt到/input路径下 hadoop fs -put word.txt /input
-
web页面查看文件:
需要在浏览器所在主机配置集群中所有主机名与IP的映射关系
Windows修改:C:\Windows\System32\drivers\etc/hosts

-
计算:
-
集群情况下的文件路径是HDFS,并不是指Linux上的路径;
-
输出路径不能是已存在的目录
# 统计/input/word.txt中单词的个数,输出到/output目录下 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount \ /input/word.txt /output




-
3.5 单节点关闭
根据Hadoop配置文件所配置的IP,在对应机器上机器上关闭
-
关闭历史服务器
mapred --daemon stop historyserver -
关闭YARN
sbin/stop-yarn.sh -
关闭HDFS
sbin/stop-dfs.sh
3.6 脚本启动/关闭集群
脚本可以放在当前账号的bin目录下,比如root用户可以把脚本放在:/root/bin/
3.6.1 myhadoop
在/root/bin目录下,创建文件myhadoop
#!/bin/bash
if [ $# -ne 1 ]
then
echo "请输入一个参数:start(开启集群)、stop(关闭集群)、format(格式化集群)"
exit;
fi
case $1 in
"start")
echo "===== 开始启动Hadoop集群 ====="
echo "===== 正在启动HDFS ====="
ssh 192.168.10.102 "/usr/local/big-data/hadoop-3.3.1/sbin/start-dfs.sh"
echo "===== 正在启动YARN ====="
ssh 192.168.10.103 "/usr/local/big-data/hadoop-3.3.1/sbin/start-yarn.sh"
echo "===== 正在启动历史服务 ====="
ssh 192.168.10.102 "/usr/local/big-data/hadoop-3.3.1/bin/mapred --daemon start historyserver"
echo "===== Hadoop集群启动成功! ====="
;;
"stop")
echo "===== 开始关闭Hadoop集群 ====="
echo "===== 正在关闭历史服务 ====="
ssh 192.168.10.102 "/usr/local/big-data/hadoop-3.3.1/bin/mapred --daemon stop historyserver"
echo "===== 正在关闭YARN ====="
ssh 192.168.10.103 "/usr/local/big-data/hadoop-3.3.1/sbin/stop-yarn.sh"
echo "===== 正在关闭HDFS ====="
ssh 192.168.10.102 "/usr/local/big-data/hadoop-3.3.1/sbin/stop-dfs.sh"
echo "===== Hadoop集群关闭完成! ====="
;;
"format")
echo "===== 开始格式化Hadoop集群 ====="
myhadoop stop
echo "===== 正在删除数据和日志文件夹 ====="
ssh 192.168.10.102 "rm -rf /usr/local/big-data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
ssh 192.168.10.103 "rm -rf /usr/local/big-data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
ssh 192.168.10.104 "rm -rf /usr/local/big-data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
echo "===== 正在格式化集群 ====="
ssh 192.168.10.102 "hdfs namenode -format"
echo "===== Hadoop集群格式化成功! ====="
;;
*)
echo "未知的参数,请输入一个参数:start(开启集群)、stop(关闭集群)、format(格式化集群)"
;;
esac
# 授权myhadoop可执行权限
chmod a+x /root/bin/myhadoop
# 启动集群
myhadoop start
# 关闭集群
myhadoop stop
# 格式化集群
myhadoop format
3.6.2 jpsall
在/root/bin目录下,创建文件jpsall
#!/bin/bash
for ip in 192.168.10.102 192.168.10.103 192.168.10.104
do
echo "===== $ip ====="
ssh $ip jps
done
# 授权jpsall可执行权限
chmod a+x /root/bin/jpsall
# 查看整个集群各个服务的启动情况
jpsall
3.6.3 分发脚本
同来同步集群之间的文件或文件夹。
前提:需要安装rsync
yum install rsync -y在在/root/bin目录下,创建文件xsync
#!/bin/bash
# 1. 判断参数个数
if [ $# -lt 1 ]
then
echo "参数个数少于一个!"
exit;
fi
# 2. 遍历要分发的机器
for host in 192.168.10.102 192.168.10.103 192.168.10.104
do
echo "===== 当前分发到服务器:$host ====="
# 3. 遍历所有参数,挨个分发
for arg in $@
do
# 4. 判断文件是否存在
if [ -e $arg ]
then
# 5. 获取父目录
pdir=$(cd -P $(dirname $arg); pwd)
# 6. 获取当前文件的名称
filename=$(basename $arg)
# 7. 连接当前机器,创建父目录
ssh $host "mkdir -p $pdir"
# 8. 同步文件
rsync -av $pdir/$filename $host:$pdir
else
echo "===== 当前文件或文件夹不存在不存在 ====="
fi
done
done
echo "=====全部同步完成====="
# 授权xsync可执行权限
chmod a+x /root/bin/xsync
# 分发文件或文件夹
xsync /root/bin
四 常用shell命令
4.1 HDFS
4.1.1 文件操作
hadoop fs 和 hadoop dfs 是一样的。
# 在根目录下创建一个input文件夹
hadoop fs -mkdir /input
# 把本地文件word.txt移动到HDFS的/input目录下
hadoop fs -moveFromLocal word.txt /input
# 把本地文件word.txt复制到HDFS的/input目录下
hadoop fs -copyFromLocal word.txt /input
# 把本地文件word.txt上传到HDFS的/input目录下,等同于-copyFromLocal
hadoop fs -put word.txt /input
# 把本地文件word.txt追加到HDFS的/input/word.txt文件后面
hadoop fs -appendToFile word.txt /input/word.txt
# 把HDFS的/input/word.txt文件复制到本地当前目录下
hadoop fs -copyToLocal /input/word.txt ./
# 把HDFS的/input/word.txt文件拉取到本地当前目录下,等同于-copyToLocal
hadoop fs -get /input/word.txt ./
# 查看HDFS的/input目录
hadoop fs -ls /input
# 查看HDFS的/input/word.txt文件的内容
hadoop fs -cat /input/word.txt
# 查看HDFS的文件/input/word.txt的最后1kb的数据
hadoop fs -tail /input/word.txt
# 查看HDFS的/input目录的大小(单位:B)
hadoop fs -du -s -h /input
# 查看HDFS的/input目录下每个文件或文件夹的大小(单位:B)
hadoop fs -du -h /input
# 修改HDFS的/input/word.txt文件权限
hadoop fs -chmod 666 /input/word.txt
hadoop fs -chown root:root /input/word.txt
hadoop fs -chgrp root /input/word.txt
# 设置HDFS中文件/input/word.txt的副本数为10
hadoop fs -setrep 10 /input/word.txt
# 把HDFS的文件/input/word.txt复制到HDFS的根目录下
hadoop fs -cp /input/word.txt /
# 把HDFS的文件/input/word.txt移动到HDFS的根目录下
hadoop fs -mv /input/word.txt /
# 删除HDFS的/word.txt文件
hadoop fs -rm /word.txt
# 删除HDFS的/input文件夹
hadoop fs -rm -r /input
# 查看文件块的信息,可以看到:文件大小、纠删码策略或副本数、存储类型等
hdfs fsck <path> -files -blocks -locations
# 让HDFS按照存储策略移动 /input
hdfs mover /input
4.1.2 NameNode操作
# 刷新NameNode节点
hdfs dfsadmin -refreshNodes
4.1.3 均衡计划
# 生成均衡计划
hdfs diskbalancer -plan hadoop103
# 执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
# 查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
# 取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
4.1.4 纠删码
# 查看所有纠删码策略
hdfs ec -listPolicies
# 启用RS-3-2-1024k策略
hdfs ec -enablePolicy -policy RS-3-2-1024k
# 将 /input 设置为 RS-3-2-1024k 策略
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
4.1.5 存储策略
# 查看当前可用的存储策略
hdfs storagepolicies -listPolicies
# 为指定路径设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
# 获取指定路径的存储策略
hdfs storagepolicies -getStoragePolicy -path <path>
# 撤销指定路径的存储策略
hdfs storagepolicies -unsetStoragePolicy -path <path>
4.1.6 安全模式
# 查看安全模式状态
hdfs dfsadmin -safemode get
# 进入安全模式状态
hdfs dfsadmin -safemode enter
# 离开安全模式状态
hdfs dfsadmin -safemode leave
# 等待安全模式状态。脚本中进入等待状态后,后面的操作会在解除安全模式之后马上执行
hdfs dfsadmin -safemode wait
4.1.7 HAR文件操作
# 把 /input 目录下的文件打包为一个叫做 input.har 的文件,输出到 /output 目录下。底层为MapReduce
hadoop archive -archiveName input.har -p /input /output
# 查看har
hadoop fs -ls har:///output/input.har
hadoop fs -cat har:///output/input.har/word1.txt
# 恢复到根目录
hadoop fs -cp har:///output/input.har/word1.txt /
4.2 MapReduce
# 查看hadoop默认支持的压缩与解压方式
hadoop checknative
4.3 Yarn
4.3.1 节点
# 查看所有节点:Node-Id | Node-State | Node-Http-Address | Number-of-Running-Containers
yarn node -list -all
4.3.2 队列
# 加载队列配置
yarn rmadmin -refreshQueues
# 根据队列名称(默认队列名称:default)查看队列状态
yarn queue -status default
4.3.3 任务
# 查看任务的情况:Application-Id | Application-Name | Application-Type | User | Queue | State | Final-State | Progress | Tracking-URL
yarn application -list
# 根据任务状态查看任务,状态有:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED
yarn application -list -appStates FINISHED
# 根据任务ID修改已提交任务的优先级
yarn application -appID application_1642830982994_0003 -updatePriority 5
# 根据任务ID(Application-Id)杀死任务
yarn application -kill application_1642688446288_0003
# 查看尝试任务:ApplicationAttempt-Id | State | AM-Container-Id | Tracking-URL
yarn applicationattempt -list application_1642688446288_0003
# 根据尝试任务ID(ApplicationAttempt-Id)查看尝试任务的状态
yarn applicationattempt -status appattempt_1642688446288_0003_000001
# 根据任务ID(Application-Id)查看任务日志
yarn logs -applicationId application_1642688446288_0003
4.3.4 容器
# 根据尝试任务ID(ApplicationAttempt-Id)查看容器的情况:Container-Id | Start Time | Finish Time | State | Host | Node Http Address | LOG-URL
yarn container -list appattempt_1642688446288_0003_000001
# 根据容器ID(containerId)查看容器状态(只有在任务执行过程中才能查看容器状态)
yarn container -status container_1642688446288_0003_01_000001
# 根据任务ID(Application-Id)和容器ID(containerId)查看容器日志
yarn logs -applicationId application_1642688446288_0003 \
-containerId container_1642688446288_0003_01_000001
yarn logs -applicationId appattempt_1643279145621_0001_000002 \
-containerId container_e04_1643279145621_0001_02_000001
4.4 集群操作
# 集群数据迁移,hadoop102和hadoop105为两个集群的NameNode地址
hadoop distcp hdfs://hadoop102:8020/input hdfs://hadoop105:8020/input
4.5 高可用集群操作
-
HDFS
# 各个节点启动JournalNode服务 hdfs --daemon start journalnode # 在其他节点上,同步NameNode元数据 hdfs namenode -bootstrapStandby # 查看节点nn3的状态(active、standby) hdfs haadmin -getServiceState nn3 # 将nn1切换为active(前提:所有NameNode处于启动状态) hdfs haadmin -transitionToActive nn1 # 初始化ZKFC hdfs zkfc -formatZK # 进入Zookeeper客户端,查看当前的active的节点 zkCli.sh get -s /hadoop-ha/mycluster/ActiveStandbyElectorLock -
YARN
# 查看rm1的状态(active、standby) yarn rmadmin -getServiceState rm1
五 案例
5.1 Windows开发环境配置
-
从github下载winutils包;

