







【项目名称】使用python3模块写端口扫描
【项目模块】socket、OptionParser、queue、re、os、threading、dns.resolver
【模块简易概述】
一、socket模块
socket,套接字模块,常用与构造连接时使用,例如与TCP,UDP连接等,使用模块内函数能够与对方达成连接
常用方法及模块:
1、AF_INET
传输控制协议(TCP),其指定的套接字类型为SOCK_STREAM
数据报协议(UDP),其指定的套接字类型为SOCK_DGRAM
2、sock()函数
该函数在创建套接字,即socket对象时使用,如下代码所示
import socket #引入套接字模块
sockconnect = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #创建套接字
sockconnet.connect(("127.0.0.1",135)) #回显连接参量3、connect()函数
如上代码所示,在创建套接字后,紧接着需要做的就是使用套接字创建连接,而连接函数就是connect(),该函数有俩个分支,及有连接有无回显,通常使用到的连接为普通连接“connect()”,该连接不返回任何参量,所以使用者在使用该函数的时候,如若没有try,except的异常抛出的话,很难判断套接字连接有没有成功
与“connect()”函数异曲同工的是“connect_ex()”函数,该函数使用时,作为我这个小白来说,用的就很得心应手,只因connect_ex函数在创立连接之后会有一个返回值来供我们判断是否成功连接(当connect_ex连接的返回值为“0”时,表示连接成功,返回值为非零时,代表连接不成功,及对方连接指定端口为开放,或者主机为开启等);
import socket #引入套接字模块
sockconnect = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #创建套接字
connect_return = sockconnet.connect_ex(("127.0.0.1",135)) #回显连接参量
print(connect_return) #测试回显值,判断是否连接在上述代码中,使用了connect_ex()函数构造套接字连接,成功执行后的结果如下图所示
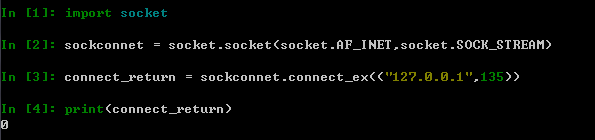
返回值为“0”的参量,说明已经成功连接,那么我们就可以进行下一步的数据回连反弹操作了
4、send(),recv()函数
在建立套接字连接之后,其后续操作就可以使用send()函数来给目标主机发送数据包,构成数据通信,当通信达成后,如果对方开启的端口具有回送信息的能力,那么紧接着我们就可以使用recv()函数的接受功能来接受对方返回的banner,相关操作如下代码所示(接上方连接成功代码)
sockconnet.send("hello\r\n".encode("utf-8"))
print(sockconnet.recv(2048).decode("utf-8"))由于在创立套接字连接的时候,使用的是135端口的连接,而135端口成功连接后,发送数据报文不会有回显字段,所以,使用recv()函数来接受回显后,会造成通讯堵塞的情况,此时强行断开连接都有可能造成卡顿的现象,所以,用到了额外的时延函数:settimeout(),使用该函数后,若在规定时间内无回显字段,则其会自动断开连接
5、成型的socket核心代码块
我一个小白能扯这么多也是不容易了,既然如此,就把我常用socket模块的函数组合成套,贴出如下代码
import socket
socketconnect = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect = socketconnect.connect_ex(("127.0.0.1",80))
if connect == 0:
socketconnect.send("Hello\r\n".encode("utf-8"))
print(socketconnect.recv(2048).decode("utf-8"))二、dnspython模块
我们在扫描端口时,指定IP的扫描是作为最基本的扫描,而大多数情况下,面向用户时,通常用到的是域名的扫描,此时就涉及到了域名以及IP之间的转换,DNS的作用也就不言而喻了,dnspython模块作为我这个python小白唯一想到的模块,其内部函数也是很贴合实际很好用的一个模块
1、参数
A记录,将域名转换成IP地址
MX记录,邮件交换记录,定义邮件服务器的域名
CNAME记录,指别名记录,实现域名间的映射
NS记录,标记区域的域名服务器及授权子域
PTR记录,反向解析,与A记录相反,将IP转换成主机名
SOA记录,SOA标记,一个起始授权区的定义
在上述参数中,本实验用到的仅有“A”参数的使用,将主机名转换成IP地址
import dns.resolver #导入dns解析模块
url = "www.baidu.com" #创建url
ns_url = dns.resolver.query(url,'A') #将域名解析成IP地址
for i in ns_url.response.answer:
for j in i.items:
if j.rdtype == 1:
print(j.address)
上述代码中,执行了解析IP之后,会将数据存放到列表中,但是同样的,其会将域名解析成“cname”和“ip”俩部分(这里笔者就存在了疑惑,“A”解析,不应该是将域名转换成IP地址么,为什么还会出来cname呢,求大佬解释啊)
2、读取列表