-
复制最新版到自定义目录下

-
运行winutils.exe,验证环境,看是否有报错

-
配置环境变量HADOOP_HOME:D:\DevelopTools\hadoop\hadoop-3.0.0

-
添加到path:%HADOOP_HOME%\bin

5.2 maven配置
maven版本与hadoop集群保持一致
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.1</version>
</dependency>
<build>
<plugins>
<!-- 打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 带依赖打包 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
5.3 HDFS
5.3.1 java客户端操作HDFS
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
/**
* hdfs客户端测试类
*
* @data 2022-01-09 21:40
*/
@Slf4j
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
URI uri = new URI("hdfs://192.168.10.102:8020");
// 配置优先级:代码 > 项目resource配置 > site配置 > default配置
Configuration configuration = new Configuration();
// 配置副本数
configuration.set("dfs.replication", "1");
String user = "root";
fs = FileSystem.get(uri, configuration, user);
}
@After
public void close() throws IOException {
fs.close();
}
/**
* 创建文件夹
*
* @throws IOException IOException
*/
@Test
public void mkdir() throws IOException {
fs.mkdirs(new Path("/xiyou"));
}
/**
* 上传文件
*
* @throws IOException IOException
*/
@Test
public void put() throws IOException {
// 是否删除本地源文件
boolean delSrc = false;
// 是否覆盖HDFS的目标文件
boolean overwrite = true;
// 本地源文件路径
Path srcPath = new Path("F:\\word.txt");
// HDFS目标文件夹路径
Path dstPath = new Path("/input");
fs.copyFromLocalFile(delSrc, overwrite, srcPath, dstPath);
}
/**
* 下载文件
*
* @throws IOException IOException
*/
@Test
public void get() throws IOException {
// 是否删除HDFS中的源文件
boolean delSrc = false;
// 要下载的HDFS中的源文件路径
Path srcPath = new Path("/input");
// 下载到本地的保存路径
Path dstPath = new Path("F:\\");
// 是否进行crc校验,校验文件是否有问题(缺失等),false为校验
boolean useRawLocalFileSystem = false;
fs.copyToLocalFile(delSrc, srcPath, dstPath, useRawLocalFileSystem);
}
/**
* 删除
*
* @throws IOException IOException
*/
@Test
public void rm() throws IOException {
// 要删除的文件或文件夹路径
Path delPath = new Path("/input");
// 是否递归删除
boolean recursive = true;
fs.delete(delPath, recursive);
}
/**
* HDFS内移动与重命名文件或文件夹
*
* @throws IOException IOException
*/
@Test
public void mv() throws IOException {
// 原路径
Path srcPath = new Path("/word.txt");
// 目标路径。文件夹必须已存在
Path dstPath = new Path("/input/word1.txt");
fs.rename(srcPath, dstPath);
}
/**
* 查看HDFS内文件信息
*
* @throws IOException IOException
*/
@Test
public void ls() throws IOException {
// 路径
Path path = new Path("/");
// 是否递归查找
boolean recursive = true;
RemoteIterator<LocatedFileStatus> files = fs.listFiles(path, recursive);
while (files.hasNext()) {
LocatedFileStatus fileStatus = files.next();
log.info(fileStatus.getPath().toString());
// 权限
log.info(fileStatus.getPermission().toString());
log.info(fileStatus.getOwner());
log.info(fileStatus.getGroup());
// 文件大小
log.info(String.valueOf(fileStatus.getLen()));
log.info(String.valueOf(fileStatus.getModificationTime()));
// 副本数
log.info(String.valueOf(fileStatus.getReplication()));
// 块大小
log.info(String.valueOf(fileStatus.getBlockSize()));
// 文件名称
log.info(fileStatus.getPath().getName());
// 块信息
log.info(Arrays.toString(fileStatus.getBlockLocations()));
}
}
/**
* 查看文件状态
*
* @throws IOException IOException
*/
@Test
public void fileStatus() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
log.info(fileStatus.toString());
}
}
}
5.3.2 HDFS-核心参数配置
5.3.2.1 NN和DN内存配置
每个文件块大概占用NameNode的150byte内存,所以不适合存储大量小文件,因为一个不到128MB(默认块大小)的文件,也会占用NameNode中150B的内存。
如果没有手动设置,将自动缩放内存大小;
-
查看NameNode和DataNode当前占用的内存:
jps # 查看所有正在运行的java进程以及进程ID jmap -heap 进程ID # 根据进程ID查看java进程的堆信息 -
NameNode内存设置标准:
- 最小1GB;
- 每增加100W个block,就增加1GB内存;
-
DataNode内存设置标准:
- 最小设置4GB;
- 一个DataNode上的总副本数低于400W,调为4G,每增加100W,增加1G内存;
-
内存配置:修改配置文件hadoop-3.3.1/etc/hadoop/hadoop-env.sh
# 配置NameNode内存为1G export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m" # 配置DataNode内存为4G export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx4096m"
5.3.2.2 NN心跳并发配置
配置NameNode处理client和DataNode的请求的线程数,默认为10个。
-
配置标准:其中s为节点个数
d f s . n a m e n o d e . h a n d l e r . c o u n t = 20 × lg s dfs.namenode.handler.count = 20 \times \lg^s dfs.namenode.handler.count=20×lgs -
配置:修改hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.handler.count</name> <value>21</value> <description> NameNode处理DataNode和客户端请求的线程数,默认10个,三个节点配21个线程 </description> </property> </configuration>
5.3.2.3 开启回收站功能
-
配置回收站:hadoop-3.3.1/etc/hadoop/core-site.xml
<configuration> <property> <name>fs.trash.interval</name> <value>60</value> <description> 设置文件在回收站的保存时间,默认为0,表示禁用,这里设置为1小时 </description> </property> <property> <name>fs.trash.checkpoint.interval</name> <value>60</value> <description> 设置多久检查一次回收站,是否有文件要删除。默认为0,表示和上面fs.trash.interval保持一致, 该值不能大于上面fs.trash.interval的值。这里设置为1个小时 </description> </property> </configuration> -
查看回收站:回收站路径在HDFS的/user/root/.Trash/Current目录下(其中root是用户名)
-
删除后进入回收站的情况:
- 只有通过命令删除的文件才会进入回收站;
- 通过web页面删除的文件不进入回收站;
- 通过程序删除的文件(需要通过 new Trash(conf).moveToTrash(new Path("")); 才行);
-
回收站数据恢复:找到要恢复的数据的路径,通过cp命令复制到原来的路径下。(数据在回收站中会保留原来的目录结构:如删除/input目录下word.txt文件,在回收站中也会保存在/user/root/.Trash/Current/input/word.txt)
5.3.3 HDFS-集群压测
上传数据到HDFS、或从HDFS上拉取数据的速度是非常重要的指标,所以我们需要通过压测来明确集群的读写性能。
集群的读写性能主要受网络传输速度和磁盘读写速度的影响。
5.3.3.1 写性能压测
# 向HDFS集群写10个128MB的文件,测试集群的写性能
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
TestDFSIO -write -nrFiles 10 -fileSize 128MB
# 运行结果
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Date & time: Sat Jan 22 21:20:53 CST 2022
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Number of files: 10
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Total MBytes processed: 1280
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Throughput mb/sec: 27.03
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Average IO rate mb/sec: 33.24
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: IO rate std deviation: 14.12
2022-01-22 21:20:53,637 INFO fs.TestDFSIO: Test exec time sec: 118.63
2022-01-22 21:20:53,637 INFO fs.TestDFSIO:
5.3.3.2 读性能压测
# 向HDFS集群写10个128MB的文件,测试集群的写性能
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
TestDFSIO -read -nrFiles 10 -fileSize 128MB
# 运行结果
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Date & time: Sat Jan 22 21:25:06 CST 2022
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Number of files: 10
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Total MBytes processed: 1280
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Throughput mb/sec: 101.92
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Average IO rate mb/sec: 227.12
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: IO rate std deviation: 184.52
2022-01-22 21:25:06,971 INFO fs.TestDFSIO: Test exec time sec: 80.84
2022-01-22 21:25:06,971 INFO fs.TestDFSIO:
5.3.4 HDFS-多目录
5.3.4.1 NameNode多目录
NameNode多目录,即在本地配置多个目录保存NameNode的数据,每个目录中数据相同,可以提高可靠性。
多目录配置都是在刚搭建集群的时候配置,否则后面配置后需要格式化集群。
配置文件:hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
<description>
NameNode数据在本地的保存位置,可以配置多个,提高可靠性。
默认是 file://${hadoop.tmp.dir}/dfs/name
其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置
</description>
</property>
</configuration>
5.3.4.2 DataNode多目录
DataNode本地保存数据的目录可以配置多个,和NameNode的多目录不同的是,DataNode多个目录之间保存的数据是不同的。而一般我们配置DataNode多目录都是因为磁盘空间不够用了,新增硬盘的类型可能和原来的不同,这时我们还可以指定存储策略
配置文件:hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file://${hadoop.tmp.dir}/dfs/data1,[RAM_DISK]file://${hadoop.tmp.dir}/dfs/data2</value>
<description>
DataNode数据在本地的保存位置,可以配置多个,多个目录保存的数据不同。
默认是 file://${hadoop.tmp.dir}/dfs/data
其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置.
其中file表示本地文件系统,前面的中括号以及里面配置的SSD表示该目录的存储类型。
</description>
</property>
</configuration>
5.3.4.3 磁盘数据均衡
一般我们配置DataNode多目录都是因为磁盘空间不够用了,新增磁盘后配置。而这时其他磁盘满了,新磁盘还是空的,数据不均衡,我们可以执行均衡任务,平衡各磁盘的数据。(3.X特性)
# 生成均衡计划
hdfs diskbalancer -plan hadoop103
# 执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
# 查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
# 取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
5.3.5 HDFS-集群扩容和缩容
5.3.5.1 配置黑白名单
白名单的主机IP地址都可以访问集群,可以用来存储数据。
没在白名单的节点,可以访问集群,但是不能存储数据(相当于客户端)。
黑名单中的主机IP不能用来存储数据。
-
创建白名单和黑名单:在NameNode所在节点的 hadoop-3.3.1/etc/hadoop目录下,新建whitelist(白名单)和blacklist(黑名单),在里面放入IP或域名,文件名随意。
-
配置使用白名单和黑名单:hadoop-3.3.1/etc/hadoop/hdfs-site.xml
第一次配置必须重启集群,不是第一次则只需要刷新NameNode节点即可。
<configuration> <property> <name>dfs.hosts</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop/whitelist</value> <description> 配置允许连接到NameNode的主机列表的文件(白名单),默认为空,即允许所有主机连接到 NameNode。配置的路径必须是全路径。 </description> </property> <property> <name>dfs.hosts.exclude</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop/blacklist</value> <description> 配置不允许连接到NameNode的主机列表的文件(黑名单),默认为空,即不限制任何主机连接 到NameNode。配置的路径必须是全路径。 </description> </property> </configuration> -
刷新NameNode节点:
hdfs dfsadmin -refreshNodes
5.3.5.2 扩容(新增节点)
- 修改IP、主机名、主机名与IP的映射;
- 关闭新节点的防火墙,禁止防火墙开机自启动;
- 复制旧节点的jdk、hadoop到新节点;
- 复制旧节点的环境变量到新节点;
- 在新节点刷新配置(source /etc/profile),验证java、hadoop是否配置成功;
- 配置新节点与老节点的ssh免密连接;
- 在白名单、hadoop-3.3.1/etc/hadoop/workers中加入新节点,分发到所有节点(没有则需要新增与配置,更安全);
- 删除新节点的hadoop中data和logs两个文件夹;
- 单点启动新节点(DataNode、NodeManager);
- 刷新节点(在NameNode所在节点执行:hdfs dfsadmin -refreshNodes)。
5.3.5.3 节点间数据均衡
新增节点后,平衡各节点保存的数据。
当然,也不一定要新增节点,才能平衡各节点数据。因为提交数据的就近原则,执行任务多的节点,存储的数据会更多,所以各节点之间的数据始终是不均衡的。
由于数据均衡命令会启动一个单独的Rebalance Server,所以应该在比较闲的节点执行。
-
开启数据均衡:
# 参数10,表示集群间各节点的磁盘利用率相差不超过10% sbin/start-balancer.sh -threshold 10 -
停止数据均衡:
sbin/stop-balancer.sh
5.3.5.4 缩容(减少节点)
黑名单中的服务器是不可以用来存储数据的,并且黑名单的权限比白名单要高,所以可以用黑名单来退役旧服务器,达到缩容的目的。
-
将退役节点加入黑名单(没有则需要新增与配置);
-
分发配置文件;
-
刷新NameNode节点(第一次添加黑名单需要重启集群);


-
执行节点数据均衡;
-
停止退役节点的服务(单节点停止)。
5.3.6 纠删码
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但同时也多出了两倍的开销。Hadoop3.X引入了纠删码,采用计算的方式,可以节省约50%左右的存储开销。但会加大CPU的计算开销。
5.3.6.1 纠删码策略
纠删码策略作用范围是HDFS系统的单个目录,这个目录下的数据会执行对应的纠删码策略。
- RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,每个单元的大小为1024KB。只要5个单元中有任意3个或以上单元存在,就可以得到原始数据。默认停用。
- RS-10-4-1024k:使用RS编码,每10个数据单元,生成4个校验单元,每个单元的大小为1024KB。只要14个单元中有任意10个或以上单元存在,就可以得到原始数据。默认停用。
- RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,每个单元的大小为1024KB。只要9个单元中有任意6个或以上单元存在,就可以得到原始数据。默认启用。
- RS-LEGACY-6-3-1024k:使用RS-LEGACY编码,每6个数据单元,生成3个校验单元,每个单元的大小为1024KB。只要9个或以上单元中有任意6个单元存在,就可以得到原始数据。默认停用。
- XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,每个单元的大小为1024KB。只要3个单元中有任意2个或以上单元存在,就可以得到原始数据。默认停用。
5.3.6.2 案例
将/input目录设置为RS-3-2-1024k策略。
# 查看所有纠删码策略
hdfs ec -listPolicies
# 启用RS-3-2-1024k策略
hdfs ec -enablePolicy -policy RS-3-2-1024k
# 创建路径 /input
hadoop fs -mkdir /input
# 将 /input 设置为 RS-3-2-1024k 策略
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
上传大于2MB的文件后,查看副本数为1,但数据存在5个节点。可见设置成功了。
5.3.7 异构存储
异构存储,又叫冷热数据(是否经常使用)分离,是把不同的数据,以不同的存储类型保存,达到性能高、又实惠的状态。如把经常使用的数据(热数据)放到固态硬盘(读写性能好,价格贵)中,把不怎么使用的数据(冷数据)放到机械硬盘(读写性能差,价格便宜)中。
和纠删码不同的是,异构存储配置的是数据在本地的存储策略。由于数据在本地的存储是可以配置多目录的,所以可以为每个目录配置单独的存储策略。而如果各个节点的磁盘组成不同,那么各个节点的异构存储策略的配置也不相同。
5.3.7.1 存储类型&策略
-
存储类型:
- RAM_DISK:内存镜像文件系统;
- SSD:固态硬盘;
- DISK:普通磁盘。在HDFS中,没有主动声明目录存储类型的默认都是DISK;
- ARCHIVE:没有特指哪种存储介质,而是泛指计算能力低而存储密度高的存储介质。用来解决数据量的容量扩增的问题,一般用于归档。
-
存储策略:
策略ID 策略名称 副本分布 注释 15 Lazy_Persist RAM_DISK:1,DISK:n - 1 Hadoop默认不允许在内存中存储数据 12 All_SSD SSD:n 10 One_SSD SSD:1,DISK:n - 1 7 Hot(默认使用) DISK:n 5 Warm DISK:1,ARCHIVE:n - 1 2 Cold ARCHIVE:n
5.3.7.2 配置存储类型
hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>配置副本数,默认为3。如果有配置纠删码,则副本数只会有1份</description>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
<description>允许用户更改目录的存储策略,默认true</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file://${hadoop.tmp.dir}/dfs/data1,[RAM_DISK]file://${hadoop.tmp.dir}/dfs/data2</value>
<description>
DataNode数据在本地的保存位置,可以配置多个,多个目录保存的数据不同。
默认是 file://${hadoop.tmp.dir}/dfs/data
其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置.
其中file表示本地文件系统,前面的中括号以及里面配置的SSD表示该目录的存储类型。
</description>
</property>
</configuration>
5.3.7.3 配置存储策略
# 将 /input 目录设置为Warm存储策略
hdfs storagepolicies -setStoragePolicy -path /input -policy Warm
# 让HDFS按照存储策略移动 /input
hdfs mover /input
# 查看 /input 下的文件存储类型
hdfs fsck /input -files -blocks -locations
5.3.8 HDFS-故障排查
5.3.8.1 NN数据损坏
如果集群是使用NameNode和Secondary NameNode,可以从Secondary NameNode复制数据到NameNode。如果在损坏时有数据操作,还是可能会损失最近操作的部分数据。
5.3.8.2 安全模式&磁盘修复
安全模式:集群只接受数据的读操作,不接受数据的写操作。
-
进入安全模式的条件:
- NameNode在加载镜像和编辑日志期间;
- NameNode在接受DataNode注册时;
-
退出安全模式的条件:
- 已启动的节点数大于dfs.namenode.safemode.min.datanodes的配置,该配置默认为0,即只要有一个节点启动。就可以退出安全模式。如果该值配置为大于总节点数,则永久处于安全模式下,集群只能读取数据。
- 已启动的块占系统总块数的百分比大于dfs.namenode.safemode.threshold-pct的配置。该值默认为 0.999f,即只允许有一个块没启动。如果该值配置为大于1的数,则永久处于安全模式下,集群只能读取数据;
- 超过dfs.namenode.safemode.extension配置的稳定时间。默认30000ms。
-
磁盘修复:
当丢失的块数大于1,则启动集群后,会进入安全模式,并且不会自动退出。这时可以使用命令退出安全模式。
但还是会提示有数据块丢失,这时可以选择修复磁盘,或者直接删除丢失块的文件。
5.3.9 慢磁盘监控
慢磁盘即读写性能慢的磁盘。使用久了磁盘会自然老化,性能也会下降。这种慢磁盘可以用来存放冷数据。
-
通过观察NameNode和DataNode上次心跳联系时间,是否大于心跳频率;
-
fio命令,测试磁盘的读写性能:
# 下载fio yum install fio -y # 顺序读测试 fio -filename=/tmp/fio/test.log -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync \ -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r # 顺序写测试 fio -filename=/tmp/fio/test.log -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync \ -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_w # 随机写测试 fio -filename=/tmp/fio/test.log -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync \ -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw # 混合随机读写 fio -filename=/tmp/fio/test.log -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync \ -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randrw
5.3.10 小文件归档
不足块大小的小文件,也是一个块,而每个块占用NameNode的内存大小都是150B。这样会浪费NameNode的内存空间。
-
HDFS存档文件:
HDFS存档文件或HAR文件,就是在相对于NameNode来说,把小文件打包为一个整体,以减少NameNode的内存消耗。
# 把 /input 目录下的文件打包为一个叫做 input.har 的文件,输出到 /output 目录下。底层为MapReduce hadoop archive -archiveName input.har -p /input /output # 查看har hadoop fs -ls har:///output/input.har hadoop fs -cat har:///output/input.har/word1.txt # 恢复到根目录 hadoop fs -cp har:///output/input.har/word1.txt /
5.3.11 集群迁移
-
Apache与Apache集群间数据迁移
# hadoop102和hadoop105为两个集群的NameNode地址 hadoop distcp hdfs://hadoop102:8020/input hdfs://hadoop105:8020/input -
Apache与CDH集群间数据迁移
5.4 MapReduce
5.4.1 单词统计案例
-
Mapper
package com.guoli.hadoopstudy.mapReduce.wordCount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.StringTokenizer; /** * 单词统计的Mapper类 * * @author guoli * @data 2022-01-16 14:08 */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * 单个单词 */ private final Text word = new Text(); /** * 1 */ private final IntWritable one = new IntWritable(1); /** * 映射,文档数据拆分为单个单词和1的键值对 * * @param key 字符偏移量 * @param value 一行数据 * @param context 上下文 * @throws IOException IO移除 * @throws InterruptedException 中断异常 */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 将一行(value)转换为字符串分词器,默认根据" \t\n\r\f"5个分词,也可自定义 StringTokenizer words = new StringTokenizer(value.toString()); while (words.hasMoreTokens()) { // 获取分词器中每个单词,转化为Text类型 word.set(words.nextToken()); // 将单词写入上下文,供Reducer使用,每个单词一次 context.write(word, one); } } } -
Reducer
package com.guoli.hadoopstudy.mapReduce.wordCount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 单词统计Reducer类 * * @author guoli * @data 2022-01-16 14:08 */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * 每个单词的最终个数 */ private final IntWritable result = new IntWritable(); /** * 汇总,将单个单词出现的次数累加 * * @param key 单个单词 * @param values 单个单词出现次数组成的集合,如[1, 1, 1] * @param context 上下文 * @throws IOException IO移除 * @throws InterruptedException 中断异常 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; // 遍历单词个数组成的列表,累加 for (IntWritable one : values) { sum += one.get(); } // 将单词个数转换为IntWritable类型 result.set(sum); // 将汇总结果,即每个单词和单词总个数写入上下文 context.write(key, result); } } -
Driver
package com.guoli.hadoopstudy.mapReduce.wordCount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 单词统计的运行类 * * @author guoli * @data 2022-01-16 14:08 */ public class WordCountDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 1 获取配置参数 Configuration conf = new Configuration(); // 2 获取job对象 String jobName = "word count"; Job job = Job.getInstance(conf, jobName); // 3 设置jar包路径 job.setJarByClass(WordCountDriver.class); // 4 关联Mapper和Reducer job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 5 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 6 设置最终输出的KV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 7 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } } -
打成jar包后,上传集群,执行:
# hadoop-study-0.0.1-SNAPSHOT.jar 为jar包所在路径 # com.guoli.hadoopstudy.mapReduce.wordCount.WordCountDriver 为Driver类所在路径 # /input 为输入文件路径 # /output 为结果输出路径,不能是已存在的路径 hadoop jar hadoop-study-0.0.1-SNAPSHOT.jar \ com.guoli.hadoopstudy.mapReduce.wordCount.WordCountDriver \ /input /output
5.4.2 序列化案例
统计每个号码的上行流量、下行流量、总流量。
-
序列化实例类
注意事项:
- 反序列化方法readFields中字段读取的顺序要和序列化方法write里面字段顺序保持一致;
- 必须要有无参构造函数;
- 重写toString方法,定义最终输出结果的内容和格式;
- 字符串序列化使用out.writeUTF,对应反序列化使用in.readUTF;
package com.guoli.hadoopstudy.mapReduce.writable; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 流量类 * hadoop序列化:实现Writable接口,重写write和readFields方法 * * @author guoli * @data 2022-01-16 19:32 */ public class FlowBean implements Writable { /** * 上行流量 */ private long upFlow; /** * 下行流量 */ private long downFlow; /** * 总流量 */ private long sumFlow; public FlowBean() { } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public void setSumFlow() { this.sumFlow = this.upFlow + this.downFlow; } /** * 重写toString方法 * * @return 一行数据,tab分隔 */ @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } /** * 序列化 * * @param out 输出数据 * @throws IOException IO异常 */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化 * 注意字段顺序,和write保持一致 * * @param in 输入数据 * @throws IOException IO异常 */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } } -
Mapper
package com.guoli.hadoopstudy.mapReduce.writable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 流量统计Mapper类 * * @author guoli * @data 2022-01-16 19:58 */ public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> { /** * 电话 */ private final Text phone = new Text(); /** * 流量数据 */ private final FlowBean flowBean = new FlowBean(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException { // 对每一行输入数据根据\t转换为数组 String[] split = value.toString().split("\t"); phone.set(split[1]); flowBean.setUpFlow(Long.parseLong(split[3])); flowBean.setDownFlow(Long.parseLong(split[4])); flowBean.setSumFlow(); context.write(phone, flowBean); } } -
Reducer
package com.guoli.hadoopstudy.mapReduce.writable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 流量统计Reducer类 * * @author guoli * @data 2022-01-16 14:08 */ public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> { /** * 流量汇总结果 */ private final FlowBean result = new FlowBean(); @Override protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException { long totalUp = 0; long totalDown = 0; // 取出上行流量和下行流量进行累加 for (FlowBean flowBean : values) { totalUp += flowBean.getUpFlow(); totalDown += flowBean.getDownFlow(); } result.setUpFlow(totalUp); result.setDownFlow(totalDown); result.setSumFlow(); context.write(key, result); } } -
Driver
package com.guoli.hadoopstudy.mapReduce.writable; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 流量统计Driver类 * * @author guoli * @data 2022-01-16 20:14 */ public class FlowDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 1 获取配置参数 Configuration conf = new Configuration(); // 2 获取job对象 String jobName = "Flow Statistics"; Job job = Job.getInstance(conf, jobName); // 3 设置jar包路径 job.setJarByClass(FlowDriver.class); // 4 关联Mapper和Reducer job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); // 5 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 6 设置最终输出的KV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 7 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } } -
打成jar包后,上传集群,执行
hadoop jar hadoop-study-0.0.1-SNAPSHOT.jar com.guoli.hadoopstudy.mapReduce.writable.FlowDriver /input/phone_data.txt /output
5.4.3 处理大量小文件
通过设置InputFromat使用CombineTextInputFormat,可以将大量小文件划分到一个切片中,减少切片数就减少了MapTask的数量,从而节约资源,适用于处理有大量小文件的场景。
在Driver类中添加job设置:
// 设置InputFormat为CombineTextInputFormat
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置最大切片大小为4M(4_194_304)
CombineTextInputFormat.setMaxInputSplitSize(job, 4_194_304);