上述代码中,我们说到了dns的“A”解析会将解析后的结果存到一个列表中,同样的,他会自身创建一个class类,类中自定义了接口函数,使用函数能够将列表中的内容取出来,如下方测试代码所示,将dnspython解析函数分步抽离出来,依次查看执行后的结果
import dns.resolver
url = "www.baidu.com"
ns_url = dns.resolver.query(url,'A') #将域名解析成ip地址
for i in ns_url.response.answer: #循环取出解析后的内容
print("I内数据:%s,I的类型为:%s"%(i.items,type(i.items)))
for j in i.items: #将列表中的数据循环取出
print("J内数据:%s,J的类型为:%s"%(j,type(j)))
if j.rdtype == 1: #此处为判断解析后的数据为ip地址还是cname,若为ip地址,则将之输出
print(j.address)
上图的解析baidu域名后解析出的均为ip地址,但是发现一个域名出现了俩个不同的ip,所以我们可以判断出其肯定配置了CDN,换一个域名解析后,如下图所示

该域名解析后的结果出现了cname+ip的俩个结果,但是,我们在进行端口扫描时,只会用到ip地址即可,cname没有任何作用,故而,将cname和ip剥离,是我们在解析域名后首要做到的
3、剥离cname和ip地址
下面给大家提供cname提取的一段代码,小弟之前使用的if判断就不嫌丑了
answer = dns.resolver.query(cname,'CNAME')
cname = [_.to_text() for _ in answer][0]
由于时间问题,上述代码未经验证,仅供参考,另外展出大佬提供的知名域名常见的cname
'cname': {
'tbcache.com':u'taobao', # 应该是淘宝自己的。。。。
'tcdn.qq.com':u'tcdn.qq.com', # 应该是腾讯的。。。
'00cdn.com':u'XYcdn', # 星域cdn
'21cvcdn.com':u'21Vianet', # 世纪互联
'21okglb.cn':u'21Vianet', # 世纪互联
'21speedcdn.com':u'21Vianet', # 世纪互联
'21vianet.com.cn':u'21Vianet', # 世纪互联
'21vokglb.cn':u'21Vianet', # 世纪互联
'360wzb.com':u'360', # 360网站卫士
'51cdn.com':u'ChinaCache', # 网宿科技
'acadn.com':u'Dnion', # 帝联科技
'aicdn.com':u'UPYUN', # 又拍云
'akadns.net':u'Akamai', # Akamai
'akamai-staging.net':u'Akamai', # Akamai
'akamai.com':u'Akamai', # Akamai
'akamai.net':u'Akamai', # Akamai
'akamaitech.net':u'Akamai', # 易通锐进
'akamaized.net':u'Akamai', # Akamai
'alicloudlayer.com':u'ALiyun', # 阿里云
'alikunlun.com':u'ALiyun', # 阿里云
'aliyun-inc.com':u'ALiyun', # 阿里云
'aliyuncs.com':u'ALiyun', # 阿里云
'amazonaws.com':u'Amazon Cloudfront', # 亚马逊
'anankecdn.com.br':u'Ananke', # Ananke
'aodianyun.com':u'VOD', # 奥点云
'aqb.so':u'AnQuanBao', # 安全宝
'awsdns':u'KeyCDN', # KeyCDN
'azioncdn.net':u'Azion', # Azion
'azureedge.net':u'Azure CDN', # Microsoft Azure
'bdydns.com':u'Baiduyun', # 百度云
'bitgravity.com':u'Tata Communications', # 待定
'cachecn.com':u'CnKuai', # 快网
'cachefly.net':u'Cachefly', # Cachefly
'ccgslb.com':u'ChinaCache', # 蓝汛科技
'ccgslb.net':u'ChinaCache', # 蓝汛科技
'cdn-cdn.net':u'', # 待定
'cdn.cloudflare.net':u'CloudFlare', # CloudFlare
'cdn.dnsv1.com':u'Tengxunyun', # 腾讯云
'cdn.ngenix.net':u'', # 待定
'cdn20.com':u'ChinaCache', # 网宿科技
【代码核心思路】
一、建立套接字连接,接受回送信息
套接字的定义笔者在文章开头已经有了初步的介绍,且该工具用到socket模块中的函数也仅仅只有最重要的那几个,首先梳理一下核心套接字用到的思路
1、判断端口是否开放模块
端口扫描的首要任务不言而喻,那就是扫描目标端口是否开放,如果开放,我们才能进行后续的一系列的发包,接受包文等操作,而判断端口开放用到的其实也就是上文提到的connect_ex()函数,通过判断该函数的返回值是否为“0”,就能很轻松的判断出端口是否处于开放状态