5.4.4 自定义分区案例
在5.4.2序列化案例的基础上改造.
-
自定义Partitioner分区类:
package com.guoli.hadoopstudy.mapReduce.writable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * 流量分区类 * * @author guoli * @data 2022-01-18 9:09 */ public class FlowPartitioner extends Partitioner<Text, FlowBean> { @Override public int getPartition(Text key, FlowBean value, int numPartitions) { // 获取key的前三个字符 String proPhone = key.toString().substring(0, 3); int partition; // 根基key的前三个字符进行分区,分为4个区,分区从0开始,依次递增 switch (proPhone) { case "151": partition = 0; break; case "152": partition = 1; break; case "153": partition = 2; break; default: partition = 3; break; } return partition; } } -
修改job对象配置,使用自定义Partitioner分区类,根据分区个数设置ReduceTask个数
// 设置ReduceTask个数 job.setNumReduceTasks(4); // 使用自定义Partitioner分区类 job.setPartitionerClass(FlowPartitioner.class);
5.4.5 自定义排序案例
Map输出的key类型实现WritableComparable接口并重写compareTo方法
package com.guoli.hadoopstudy.mapReduce.writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 流量类
* hadoop序列化和排序:实现WritableComparable接口,重写write、readFields和compareTo方法
* WritableComparable<FlowBean>后面的泛型为要比较的类型
*
* @author guoli
* @data 2022-01-16 19:32
*/
public class FlowBean implements WritableComparable<FlowBean> {
/**
* 上行流量
*/
private long upFlow;
/**
* 下行流量
*/
private long downFlow;
/**
* 总流量
*/
private long sumFlow;
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow() {
this.sumFlow = this.upFlow + this.downFlow;
}
/**
* 重写toString方法
*
* @return 一行数据,tab分隔
*/
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
/**
* 序列化
*
* @param out 输出数据
* @throws IOException IO异常
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/**
* 反序列化
* 注意字段顺序,由write决定
*
* @param in 输入数据
* @throws IOException IO异常
*/
@Override
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
/**
* 先根据总流量倒序排序,总流量相同则根据上行流量正序排序
*
* @param o 比较对象
* @return 比较结果
*/
@Override
public int compareTo(FlowBean o) {
int result = Long.compare(o.getSumFlow(), this.sumFlow);
if (0 == result) {
result = Long.compare(this.upFlow, o.getUpFlow());
}
return result;
}
}
5.4.6 Combiner合并案例
Combiner合并,在Shuffle阶段对单个MapTask的结果进行合并,可以减少网络传输和降低Reduce的工作量。
一般可以直接使用自定义Reducer类。
// 配置使用Combiner合并
job.setCombinerClass(WordCountReducer.class);

5.4.7 自定义输出格式案例
根据每行的内容,是否包含字母a,将结果输出到两个指定的文件中
-
Mapper:
package com.guoli.hadoopstudy.mapReduce.logSeparation; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 日志分离Mapper类 * * @author guoli * @data 2022-01-18 22:03 */ public class LogSeparationMapper extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { // 直接将读取的一行数据作为输出的key,不做处理,value用NullWritable占位 context.write(value, NullWritable.get()); } } -
Reducer:
package com.guoli.hadoopstudy.mapReduce.logSeparation; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * 日志分离Reducer类 * * @author guoli * @data 2022-01-18 22:06 */ public class LogSeparationReducer extends Reducer<Text, NullWritable, Text, NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException { // Reducer阶段不做处理 for (NullWritable value : values) { context.write(key, value); } } } -
RecordWriter:
package com.guoli.hadoopstudy.mapReduce.logSeparation; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; import java.nio.charset.StandardCharsets; /** * 日志输出类 * * @author guoli * @data 2022-01-18 22:13· */ public class LogSeparationRecordWriter extends RecordWriter<Text, NullWritable> { /** * 第一条输出流 */ private final FSDataOutputStream one; /** * 第二条输出流 */ private final FSDataOutputStream two; public LogSeparationRecordWriter(TaskAttemptContext job) throws IOException { // 创建文件系统 FileSystem fs = FileSystem.get(job.getConfiguration()); // 创建输出流,指定输出结果路径 this.one = fs.create(new Path("/one.txt")); this.two = fs.create(new Path("/two.txt")); } /** * 通过不同的输出流写出去 * * @param key Reduce输出的key * @param value Reduce输出的value * @throws IOException IO异常 */ @Override public void write(Text key, NullWritable value) throws IOException { String str = key.toString(); if (str.contains("a")) { // 加 \n 换行 one.write((str + "\n").getBytes(StandardCharsets.UTF_8)); } else { two.write((str + "\n").getBytes(StandardCharsets.UTF_8)); } } /** * 关闭输出流 * * @param context 上下文 */ @Override public void close(TaskAttemptContext context) { IOUtils.closeStreams(one, two); } } -
FileOutputFormat:
package com.guoli.hadoopstudy.mapReduce.logSeparation; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 日志分离的输出格式类 * * @author guoli * @data 2022-01-18 22:10 */ public class LogSeparationOutputFormat extends FileOutputFormat<Text, NullWritable> { @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException { return new LogSeparationRecordWriter(job); } } -
Driver
package com.guoli.hadoopstudy.mapReduce.logSeparation; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 日志分离驱动类 * * @author guoli * @data 2022-01-18 22:45 */ public class LogSeparationDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 1 获取配置参数 Configuration conf = new Configuration(); // 2 获取job对象 String jobName = "log separation"; Job job = Job.getInstance(conf, jobName); // 3 设置jar包路径 job.setJarByClass(LogSeparationDriver.class); // 4 关联Mapper和Reducer job.setMapperClass(LogSeparationMapper.class); job.setReducerClass(LogSeparationReducer.class); // 5 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); // 配置自定义输出格式类 job.setOutputFormatClass(LogSeparationOutputFormat.class); // 设置InputFormat为CombineTextInputFormat job.setInputFormatClass(CombineTextInputFormat.class); // 设置最大切片大小为4M(4_194_304) CombineTextInputFormat.setMaxInputSplitSize(job, 4_194_304); // 6 设置最终输出的KV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 7 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); // 虽然在创建输出流的时候,已经指定了输出结果的路径,但是这个输出路径也不能省,会用来输出_SUCCESS文件 FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
5.4.8 多文件join案例
将on条件作为map的输出key,其他需要的列作为属性自定义一个value类,map阶段就是把多个文件转换为key和value,通过((FileSplit) context.getInputSplit()).getPath().getName();获取文件名。reduce阶段就是先把values迭代器里面的数据转存到自定义集合中,之后对数据进行拼接。
但这种处理方式很可能造成数据倾斜,因为在reduce需要处理大量数据。
-
TableJoinBean:
package com.guoli.hadoopstudy.mapReduce.tableJoin; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 订单表和产品表合并的bean类 * * @author guoli * @data 2022-01-19 15:49 */ public class TableJoinBean implements Writable { /** * 订单表文件名 */ public static final String ORDER_TABLE = "order.txt"; /** * 产品表文件名 */ public static final String PRODUCT_TABLE = "product.txt"; /** * 订单ID */ private String id; /** * 产品ID */ private String pid; /** * 产品数量 */ private int amount; /** * 产品名称 */ private String pName; /** * 表名 */ private String tableName; public TableJoinBean() { } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getPid() { return pid; } public void setPid(String pid) { this.pid = pid; } public int getAmount() { return amount; } public void setAmount(int amount) { this.amount = amount; } public String getpName() { return pName; } public void setpName(String pName) { this.pName = pName; } public String getTableName() { return tableName; } public void setTableName(String tableName) { this.tableName = tableName; } /** * 定义最终输出结果的内容和格式 * * @return id + "\t" + amount + "\t" + pName */ @Override public String toString() { return id + "\t" + amount + "\t" + pName; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(id); out.writeUTF(pid); out.writeInt(amount); out.writeUTF(pName); out.writeUTF(tableName); } @Override public void readFields(DataInput in) throws IOException { this.id = in.readUTF(); this.pid = in.readUTF(); this.amount = in.readInt(); this.pName = in.readUTF(); this.tableName = in.readUTF(); } } -
TableJoinMapper:
package com.guoli.hadoopstudy.mapReduce.tableJoin; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; /** * 表合并的Mapper类 * * @author guoli * @data 2022-01-19 16:27 */ public class TableJoinMapper extends Mapper<LongWritable, Text, Text, TableJoinBean> { /** * 产品ID作为输出的key */ private final Text pid = new Text(); /** * 输出的value */ private final TableJoinBean tableJoinBean = new TableJoinBean(); /** * 文件名 */ private String tableName; /** * setup方法每个MapTask都只会执行一次 * 当前情况下,如果使用获取文件名,就不能使用CombineTextInputFormat * * @param context 上下文 */ @Override protected void setup(Mapper<LongWritable, Text, Text, TableJoinBean>.Context context) { // 获取输入数据的文件名 tableName = ((FileSplit) context.getInputSplit()).getPath().getName(); } @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, TableJoinBean>.Context context) throws IOException, InterruptedException { if (TableJoinBean.ORDER_TABLE.equals(tableName)) { String[] vs = value.toString().split("\t"); pid.set(vs[1]); tableJoinBean.setId(vs[0]); tableJoinBean.setPid(vs[1]); tableJoinBean.setAmount(Integer.parseInt(vs[2])); tableJoinBean.setpName(""); tableJoinBean.setTableName(tableName); } else if (TableJoinBean.PRODUCT_TABLE.equals(tableName)) { String[] vs = value.toString().split("\t"); pid.set(vs[0]); tableJoinBean.setId(""); tableJoinBean.setPid(vs[0]); tableJoinBean.setAmount(0); tableJoinBean.setpName(vs[1]); tableJoinBean.setTableName(tableName); } context.write(pid, tableJoinBean); } } -
TableJoinReducer:
package com.guoli.hadoopstudy.mapReduce.tableJoin; import cn.hutool.core.bean.BeanUtil; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; import java.util.List; /** * 表合并的Reduce类 * * @author guoli * @data 2022-01-19 16:45 */ public class TableJoinReducer extends Reducer<Text, TableJoinBean, NullWritable, TableJoinBean> { /** * 输出空的key */ private final NullWritable nullWritable = NullWritable.get(); @Override protected void reduce(Text key, Iterable<TableJoinBean> values, Reducer<Text, TableJoinBean, NullWritable, TableJoinBean>.Context context) throws IOException, InterruptedException { String pName = ""; List<TableJoinBean> tableJoinBeans = new ArrayList<>(); // 由于MapReduce中的迭代器只能使用一次,并且保存的不是真正的对象 for (TableJoinBean value : values) { if (TableJoinBean.PRODUCT_TABLE.equals(value.getTableName())) { pName = value.getpName(); } else { TableJoinBean tableJoinBean = new TableJoinBean(); BeanUtil.copyProperties(value, tableJoinBean); tableJoinBeans.add(tableJoinBean); } } for (TableJoinBean tableJoinBean : tableJoinBeans) { tableJoinBean.setpName(pName); context.write(nullWritable, tableJoinBean); } } } -
TableJoinDriver:
package com.guoli.hadoopstudy.mapReduce.tableJoin; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /** * 表合并的Driver类 * * @author guoli * @data 2022-01-16 20:14 */ public class TableJoinDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 1 获取配置参数 Configuration conf = new Configuration(); // 2 获取job对象 String jobName = "table join"; Job job = Job.getInstance(conf, jobName); // 3 设置jar包路径 job.setJarByClass(TableJoinDriver.class); // 4 关联Mapper和Reducer job.setMapperClass(TableJoinMapper.class); job.setReducerClass(TableJoinReducer.class); // 5 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TableJoinBean.class); // 6 设置最终输出的KV类型 job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(TableJoinBean.class); // 7 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
5.4.9 缓存文件案例
在上面文件join案例中,如果有一个表数据量很小,就可以把小文件加入缓存文件中,在Map阶段就完成数据的拼接,可以解决数据倾斜的问题。
-
TableJoinMapper:
package com.guoli.hadoopstudy.mapReduce.cacheFile; import org.apache.commons.lang3.StringUtils; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.thirdparty.com.google.common.base.Charsets; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.HashMap; import java.util.Map; /** * 通过缓存文件实现join的Mapper类 * * @author guoli * @data 2022-01-19 21:12 */ public class TableJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> { /** * 存放缓存文件product.txt的数据 */ private final Map<String, String> productMap = new HashMap<>(); /** * 输出的key */ private final Text outK = new Text(); /** * 输出的value */ private final NullWritable outV = NullWritable.get(); @Override protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException { // 获取缓存文件的URI URI[] uris = context.getCacheFiles(); // 获取文件系统 FileSystem fs = FileSystem.get(context.getConfiguration()); // 打开输入流 FSDataInputStream open = fs.open(new Path(uris[0])); BufferedReader reader = new BufferedReader(new InputStreamReader(open, Charsets.UTF_8)); // 每次读取一行 String line; while (StringUtils.isNotEmpty(line = reader.readLine())) { String[] strings = line.split("\t"); productMap.put(strings[0], strings[1]); } // 关闭输入流 IOUtils.closeStreams(reader); } @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { String[] strings = value.toString().split("\t"); String result = strings[0] + "\t" + productMap.get(strings[1]) + "\t" + strings[2]; outK.set(result); context.write(outK, outV); } } -
TableJoinDriver:
package com.guoli.hadoopstudy.mapReduce.cacheFile; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; /** * 表合并的Driver类 * * @author guoli * @data 2022-01-16 20:14 */ public class TableJoinDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException { // 1 获取配置参数 Configuration conf = new Configuration(); // 2 获取job对象 String jobName = "table join"; Job job = Job.getInstance(conf, jobName); // 3 设置jar包路径 job.setJarByClass(TableJoinDriver.class); // 4 关联Mapper和Reducer job.setMapperClass(TableJoinMapper.class); // 设置ReduceTask个数为0 job.setNumReduceTasks(0); // 添加缓存文件 job.addCacheFile(new URI("hdfs:/cache/product.txt")); // 5 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); // 6 设置最终输出的KV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 7 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
5.4.10 压缩案例
-
map输出文件压缩:
在Driver中配置。
// 开启map输出文件的压缩 conf.setBoolean("mapreduce.map.output.compress", true); // 设置map输出文件的压缩方式为Bzip2 conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class); -
reduce输出文件压缩:
// 开启reduce输出文件的压缩 conf.setBoolean("mapreduce.output.fileoutputformat.compress", true); // 设置reduce输出文件的压缩方式为Bzip2 conf.setClass("mapreduce.output.fileoutputformat.compress.codec", BZip2Codec.class, CompressionCodec.class);
5.4.11 MapReduce跑得慢原因
- 计算机性能:CPU、内存、磁盘、网络;
- IO操作优化:
- 数据倾斜;
- Map运行时间太长,导致Reduce等待过久;
- 小文件过多。
5.4.12 MapReduce优化方向
- 自定义分区,给key加上前缀或后缀等,通过启动多个ReduceTask,解决数据倾斜问题;
- 减少环形缓冲区溢写的次数:加大环形缓冲区的大小;(增加内存消耗)
- 增加每次Marge合并的文件数:由 mapreduce.task.io.sort.factor 配置,默认10;(增加内存消耗)
- 采用Combiner;
- 采用压缩,减少网络IO;
- 调整MapTask运行内存,由 mapreduce.map.memory.mb 配置,默认1GB。处理数据量每128MB提高1G内存。同时要调整 mapreduce.map.java.opts 为不小于运行内存;
- 计算密集型任务,增加MapTask的CPU核数。由 mapreduce.map.cpu.vcores 配置,默认1个;
- MapTask异常重试:MapTask执行失败的重试次数。由 mapreduce.map.maxattempts 配置,默认4次。服务器性能差调高;
- 提高ReduceTask去Map拉取数据的并行数,由 mapreduce.reduce.shuffle.parallelcopies 配置,默认5;
- 提高Buffer占ReduceTask内存的比例,由 mapreduce.reduce.shuffle.input.buffer.percent 配置,默认0.7;
- 当ReduceTask中Buffer占总内存的百分比达到阈值,就会开启merge合并。由 mapreduce.reduce.shuffle.merge.percent配置,默认0.66。提高此值以减少合并次数;
- 提高ReduceTask运行内存上限。由 mapreduce.reduce.memory.mb 配置,默认1G。处理数据量每128MB提高1G内存。同时要调整 mapreduce.reduce.java.opts 为不小于运行内存,提高到4-6G,如果还不够就考虑分区;
- 提高ReduceTask的核数。由 mapreduce.reduce.cpu.vcores 配置,默认1个。可以考虑提高到2-4个;
- ReduceTask异常重试:ReduceTask执行失败的重试次数。由 mapreduce.reduce.maxattempts 配置,默认4次。服务器性能差调高;
- 当MapTask完成的比例达到该值才会为ReduceTask申请资源。由 mapreduce.job.reduce.slowstart.completedmaps 配置,默认0.05;
- MapReduce任务超时时间:即不读取、写入数据,也不修改任务状态。由 mapreduce.task.timeout 配置,默认10分钟。如果对单条数据的+处理时间过长,则需要增加该值;
- 如果可以不用Reduce,尽量不用。不用可以减少shuffle和reduce两个阶段。
5.4.13 数据倾斜解决思路
- key为空值的情况过多:大量key为空值的数据会聚集到一个Reduce里面。——过滤空值,或分区,再聚合
- 能在map阶段处理的,尽量在map阶段处理。——Combiner,MapJoin
- 增加Reduce个数。
5.4.14 MR计算性能压测
虚拟机单节点磁盘不超过150G,不要执行,容易卡住。
# 使用RandomWriter来产生随机数,每个节点运行10个MapTask,每个MapTask产生大约1G大小的二进制随机数。
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar \
randomwriter random-data
# 执行sort任务
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar \
sort random-data sorted-data
#
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.1-tests.jar \
testmapredsort -sortInput random-data -sortOutput sorted-data
5.4.15 uber模式
容器的资源申请、创建等需要耗费大量资源和时间,而小文件的处理又很容易,甚至比不上准备容器的时间,所以为了节省资源,提高效率,可以开启uber模式,多个任务共用容器。
<configuration>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
<description>开启uber模式,默认false</description>
</property>
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
<description>uber模式中MapTask的最大数量,默认9个,只能调小</description>
</property>
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
<description>uber模式中ReduceTask的最大数量,默认1个,只能调小</description>
</property>
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
<description>uber模式中最大的输入数据量,默认为块大小,只能改小</description>
</property>
</configuration>
5.5 YARN
5.5.1 YARN核心参数配置案例
-
需求:
从1G数据中,统计每个单词出现的次数。服务器3台,CentOS7.X,配置相同,每台配置2G内存,2核CPU,2线程。
-
配置:
<configuration> <!-- 配置ResourceManager处理调度程序接口的线程数,默认50个 --> <!-- 3节点 * 2线程 = 最多6线程,预留一些处理其他任务,这里设置4个 --> <property> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>4</value> </property> <!-- 配置资源调度器,由于并发不高,使用CapacityScheduler --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <!-- 是否让yarn对节点内存、CPU等进行自动检测,设置false,由我们自己手动配置 --> <property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> </property> <!-- 是否将虚拟核数当做CPU核数,设置false,因为三台服务器配置相同 --> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> </property> <!-- NodeManager最多使用系统多少内存,默认(8192MB = 8GB) --> <!-- 由于单台服务器内存为2G,所以这里设置为2GB = 2048MB --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <!-- NodeManager最多使用的CPU核数,默认8个 --> <!-- 由于单台服务器CPU为2个,所以这里设置为2 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> <!-- 容器的最小内存,默认1024MB --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <!-- 容器的最大内存,默认8192MB --> <!-- 单个节点最大内存才2G,所以不能超过2G,这里配置2G --> <!-- (但也不能小于2G,不然无法申请容器,因为运行单个容器至少1.5G以上) --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- 容器的最小CPU核数,默认1 --> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <!-- 容器的最大CPU核数,默认4,这里单台服务器最大2,这里设置为2 --> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>2</value> </property> <!-- 是否对容器强制执行虚拟内存限制。默认true --> <!-- 由于CentOS7.x与java8对内存使用存在问题,有内存浪费,所以这里关闭虚拟内存限制 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 设置容器的内存限制时,虚拟内存与物理内存之间的比率。默认2.1 --> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> </configuration> -
配置结果:

5.5.2 调度器多队列提交任务
调度器默认只有一个default队列。
-
需求:
新增一个hive队列;
default队列占总资源的40%,最大占60%;
hive队列占总资源的60%,最大占80%。
default队列中单个用户最多占用队列90%的资源;
hive队列中单个用户最多占用队列100%的资源;
配置任务优先级;
-
修改hadoop-3.3.1/etc/hadoop/capacity-scheduler.xml配置文件:在添加队列后,后面的default队列有的配置,都复制一份改为hive。
<!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <property> <name>yarn.scheduler.capacity.maximum-applications</name> <value>10000</value> <description> Maximum number of applications that can be pending and running. </description> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.1</value> <description> Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications. </description> </property> <property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> <description> The ResourceCalculator implementation to be used to compare Resources in the scheduler. The default i.e. DefaultResourceCalculator only uses Memory while DominantResourceCalculator uses dominant-resource to compare multi-dimensional resources such as Memory, CPU etc. </description> </property> <!-- 新增一个hive队列,以英文逗号分割 --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,hive</value> <description> The queues at the this level (root is the root queue). </description> </property> <!-- 配置default队列占总资源的40% --> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>40</value> <description>Default queue target capacity.</description> </property> <!-- 配置hive队列占总资源的60% --> <property> <name>yarn.scheduler.capacity.root.hive.capacity</name> <value>60</value> <description>Default queue target capacity.</description> </property> <!-- default队列中单个用户最多占用队列90%的资源 --> <property> <name>yarn.scheduler.capacity.root.default.user-limit-factor</name> <value>0.9</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <!-- hive队列中单个用户最多占用队列100%的资源 --> <property> <name>yarn.scheduler.capacity.root.hive.user-limit-factor</name> <value>1</value> <description> Default queue user limit a percentage from 0.0 to 1.0. </description> </property> <!-- 配置default队列最多占总资源的60% --> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>60</value> <description> The maximum capacity of the default queue. </description> </property> <!-- 配置hive队列最多占总资源的80% --> <property> <name>yarn.scheduler.capacity.root.hive.maximum-capacity</name> <value>80</value> <description> The maximum capacity of the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.state</name> <value>RUNNING</value> <description> The state of the default queue. State can be one of RUNNING or STOPPED. </description> </property> <!-- 运行hive队列 --> <property> <name>yarn.scheduler.capacity.root.hive.state</name> <value>RUNNING</value> <description> The state of the default queue. State can be one of RUNNING or STOPPED. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>*</value> <description> The ACL of who can submit jobs to the default queue. </description> </property> <!-- hive队列允许任何用户提交任务 --> <property> <name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name> <value>*</value> <description> The ACL of who can submit jobs to the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_administer_queue</name> <value>*</value> <description> The ACL of who can administer jobs on the default queue. </description> </property> <!-- hive队列允许任何用户管理队列 --> <property> <name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name> <value>*</value> <description> The ACL of who can administer jobs on the default queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name> <value>*</value> <description> The ACL of who can submit applications with configured priority. For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}] </description> </property> <!-- 配置哪些用户可以配置hive队列的优先级 --> <property> <name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name> <value>*</value> <description> The ACL of who can submit applications with configured priority. For e.g, [user={name} group={name} max_priority={priority} default_priority={priority}] </description> </property> <property> <name>yarn.scheduler.capacity.root.default.maximum-application-lifetime </name> <value>-1</value> <description> Maximum lifetime of an application which is submitted to a queue in seconds. Any value less than or equal to zero will be considered as disabled. This will be a hard time limit for all applications in this queue. If positive value is configured then any application submitted to this queue will be killed after exceeds the configured lifetime. User can also specify lifetime per application basis in application submission context. But user lifetime will be overridden if it exceeds queue maximum lifetime. It is point-in-time configuration. Note : Configuring too low value will result in killing application sooner. This feature is applicable only for leaf queue. </description> </property> <!-- 配置哪些用户可以配置hive队列的优先级 --> <property> <name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime </name> <value>-1</value> <description> Maximum lifetime of an application which is submitted to a queue in seconds. Any value less than or equal to zero will be considered as disabled. This will be a hard time limit for all applications in this queue. If positive value is configured then any application submitted to this queue will be killed after exceeds the configured lifetime. User can also specify lifetime per application basis in application submission context. But user lifetime will be overridden if it exceeds queue maximum lifetime. It is point-in-time configuration. Note : Configuring too low value will result in killing application sooner. This feature is applicable only for leaf queue. </description> </property> <property> <name>yarn.scheduler.capacity.root.default.default-application-lifetime </name> <value>-1</value> <description> Default lifetime of an application which is submitted to a queue in seconds. Any value less than or equal to zero will be considered as disabled. If the user has not submitted application with lifetime value then this value will be taken. It is point-in-time configuration. Note : Default lifetime can't exceed maximum lifetime. This feature is applicable only for leaf queue. </description> </property> <!-- 配置hive队列中的任务的最大生存时间,超过则会被杀死 --> <property> <name>yarn.scheduler.capacity.root.hive.default-application-lifetime </name> <value>-1</value> <description> Default lifetime of an application which is submitted to a queue in seconds. Any value less than or equal to zero will be considered as disabled. If the user has not submitted application with lifetime value then this value will be taken. It is point-in-time configuration. Note : Default lifetime can't exceed maximum lifetime. This feature is applicable only for leaf queue. </description> </property> <property> <name>yarn.scheduler.capacity.node-locality-delay</name> <value>40</value> <description> Number of missed scheduling opportunities after which the CapacityScheduler attempts to schedule rack-local containers. When setting this parameter, the size of the cluster should be taken into account. We use 40 as the default value, which is approximately the number of nodes in one rack. Note, if this value is -1, the locality constraint in the container request will be ignored, which disables the delay scheduling. </description> </property> <property> <name>yarn.scheduler.capacity.rack-locality-additional-delay</name> <value>-1</value> <description> Number of additional missed scheduling opportunities over the node-locality-delay ones, after which the CapacityScheduler attempts to schedule off-switch containers, instead of rack-local ones. Example: with node-locality-delay=40 and rack-locality-delay=20, the scheduler will attempt rack-local assignments after 40 missed opportunities, and off-switch assignments after 40+20=60 missed opportunities. When setting this parameter, the size of the cluster should be taken into account. We use -1 as the default value, which disables this feature. In this case, the number of missed opportunities for assigning off-switch containers is calculated based on the number of containers and unique locations specified in the resource request, as well as the size of the cluster. </description> </property> <property> <name>yarn.scheduler.capacity.queue-mappings</name> <value></value> <description> A list of mappings that will be used to assign jobs to queues The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]* Typically this list will be used to map users to queues, for example, u:%user:%user maps all users to queues with the same name as the user. </description> </property> <property> <name>yarn.scheduler.capacity.queue-mappings-override.enable</name> <value>false</value> <description> If a queue mapping is present, will it override the value specified by the user? This can be used by administrators to place jobs in queues that are different than the one specified by the user. The default is false. </description> </property> <property> <name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name> <value>1</value> <description> Controls the number of OFF_SWITCH assignments allowed during a node's heartbeat. Increasing this value can improve scheduling rate for OFF_SWITCH containers. Lower values reduce "clumping" of applications on particular nodes. The default is 1. Legal values are 1-MAX_INT. This config is refreshable. </description> </property> <property> <name>yarn.scheduler.capacity.application.fail-fast</name> <value>false</value> <description> Whether RM should fail during recovery if previous applications' queue is no longer valid. </description> </property> <property> <name>yarn.scheduler.capacity.workflow-priority-mappings</name> <value></value> <description> A list of mappings that will be used to override application priority. The syntax for this list is [workflowId]:[full_queue_name]:[priority][,next mapping]* where an application submitted (or mapped to) queue "full_queue_name" and workflowId "workflowId" (as specified in application submission context) will be given priority "priority". </description> </property> <property> <name>yarn.scheduler.capacity.workflow-priority-mappings-override.enable</name> <value>false</value> <description> If a priority mapping is present, will it override the value specified by the user? This can be used by administrators to give applications a priority that is different than the one specified by the user. The default is false. </description> </property> </configuration> -
刷新队列:
yarn rmadmin -refreshQueues -
验证结果:

-
指定任务运行的队列:任务默认都是提交到default队列
-
方式一:通过java代码中Driver驱动类的conf配置
Configuration conf = new Configuration(); // 配置当前任务的提交队列,提交到hive队列 conf.set("mapreduce.job.queuename", "hive") -
方式二:通过运行jar包的时候指定参数
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar \ wordcount -D mapreduce.job.queuename=hive /input /output
-
-
验证结果:


-
配置任务优先级:
-
开启优先级功能:配置hadoop-3.3.1/etc/hadoop/yarn-site.xml
<configuration> <!-- 配置集群中任务的最高优先级为5即0-5共6个等级,默认为0即关闭优先级功能 --> <property> <name>yarn.cluster.max-application-priority</name> <value>5</value> </property> </configuration> -
配置优先级:
-
通过java代码中Driver驱动类的conf配置(适合自定义的MapReduce任务):
Configuration conf = new Configuration(); // 配置当前任务的提交队列,提交到hive队列 conf.set("mapreduce.job.priority", "5") -
通过运行jar包的时候指定参数:
# 开启5个map求pi,优先级设置为5级最高级 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi \ -D mapreduce.job.priority=5 5 2000000 -
通过命令根据任务ID修改任务优先级(适合已提交的任务):
yarn application -appID application_1642830982994_0003 -updatePriority 5
-
-
-
验证结果:

5.5.3 公平调度器案例
-
需求
使用公平调度器;
创建两个队列:dev和test;
dev用户的任务默认提交到dev队列;
test用户的任务默认提交到test队列;
-
配置使用公平调度器:修改hadoop-3.3.1/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>配置调度器为公平调度器</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/usr/local/big-data/hadoop-3.3.1/etc/hadoop/fair-scheduler.xml</value> <description>指定公平调度器的配置文件</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>false</value> <description>禁止队列间资源抢占</description> </property> </configuration> -
配置公平调度器的队列:
<?xml version="1.0"?> <allocations> <!-- 单个队列中Application Master最大占用资源比例 --> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <!-- 单个队列最大资源的默认值:4GB,4核 --> <queueMaxResourcesDefault>4.96 mb,4vcores</queueMaxResourcesDefault> <queue name="dev"> <!-- 当前队列最小资源:2GB,2核 --> <minResources>2048 mb,2vcores</minResources> <!-- 当前队列最大资源:4GB,4核 --> <maxResources>4096 mb,4vcores</maxResources> <!-- 当前队列最多同时运行的应用数,和线程数相同 --> <maxRunningApps>4</maxRunningApps> <!-- 当前队列中Application Master最大占用资源比例 --> <maxAMShare>0.5</maxAMShare> <!-- 当前队列资源权重 --> <weight>2.0</weight> <!-- 当前队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <queue name="test"> <!-- 当前队列最小资源:2GB,2核 --> <minResources>2048 mb,2vcores</minResources> <!-- 当前队列最大资源:4GB,4核 --> <maxResources>4096 mb,4vcores</maxResources> <!-- 当前队列最多同时运行的应用数,和线程数相同 --> <maxRunningApps>4</maxRunningApps> <!-- 当前队列中Application Master最大占用资源比例 --> <maxAMShare>0.5</maxAMShare> <!-- 当前队列资源权重 --> <weight>2.0</weight> <!-- 当前队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 任务队列分配策略 --> <queuePlacementPolicy> <!-- 提交任务到指定队列,队列不存在不允许创建。如果没有指定队列,则继续匹配下一个规则 --> <rule name="specified" create="false" /> <!-- 提交任务到用户名对应的队列 --> <rule name="nestedUserQueue" create="false" > <!-- 提交任务到用户所在组名对应的队列 --> <rule name="primaryGroup" create="false" /> </rule> <!-- 最后一个规则匹配,指定默认队列,提交到默认队列;如果配置为reject,即拒绝任务提交 --> <rule name="default" queue="default"/> </queuePlacementPolicy> </allocations>
5.5.4 Yarn的Tool接口案例
实现Tool接口,将job配置写在run()方法中,可以自动过滤掉-D的运行参数。
-
实现Tool接口:
package com.guoli.hadoopstudy.yarn; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import java.io.IOException; import java.util.StringTokenizer; /** * 单词统计 * * @author guoli * @data 2022-01-22 15:35 */ public class WordCount implements Tool { /** * 配置信息 */ private Configuration conf; @Override public int run(String[] args) throws Exception { // 1 获取job对象 Job job = Job.getInstance(conf, "word count"); // 2 设置jar包路径 job.setJarByClass(Driver.class); // 3 关联Mapper和Reducer job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 4 设置map输出的KV类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置最终输出的KV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入文件路径和输出文件路径 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 提交job return job.waitForCompletion(true) ? 0: 1; } @Override public void setConf(Configuration conf) { this.conf = conf; } @Override public Configuration getConf() { return conf; } public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * 单个单词 */ private final Text word = new Text(); /** * 1 */ private final IntWritable one = new IntWritable(1); /** * 映射,文档数据拆分为单个单词和1的键值对 * * @param key 字符偏移量 * @param value 一行数据 * @param context 上下文 * @throws IOException IO移除 * @throws InterruptedException 中断异常 */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 将一行(value)转换为字符串分词器,默认根据" \t\n\r\f"5个分词,也可自定义 StringTokenizer words = new StringTokenizer(value.toString()); while (words.hasMoreTokens()) { // 获取分词器中每个单词,转化为Text类型 word.set(words.nextToken()); // 将单词写入上下文,供Reducer使用,每个单词一次 context.write(word, one); } } } public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { /** * 每个单词的最终个数 */ private final IntWritable result = new IntWritable(); /** * 汇总,将单个单词出现的次数累加 * * @param key 单个单词 * @param values 单个单词出现次数组成的集合,如[1, 1, 1] * @param context 上下文 * @throws IOException IO移除 * @throws InterruptedException 中断异常 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; // 遍历单词个数组成的列表,累加 for (IntWritable one : values) { sum += one.get(); } // 将单词个数转换为IntWritable类型 result.set(sum); // 将汇总结果,即每个单词和单词总个数写入上下文 context.write(key, result); } } } -
运行Tool任务:
package com.guoli.hadoopstudy.yarn; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.util.Arrays; /** * 总驱动类 * * @author guoli * @data 2022-01-22 15:56 */ public class Driver { /** * 单词统计 */ public static final String WORD_COUNT = "wordcount"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Tool tool; int successful; if (WORD_COUNT.equals(args[0])) { tool = new WordCount(); successful = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length)); } else { throw new RuntimeException("not " + args[0]); } System.exit(successful); } } -
实验:
yarn jar hadoop-study-0.0.1-SNAPSHOT.jar com.guoli.hadoopstudy.yarn.Driver wordcount \ -D mapreduce.job.queuename=hive /input /output3
六 MapReduce框架原理
6.1 工作流程
-
MapTask

-
ReduceTask

6.2 InputFormat
InputFormat控制着MapReduce的输入数据格式,以及切片规则。
-
切片:
- 数据块:Block是HDFS物理上把数据分成一块一块的的,数据块是HDFS存储数据的单位;
- 数据切片:数据切片是MapReduce在逻辑上对输入数据进行分片,并不会作用于物理上,一个切片会对应启动一个MapTask。
-
FileInputFormat切片源码:
- 进入org.apache.hadoop.mapreduce.lib.input.FileInputFormat#getSplits;
- 找到数据存储目录;
- 遍历目录下的每一个文件;
- 获取文件大小;
- 计算切片大小(long splitSize = computeSplitSize(blockSize, minSize, maxSize););
- 判断文件大小是否大于切片大小的1.1倍;
- 如果是,则进行切片;
- 循环判断文件剩余大小是否大于切片大小的1.1倍;
- 将切片信息写入一个切片规划文件中;
- 提交切片规划文件到YARN,YARN上的MrAPPMaster就可以根据切片规划文件计算开启MapTask个数。
-
FileInputFormat实现类:
- TextInputFormat:FileInputFormat的默认实现类,一次读取一行,key为字节偏移量,value为一行数据;
- KeyValueTextInputFormat:一次读取一行,将这一行根据分隔符切分为Key和value;
- NLineInputFormat:一次读取多行;
- CombineTextInputFormat:和TextInputFormat类似,一次读取一行,key为字节偏移量,value为一行数据。但它可以将多个小文件划分到一个切片中,由一个MapTask处理多个小文件,用于处理小文件过多的场景。
-
CombineTextInputFormat切片机制:
分为两个阶段:虚拟存储过程和切片过程。
-
虚拟存储过程:
将所有文件按字典进行排序,之后每次取出一个,将其大小和设置的setMaxInputSplitSize值进行比较。如果文件大小大于2倍的setMaxInputSplitSize值,则以setMaxInputSplitSize值大小切分一块,之后剩余的再和2倍的setMaxInputSplitSize值比较,如果小于或等于2倍的setMaxInputSplitSize值,则将剩余的平分为两块。
-
切片过程:
如果虚拟存储过程中的文件大于等于setMaxInputSplitSize值,则单独作为一个切片。如果小于setMaxInputSplitSize值,则和相邻的相加,直到大于等于setMaxInputSplitSize值为止,再作为一个切片。
-
6.3 MapTask并行度决定机制
- 默认情况下,切片大小等于块大小;
- 切片数由InputFromat类型和切片大小决定;
- MapTask数等于切片数;
- 切片时不考虑数据集整体,而是根据InputFromat不同而使用不同的方式。比如TextInputFromat每次只针对单个文件进行切片;
- 如果文件大小不大于块大小的1.1倍,则只切片一个。
6.4 Shuffle机制
Shuffle是Map阶段之后、Reduce阶段之前的过程,可以对Map输出结果进行排序、压缩等操作,之后输入Reduce。如果没有Reduce阶段,那么Shuffle阶段也不会存在,而是直接由Map阶段输出结果。