lsq_sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
lsq_sk.settimeout(0.5) #设置延时
# print("ip地址的是:",self.target)
# print("ip地址的类型是:",type(self.target))
# print("扫描的端口是:",port)
# print("端口的类型是:",type(port))
#target = self.target.replace("\n","") #消除回车
connect = lsq_sk.connect_ex((self.target,port))
#print("当前扫描端口为:%s,返回值为:%s"%(port,connect)) #测试扫描值上述代码为简述socket连接的一个过程,我们只需添加一个判断,判断connect的连接值是否是“0”,然后根据返回值在做后续是否发包的一个判断,废话不多说,直接贴代码
def ScanPort(self,port): #扫描端口,预留线程位
try:
lsq_sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
lsq_sk.settimeout(0.5)
# print("ip地址的是:",self.target)
# print("ip地址的类型是:",type(self.target))
# print("扫描的端口是:",port)
# print("端口的类型是:",type(port))
#target = self.target.replace("\n","") #消除回车
connect = lsq_sk.connect_ex((self.target,port))
#print("当前扫描端口为:%s,返回值为:%s"%(port,connect)) #测试扫描值
if connect ==0:
return True
else:
return False
except Exception as a:
print("scanport抛出异常:%s"%a)
pass
except KeyboardInterrupt:
print("用户自行退出")
exit()
finally:
lsq_sk.close()在上述代码中,使用到了try、except、finally的抛出异常操作,这样做能够更有效的在代码出现错误的时候,查看抛出异常的代码块来进行纠错查询,同时笔者有个不切实际的想法还未付诸实践:在连接之前先对目标主机进行ping命令的操作,这样或许会被防火墙拦截,但是绝大部分数据还是可能通过的,如果ping包发送不成功,那么可能就是目标主机没有开机或者防火墙拦截,这时直接退出当前扫描,开启后续扫描也未尝不可,推荐使用语句
stat, output = commands.getstatusoutput("ping ip")
if stat != '0':
continue
2、接受回送的banner信息
当连接建立成功之后,下一步就是由本地发送信息去构建信息回连,然后通过recv函数来接受对方端口回送的信息并且输出到界面就OK
lsq_sk1 = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
lsq_sk1.settimeout(0.5)
lsq_sk1.connect((self.target,port))
lsq_sk1.send("Hello\r\n".encode("utf-8"))
return lsq_sk1.recv(2048).decode("utf-8")由于之前已经建立连接成功,所以此处不用再使用connect_ex函数来判断回连消息,只需使用connect连接成功后send发送一条指定信息给对方端口,然后在使用recv接受信息就完成了一个信息的沟通,但是由于某些端口在构建连接后没有信息回送,或者己方send发送的信息不是目标端口接受的信息,因此对方接收到信息会将之遗弃,而且不返回banner,所以,我们欲要设置一个延时关闭的命令,防止程序卡死,同理使用try抛出异常的方法来定位错误代码块
def RecvBanner(self,port): #接收返回信息,预留线程位
try:
lsq_sk1 = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
lsq_sk1.settimeout(0.5)
lsq_sk1.connect((self.target,port))
lsq_sk1.send("Hello\r\n".encode("utf-8"))
return lsq_sk1.recv(2048).decode("utf-8")
except Exception as z:
print(z)
pass
except KeyboardInterrupt:
print("用户自行退出")
exit()
finally:
lsq_sk1.close()此时核心代码已经构造完成,后续需要做到的就是完善用户体验以及建立多线程来加快程序运行
二、建立多线程
该端口扫描工具最耗费资源的就是在批量扫描端口的时候,当我们没有指定需要扫描的端口时,此时就需要让程序从1-65535循环扫描所有端口,所以,需要在扫描端口处建立一个多线程,让他能够迅速的扫描目标端口,否则单线程执行的话,65535可能需要跑到过年了
建立线程就需要用到“threading”模块,且线程的理念其实无非就是同一个任务,原本仅有一个人完成,那么时间可能会被无限延长,但是当添加了多人之后的该任务,可能仅需要几时就能完成一个庞大的任务,所以,我们在设定代码时,需要预留一个线程的代码块,来执行扫描端口以及接受banner的任务