6.4.1 Partition分区
Partition分区会对Map的输出结果根据key或value进行分区(分组),每个分区,都会对应开启一个ReduceTask,最终结果写入对应分区的文件中。
-
默认情况下,分区个数由ReduceTask个数决定,默认使用HashPartitioner.class类根据key的hashCode分区:
// 源码 public class HashPartitioner<K, V> extends Partitioner<K, V> { /** * 获取分区 * * @param key Map输出的key * @param value Map输出的value * @param numReduceTasks ReduceTask的个数 * @return 分区 */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } -
如果设置ReduceTask个数为1个(默认为1),即只有一个分区0:
// 源码 private class NewOutputCollector<K, V> extends org.apache.hadoop.mapreduce.RecordWriter<K, V> { private final MapOutputCollector<K, V> collector; private final org.apache.hadoop.mapreduce.Partitioner<K, V> partitioner; private final int partitions; @SuppressWarnings("unchecked") NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException, ClassNotFoundException { collector = createSortingCollector(job, reporter); // 获取ReduceTask个数,默认为1,作为partitions partitions = jobContext.getNumReduceTasks(); if (partitions > 1) { partitioner = (org.apache.hadoop.mapreduce.Partitioner<K, V>) ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job); } else { partitioner = new org.apache.hadoop.mapreduce.Partitioner<K, V>() { @Override public int getPartition(K key, V value, int numPartitions) { // partitions由1设为0 return partitions - 1; } }; } } } -
自定义Partitioner,将结果按要求输出到不同的文件:
- 自定义类,继承抽象类org.apache.hadoop.mapreduce.Partitioner;
- 重写抽象类org.apache.hadoop.mapreduce.Partitioner的getPartition方法;
- Driver类中通过job对象设置使用自定义Partitioner类;
- 设置ReduceTask个数(如果不设置,默认为1,不会走自定义Partitioner)。
6.4.2 排序
MapTask和ReduceTask都对对数据根据key进行排序,按字典顺序进行排序,该操作属于Hadoop的默认行为,任何应用程序中的数据均会被排序,而不管是否需要,所以key的类型必须支持排序,如果key为自定义类型,需要实现Comparable接口,重写compareTo方法。同时自定义类需要支持序列化,而WritableComparable接口继承了Writable,和Comparable,所以最终自定义类需要实现WritableComparable接口,重写write、readFields、compareTo方法。
-
默认排序
-
MapTask
在MapTask,它会将处理结果暂时放入环形缓冲区,当环形缓冲区使用率达到一定阈值(80%)后,再对缓冲区中的数据进行一次快速排序,之后溢写到磁盘文件中。当所有数据处理完成后,它会对磁盘上的所有文件进行一次归并排序,所有分区的数据都会保存在一个文件里面。最终只有一个数据文件和一个index文件,index文件保存着每个分区的数据在数据文件中的位置,以便Reduce来拉取对应分区的数据。
-
ReduceTask
在ReduceTask,它从每个MapTask上远程拉取相应的数据文件到内存中,如果内存中文件大小或数目超过一定阈值,则进行一次合并后溢写到磁盘上。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大的文件。当所有数据拷贝完成后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序,形成一个文件。
-
-
排序分类
- 部分排序:MapReduce根据输入记录的键对数据集排序,保证输出的每个文件内部有序;
- 全排序:最终输出结果只有一个文件,且文件内部有序;
- 辅助排序(GroupingComparator分组):在Reduce对key进行分组。在key为bean对象时,想让一个或几个字段值相同(而全部字段比较不同)的key进入同一个reduce方法时使用;
- 多次排序:在自定义排序过程中,如果compareTo中根据多个字段排序。
-
自定义排序
- key的类型实现WritableComparable接口;
- 重写compareTo方法。
6.4.3 Combiner合并
- 描述:Combiner是MapReduce程序中Map和Reduce之外的一种可选的组件;
- 运行位置:运行在MapTask中,Shuffle阶段;
- 作用:对单个MapTask中的数据进行汇总,减少网络传输量;
- 限制:Combiner的输出KV类型与Reduce的输入KV类型一致,不能影响Reduce的业务逻辑;
- 实现:继承Reducer类,重写reduce方法,job对象绑定自定义的Combiner类。***(由于和自定义的Reduce一样,所以不用再自定义一个Combiner类,直接使用job绑定自定义的Reducer类就可以)***
6.5 ReduceTask并行度决定机制
-
ReduceTask个数默认为1,输出结果文件也就是一个;
-
ReduceTask个数设置:
// 在Driver中通过job对象设置 job.setNumReduceTasks(2); -
如果有自定义分区,ReduceTask个数设置应该和分区个数相同;
-
如果ReduceTask设置为0,则没有Reduce阶段,同时也不会有shuffle阶段,而是直接由Map输出结果,输出文件个数等于MapTask个数;
-
如果ReduceTask个数设置为1,则不会执行自定义分区;
-
如果没有自定义分区,ReduceTask个数需要根据集群性能决定;
-
如果数据分布不均匀,则可能在Reduce阶段产生数据倾斜。
6.6 OutputFormat
OutputFormat控制MapReduce的最终输出格式。
- TextOutputFormat:默认输出格式,逐行将结果输出到文件中。
- 自定义OutputFormat:
- 自定义类继承RecordWriter类,重写构造方法、write()、 close()方法;
- 自定义类继承FileOutputFormat抽象类,重写getRecordWriter()方法,返回自定义的RecordWriter对象;
- job绑定OutputFormat。
七 高可用集群搭建
普通集群只有一个NameNode和一个ResourceManager,如果发生故障,则集群不可用。所以高可用集群就是有多个NameNode和多个ResourceManager,一台active,其他standby。
由于Secondary NameNode并不能完全替代NameNode,所以在高可用集群中去掉了Secondary NameNode,原先Secondary NameNode的工作由处于standby的NameNode处理。
新增服务JournalNode,作用为同步Edits文件。
新增服务Zookeeper,作用为自动故障转移
7.1 搭建Zookeeper集群
7.1.1下载安装
-
安装jdk;
-
从官网下载Zookeeper,下载带有bin的压缩包,上传服务器;
-
解压,改名
tar -zxvf /root/apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/zookeeper/ mv apache-zookeeper-3.7.0-bin/ zookeeper-3.7.0 -
配置环境变量
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.7.0 export PATH=$PATH:$ZOOKEEPER_HOME/bin
7.1.2 集群搭建
-
单节点修改配置
cd /usr/local/zookeeper/zookeeper-3.7.0 mkdir data # 配置服务器编号 cd data/ # 创建myid文件,写入该节点编号(数字1、2、3等,每个节点唯一) vim myid cd /usr/local/zookeeper/zookeeper-3.7.0/conf/ cp zoo_sample.cfg zoo.cfg vim zoo.cfg # 修改dataDir dataDir=/usr/local/zookeeper/zookeeper-3.7.0/data # 在zoo.cfg末尾添加集群配置。 # server后面的数字是在data/myid中配置的集群中节点的编号 # IP为各个节点对应的IP地址 # 2888是Leader和Follower的通信端口 # 3888是Leader挂掉后选举用的端口 server.2=192.168.10.102:2888:3888 server.3=192.168.10.103:2888:3888 server.4=192.168.10.104:2888:3888 -
将环境变量配置文件和Zookeeper分发(拷贝)到其他节点,
-
集群配置
在集群各节点,修改/usr/local/zookeeper/zookeeper-3.7.0//data/myid 中的节点编号。
刷新环境变量。
7.1.3 集群脚本
#!/bin/bash
if [ $# -ne 1 ]
then
echo "请输入一个参数:start(开启集群)、stop(关闭集群)、status(查看状态)"
exit;
fi
for host in 192.168.10.102 192.168.10.103 192.168.10.104
do
echo "===== $1:$host ====="
ssh $host "zkServer.sh $1"
done
7.2 机器配置
所有节点都要配置
-
配置集群间ssh免密登录
# 生成秘钥,三次回车 ssh-keygen -t rsa # 分发公钥到集群其他所有(包括自己)机器 ssh-copy-id 192.168.10.102 ssh-copy-id 192.168.10.103 ssh-copy-id 192.168.10.104 -
配置启动用户:添加环境 变量
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
配置主机名与IP的映射关系:vim /etc/hosts
192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 -
关闭防火墙:hadoop集群有许多内部通信端口和外部查询端口
systemctl stop firewalld systemctl disable firewalld -
软件安装
# 分发 yum install rxync -y # 安装包含fuster程序的软件包Psmisc yum install psmisc -y
7.3 Hadoop配置
7.3.1 核心配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/core-site.xml
-
必要配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> <description>通过集群名称mycluster绑定NameNode地址</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/big_data/hadoop-3.3.1/data</value> <description>指定Hadoop数据的存储目录</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>192.168.10.102:2181,192.168.10.103:2181,192.168.10.104:2181</value> <description>指定ZKFC要连接的Zookeeper服务器地址</description> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> <description> 配置HDFS网页使用的静态用户为root,配置为集群启动时使用的Linux用户。 如果不配置,则在web页面无法操作数据 </description> </property> <!-- 回收站 --> <property> <name>fs.trash.interval</name> <value>60</value> <description> 设置文件在回收站的保存时间,默认为0,表示禁用,这里设置为1小时 </description> </property> <property> <name>fs.trash.checkpoint.interval</name> <value>60</value> <description> 设置多久检查一次回收站,是否有文件要删除。默认为0,表示和上面fs.trash.interval保持一致, 该值不能大于上面fs.trash.interval的值。这里设置为1个小时 </description> </property> </configuration> -
可选配置
<configuration> <property> <name>io.compression.codecs</name> <value></value> <description>在hadoop默认支持的基础上,增加新的压缩/解压缩方式</description> </property> </configuration>
7.3.2 HDFS配置
配置文件路径:hadoop-3.3.1/etc/hadoop/hdfs-site.xml
-
必要配置
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> <description> NameNode数据在本地的保存位置,可以配置多个,提高可靠性。 默认是临时目录 </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> <description> DataNode数据在本地的保存位置,可以配置多个,多个目录保存的数据不同。 默认是临时目录 </description> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/dfs/journalnode</value> <description> journalNode数据存储目录,默认为临时目录. 在3.3.1版本,该路径前面不能加file协议 </description> </property> <property> <name>dfs.nameservices</name> <value>mycluster</value> <description>完全分布式集群名称,默认为空</description> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> <description>配置集群mycluster中的NameNode节点</description> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>192.168.10.102:8020</value> <description>配置mycluster集群中nn1的内部通信地址</description> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>192.168.10.103:8020</value> <description>配置mycluster集群中nn2的内部通信地址</description> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>192.168.10.104:8020</value> <description>配置mycluster集群中nn3的内部通信地址</description> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>192.168.10.102:9870</value> <description>配置mycluster集群中nn1的web访问地址</description> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>192.168.10.103:9870</value> <description>配置mycluster集群中nn2的web访问地址</description> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>192.168.10.104:9870</value> <description>配置mycluster集群中nn3的web访问地址</description> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://192.168.10.102:8485;192.168.10.103:8485;192.168.10.104:8485/mycluster</value> <description>指定NameNode元数据在JournalNode上的存放位置</description> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> <description>访问代理类:client用于确定哪个NameNode为active</description> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> <description>配置隔离机制,即同一时刻只能有一台NameNode服务器对外响应</description> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> <description>配置秘钥位置,使用隔离机制时需要ssh秘钥登录</description> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> <description>是否启用NameNode故障自动转移。默认false</description> </property> <property> <name>dfs.hosts</name> <value>/usr/local/big_data/hadoop-3.3.1/etc/hadoop/whitelist</value> <description> 配置允许连接到NameNode的主机列表的文件(白名单),默认为空,即允许所有主机连接到 NameNode。配置的路径必须是全路径。文件名可自定义 </description> </property> <property> <name>dfs.hosts.exclude</name> <value>/usr/local/big_data/hadoop-3.3.1/etc/hadoop/blacklist</value> <description> 配置不允许连接到NameNode的主机列表的文件(黑名单),默认为空,即不限制任何主机连接 到NameNode。配置的路径必须是全路径。文件名可自定义 </description> </property> <!-- 根据集群性能配置 --> <property> <name>dfs.namenode.handler.count</name> <value>21</value> <description> NameNode处理DataNode和客户端请求的线程数,默认10个,三个节点配21个线程 </description> </property> <property> <name>dfs.namenode.handler.count</name> <value>10</value> <description>NameNode处理DataNode和客户端请求的线程数,默认10个</description> </property> </configuration> -
可选配置
<configuration> <!-- 集群监控配置 --> <property> <name>dfs.blockreport.intervalMsec</name> <value>21600000</value> <description> DataNode向NameNode周期性上报的间隔时间,默认6小时(21600000ms) </description> </property> <property> <name>dfs.blockreport.intervalMsec</name> <value>21600s</value> <description> DataNode扫描自己节点块信息的间隔时间,默认6小时(21600s) </description> </property> <!-- 下面两个定义超时(认为节点不可用)时间:2 * 300000ms + 10 * 3s = 10分钟 + 30s。下这里两个为默认值 --> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> <description>NameNode检查DataNode是否有问题的间隔时间</description> </property> <property> <name>dfs.heartbeat.interval</name> <value>3s</value> <description> datanode心跳间隔。可以使用以下后缀(不区分大小写):ms(毫秒)、s(秒)、 m(分钟)、h(小时)、d(天)来指定时间(如2s、2m、1h等)。或者以秒为单位提供 完整的数字(例如30代表30秒)。如果未指定时间单位,则假定为秒。 </description> </property> <!-- 压缩相关配置 --> <property> <name>mapreduce.map.output.compress</name> <value>true</value> <description>开启Map输出结果的压缩,默认false关闭</description> </property> <property> <name>mapreduce.map.output.compress.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>配置Map输出结果的压缩器,默认DefaultCodec</description> </property> <property> <name>mapreduce.output.fileoutputformat.compress</name> <value>true</value> <description>开启reduce输出结果的压缩,默认false关闭</description> </property> <property> <name>mapreduce.output.fileoutputformat.compress.codec</name> <value>org.apache.hadoop.io.compress.DefaultCodec</value> <description>配置reduce输出结果的压缩器,默认DefaultCodec</description> </property> <!-- NameNode和DataNode多目录配置 --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value> <description> NameNode数据在本地的保存位置,可以配置多个,提高可靠性。 默认是 file://${hadoop.tmp.dir}/dfs/name 其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置 </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>[SSD]file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value> <description> DataNode数据在本地的保存位置,可以配置多个,多个目录保存的数据不同。 默认是 file://${hadoop.tmp.dir}/dfs/data 其中hadoop.tmp.dir为集群中数据保存路径,我们都会自己在核心配置文件配置. 其中file表示本地文件系统,前面的中括号以及里面配置的SSD表示该目录的存储策略 </description> </property> <!-- 性能调优配置 --> <property> <name>dfs.replication</name> <value>3</value> <description>配置副本数,默认为3。如果有配置纠删码,则副本数只会有1份</description> </property> <property> <name>dfs.storage.policy.enabled</name> <value>true</value> <description>允许用户更改目录的存储策略,默认true</description> </property> </configuration>