Theadpool = []
for i in range(0,int(self.theadnum)): #从0到地址池循环多线程
lsq_th = threading.Thread(target=self.run(),args=())
Theadpool.append(lsq_th) #将线程放入地址池
for st in Theadpool:
st.setDaemon(True)
t.start() #开始跑线程
que.join() #阻塞线程首先建立一个线程池,然后将线程循环放入到进程池中,放入线程池后,循环开始线程,注意,此处需添加join函数来阻塞主线程,只因若主线程结束,那么子线程也会被被迫结束,那么,此时,如果子线程任务未完成的话,可能会对结果造成不可预料的错误,所以,通过阻塞主线程的执行,等待子线程执行完成后再让主线程完成任务即可
三、用户界面完善
人是一个注重美观的生物,所以,当我们在完成了核心代码的书写后,需要对工具的外观进行一些美观处理,此时就用到了“OptionParser”模块,该模块中的函数可以让我们能够添加一些自定义字段来提示用户输入,以及接受用户输入的数据
在使用类中函数时,需定义对象,然后对该对象进行操作
parser = OptionParser()
add_option(),待定义命令行参数以及其帮助文档
parser.add_option('-p','--port',action="store",type="str",dest="port",help="请输入端口")
(option,args) = parser.parse_args(),解析用户命令行输入的内容,由option和args组成,其中,args接收到的内容是所有option没有指定的内容,即add_option中未指定的信息
部分代码如下所示
parser.add_option('-p','--port',action="store",type="str",dest="port",help="请输入端口") #输入指定端口
parser.add_option('-u','--url',action="store",type="str",dest="url",help="请输入域名地址") #输入域名地址
parser.add_option('-i','--ip',action="store",type="str",dest="ipaddress",help="请输入ip地址") #输入ip地址
parser.add_option('-n','--number',action="store",type="int",dest="threadnum",help="请输入线程数") #输入指定线程
parser.add_option('-f','--filename',action="store",type="string",dest="file",help="请输入一个含有扫描信息的文档") #输入文档扫描
parser.add_option('-o','--write',action="store",type="str",dest="writefile",help="指定存储文件") #将扫描结果存储为文件四、功能块完善
作为脚本最后的内容,所完成的功能不要求详尽,但也要尽量完成一些本能的工作,例如:指定IP地址的扫描、给定域名扫描IP、给定文本扫描文本内所有域名或IP、将结果存放到指定文件、扫描指定端口等
1、扫描域名
上文已经提到了DNS的解析过程,所以,此处只需在接受命令行出提供一个解析IP地址的判断即可,不过在传参时需要判断该域名是否添加了CDN
lsq_url = dns.resolver.query(lsq_read,'A')
for i in lsq_url.response.answer:
for j in i.items:
if j.rdtype == 1:
Url = j.address #没有CDN保护
sum+=1
else:
continue
if sum == 1:
with open(option.writefile,"a") as q:
q.write("开始扫描"+Url+",扫描结果如下:")
q.write("\n")
scan = Scan(Url,port,100,option.writefile)
scan.startscan()
else:
print("该域名存在域名CDN防护!!") #有CND保护2、取出文档内容,结果写入文档
其实该功能本质都是对文件的操作,离不开os库的应用
with open(option.file,"r") as l:
lsq_read = l.readline()通过read.line逐行读取文件中数据,不过此处应该注意的是,读取出来的数据会带着回车符,而回车符进入到扫描方法后,就会被系统报错,因此,此处需要把回车符号过滤
read_ip = lsq_read.replace("\n","")
写入文档同理只需要使用write写入即可,不过在使用标签的时候,需使用“a”标签在文本后续写入,而“w”的写入会将前一条数据覆盖
with open(self.write_file,"a") as s:
s.write("[*]%d------------open\t%s"%(port,banner))
s.write("\n")【Github链接】
由于代码太过臃长,不便于放在博客中,因此比这将之传到了Github上,有需要的朋友可以到下方链接下载即可















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