7.3.3 YARN配置
配置文件路径:hadoop-3.3.1/etc/hadoop/yarn-site.xml
-
必要配置
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> <description>指定MapReduce使用shuffle</description> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> <description>启用ResourceManager高可用,默认false</description> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn</value> <description>指定TARN集群名称</description> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2,rm3</value> <description>指定各节点ResourceManager的名称</description> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>192.168.10.102</value> <description>配置rm1服务所在的服务器地址或主机名</description> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>192.168.10.102:8088</value> <description>配置rm1的web端口</description> </property> <property> <name>yarn.resourcemanager.address.rm1</name> <value>192.168.10.102:8032</value> <description>配置rm1的内部通信端口</description> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>192.168.10.102:8030</value> <description>配置AM向rm1申请资源的端口</description> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>192.168.10.102:8031</value> <description>配置rm1与NameNode通信的端口</description> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>192.168.10.103</value> <description>配置rm2服务所在的服务器地址或主机名</description> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>192.168.10.103:8088</value> <description>配置rm2的web端口</description> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>192.168.10.103:8032</value> <description>配置rm2的内部通信端口</description> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>192.168.10.103:8030</value> <description>配置AM向rm2申请资源的端口</description> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>192.168.10.103:8031</value> <description>配置rm2与NameNode通信的端口</description> </property> <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>192.168.10.104</value> <description>配置rm3服务所在的服务器地址或主机名</description> </property> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>192.168.10.104:8088</value> <description>配置rm3的web端口</description> </property> <property> <name>yarn.resourcemanager.address.rm3</name> <value>192.168.10.104:8032</value> <description>配置rm3的内部通信端口</description> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm3</name> <value>192.168.10.104:8030</value> <description>配置AM向rm3申请资源的端口</description> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm3</name> <value>192.168.10.104:8031</value> <description>配置rm3与NameNode通信的端口</description> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>192.168.10.102:2181,192.168.10.103:2181,192.168.10.104:2181</value> <description>配置Zookeeper集群地址</description> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> <description>开启自动恢复/自动故障转移,默认false</description> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> <description>指定ResourceManager的状态信息存储在Zookeeper集群</description> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> <description>环境变量的继承</description> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> <description> 开启日志聚合功能,将分散在各个节点的日志聚集起来,方便查看,默认false </description> </property> <property> <name>yarn.log.server.url</name> <value>http://192.168.10.102:19888/jobhistory/logs</value> <description>配置日志聚集服务器地址</description> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> <description>配置日志保留时间,默认为-1(禁用),单位:秒</description> </property> <!-- 根据集群中各节点性能配置 --> <property> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>50</value> <description>配置ResourceManager处理调度程序接口的线程数,默认50个</description> </property> <property> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> <description> 是否将虚拟核数当做CPU核数,默认false(各节点CPU不同时开启) </description> </property> <property> <name>yarn.nodemanager.resource.pcores-vcores-multiplier</name> <value>1.0</value> <description> 虚拟核数和物理核数乘数,即将当前节点的物理核数当做几倍的虚拟核数使用,默认1.0 </description> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> <description>NodeManager最多使用系统多少内存,默认(8GB)</description> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> <description>NodeManager最多使用的CPU核数,默认8个</description> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>8192</value> <description> 容器的最大内存,默认8192MB。 不能小于2G,不然无法申请容器,因为运行单个容器至少1.5G以上 </description> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> <description>容器的最大CPU核数,默认4</description> </property> </configuration> -
可选配置
<configuration> <!-- ResourceManager --> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> <description> 配置资源调度器,默认CapacityScheduler,并发要求高则选择公平调度器 </description> </property> <!-- NodeManager --> <property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> <description>是否让yarn对节点内存、CPU等进行自动检测,默认false</description> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> <description>是否对容器实施物理内存限制。默认true</description> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>true</value> <description>是否对容器强制执行虚拟内存限制。默认true</description> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> <description>设置容器的内存限制时,虚拟内存与物理内存之间的比率。默认2.1</description> </property> <!-- Container --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> <description>容器的最小内存,默认1024MB</description> </property> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> <description>容器的最小CPU核数,默认1</description> </property> <property> <name>yarn.cluster.max-application-priority</name> <value>0</value> <description> 配置集群中任务的最高优先级,即任务的优先级有几级。默认0,即没有优先级差别,都相同 </description> </property> </configuration>
7.3.4 MapReduce配置文件
配置文件路径:hadoop-3.3.1/etc/hadoop/mapred-site.xml
-
必要配置
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <description>指定MapReduce运行在YARN上。默认本地</description> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.10.102:10020</value> <description> 配置历史服务器地址。 历史服务器:用来查看程序的历史运行情况 </description> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.10.102:19888</value> <description>配置历史服务器的web端地址</description> </property> </configuration> -
可选配置
<configuration> <property> <name>mapreduce.task.io.sort.mb</name> <value>100</value> <description>环形缓冲区大小,默认100MB</description> </property> <property> <name>mapreduce.map.sort.spill.percent</name> <value>0.80</value> <description>环形缓冲区溢写阈值,默认0.80</description> </property> <property> <name>mapreduce.task.io.sort.factor</name> <value>10</value> <description>一次merge的文件数,默认10个</description> </property> <property> <name>mapreduce.map.memory.mb</name> <value>-1</value> <description>MapTask内存,默认1G。</description> </property> <property> <name>mapreduce.map.cpu.vcores</name> <value>1</value> <description>MapTask的CPU核数,默认1个</description> </property> <property> <name>mapreduce.map.maxattempts</name> <value>4</value> <description>MapTask任务失败重试次数,默认4次</description> </property> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>5</value> <description>ReduceTask去Map拉取数据的并行数。默认5</description> </property> <property> <name>mapreduce.reduce.shuffle.input.buffer.percent</name> <value>0.7</value> <description>Buffer占ReduceTask内存的比例,默认0.7</description> </property> <property> <name>mapreduce.reduce.shuffle.merge.percent</name> <value>0.66</value> <description> 当ReduceTask中Buffer占总内存的百分比达到阈值,就会开启merge合并,默认0.66 </description> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>-1</value> <description>ReduceTask内存,默认1G</description> </property> <property> <name>mapreduce.reduce.cpu.vcores</name> <value>1</value> <description>ReduceTask,默认1个</description> </property> <property> <name>mapreduce.reduce.maxattempts</name> <value>4</value> <description>ReduceTask失败的重试次数,默认4次</description> </property> <property> <name>mapreduce.job.reduce.slowstart.completedmaps</name> <value>0.05</value> <description>当MapTask完成的比例达到该值才会为ReduceTask申请资源,默认0.05</description> </property> <property> <name>mapreduce.task.timeout</name> <value>600000</value> <description>apReduce任务超时时间,默认10分钟。</description> </property> <!-- uber模式配置 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> <description>开启uber模式,默认false</description> </property> <property> <name>mapreduce.job.ubertask.maxmaps</name> <value>9</value> <description>uber模式中MapTask的最大数量,默认9个,只能调小</description> </property> <property> <name>mapreduce.job.ubertask.maxreduces</name> <value>1</value> <description>uber模式中ReduceTask的最大数量,默认1个,只能调小</description> </property> <property> <name>mapreduce.job.ubertask.maxbytes</name> <value></value> <description>uber模式中最大的输入数据量,默认为块大小,只能改小</description> </property> </configuration>
7.3.5 集群工作节点配置
配置文件路径:hadoop-3.3.1/etc/hadoop/workers。
添加集群所有主机名(加入集群启动、停止等命令的操作范围)
hadoop102
hadoop103
hadoop104
7.4 集群脚本
#!/bin/bash
if [ $# -ne 1 ]
then
echo "请输入一个参数:start(开启集群)、stop(关闭集群)、format(格式化集群)、status(查看状态)、restart(重启)"
exit;
fi
case $1 in
"start")
echo "===== 开始启动Hadoop集群 ====="
echo "===== 正在启动Zookeeper集群 ====="
myZKServer start
echo "===== 正在启动HDFS ====="
start-dfs.sh
echo "===== 正在启动YARN ====="
start-yarn.sh
echo "===== 正在启动历史服务 ====="
ssh 192.168.10.102 "mapred --daemon start historyserver"
echo "===== Hadoop集群启动成功! ====="
;;
"stop")
echo "===== 开始关闭Hadoop集群 ====="
echo "===== 正在关闭历史服务 ====="
ssh 192.168.10.102 "mapred --daemon stop historyserver"
echo "===== 正在关闭YARN ====="
stop-yarn.sh
echo "===== 正在关闭HDFS ====="
stop-dfs.sh
echo "===== 正在关闭Zookeeper集群 ====="
myZKServer stop
echo "===== Hadoop集群关闭完成! ====="
;;
"format")
echo "===== 开始格式化Hadoop集群 ====="
myhadoop stop
echo "===== 正在删除数据和日志文件夹 ====="
ssh 192.168.10.102 "rm -rf /usr/local/big_data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
ssh 192.168.10.103 "rm -rf /usr/local/big_data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
ssh 192.168.10.104 "rm -rf /usr/local/big_data/hadoop-3.3.1/data /usr/local/big-data/hadoop-3.3.1/logs"
echo "===== 正在格式化集群 ====="
ssh 192.168.10.102 "hdfs --daemon start journalnode"
ssh 192.168.10.103 "hdfs --daemon start journalnode"
ssh 192.168.10.104 "hdfs --daemon start journalnode"
echo "===== 正在格式化NameNode ====="
ssh 192.168.10.102 "hdfs namenode -format; hdfs --daemon start namenode"
ssh 192.168.10.103 "hdfs namenode -bootstrapStandby"
ssh 192.168.10.104 "hdfs namenode -bootstrapStandby"
echo "===== 正在格式化ZKFC ====="
myZKServer start
hdfs zkfc -formatZK
myZKServer stop
stop-dfs.sh
echo "===== Hadoop集群格式化成功! ====="
;;
"status")
echo "===== HDFS ====="
echo "===== 192.168.10.102 ====="
ssh 192.168.10.102 "hdfs haadmin -getServiceState nn1"
echo "===== 192.168.10.103 ====="
ssh 192.168.10.103 "hdfs haadmin -getServiceState nn2"
echo "===== 192.168.10.104 ====="
ssh 192.168.10.104 "hdfs haadmin -getServiceState nn3"
echo "===== YARN ====="
echo "===== 192.168.10.102 ====="
ssh 192.168.10.102 "yarn rmadmin -getServiceState rm1"
echo "===== 192.168.10.103 ====="
ssh 192.168.10.103 "yarn rmadmin -getServiceState rm2"
echo "===== 192.168.10.104 ====="
ssh 192.168.10.104 "yarn rmadmin -getServiceState rm3"
;;
"restart")
myhadoop stop
myhadoop start
;;
*)
echo "未知的参数,请输入一个参数:start(开启集群)、stop(关闭集群)、format(格式化集群)、status(查看状态)、restart(重启)"
;;
esac















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









