










1、解压安装包
下载安装包可私聊博主
把安装包放入opt目录下,linux的软件都安装在opt下
/opt目录下,解压命令:tar -zxvf redis-3.0.4.tar.gz
tar -zxvf redis-3.0.4.tar.gz进入redis-3.0.4目录
cd redis-3.0.42、安装make与gcc
在redis-3.0.4目录下执行make命令 (如本地已有gcc可忽略)
运行make命令时故 意出现的错误解析:
yum install gcc二次make
make
make install3、配置profile文件
执行完毕之后执行make install
vim /etc/profile,在文件的末尾添加
-
REDIS_HOME=/data/redis-6.2.1 PATH=/data/redis-6.2.1/src:$PATH export REDIS_HOME PATH -
source /etc/profile -
make test
报错1:Hint: It's a good idea to run 'make test' ;)
make[1]: Leaving directory `/data/redis-6.2.1/src'
报错2:cd src && make clean
make[1]: Entering directory `/data/redis-6.2.1/src'
报错3:You need tcl 8.5 or newer in order to run the Redis test
make: *** [test] Error 1
解决方法:
wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gzsudo tar xzvf tcl8.6.1-src.tar.gz -C /usr/local/cd /usr/local/tcl8.6.1/unix/
sudo ./configuresudo makesudo make installcd /data/redis-6.2.1最后启动即可:redis-server
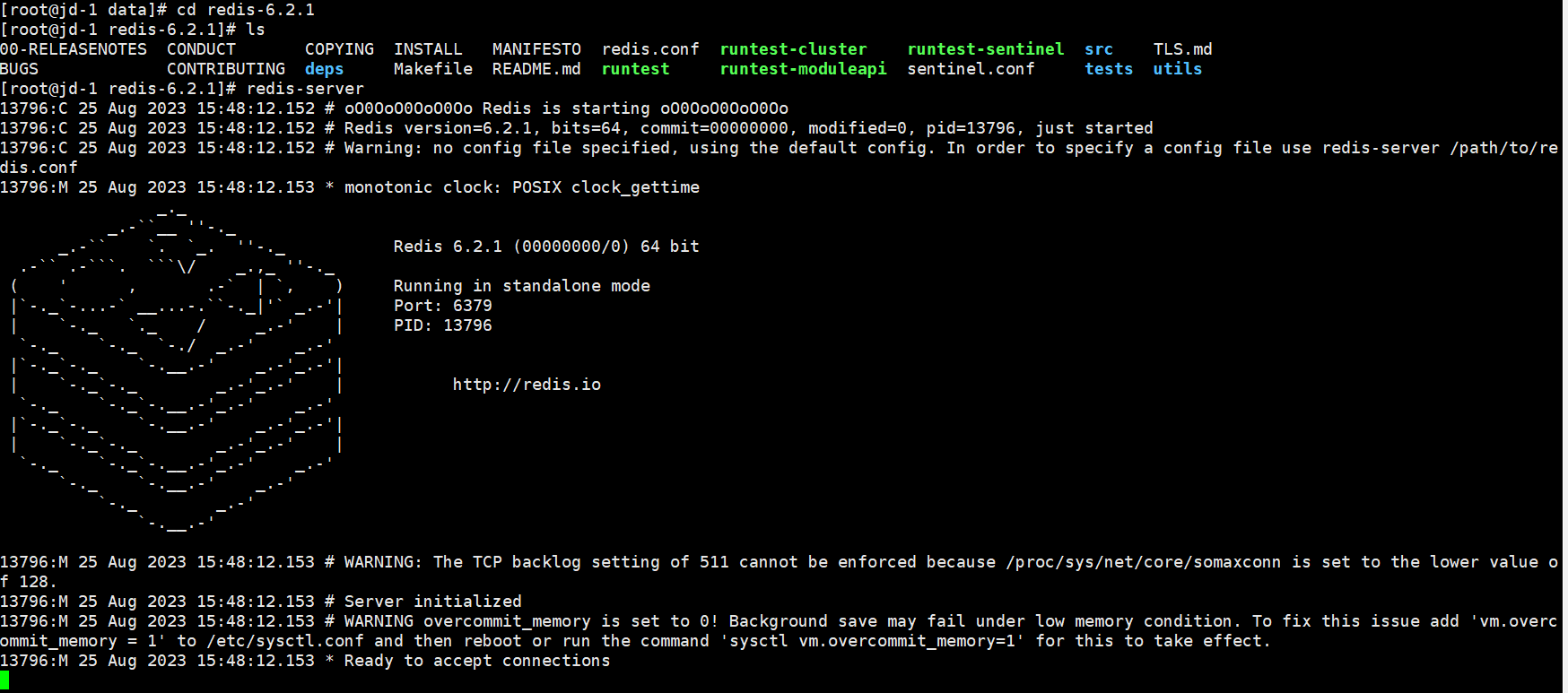
4、设置后台启动
说明
不设置后台启动,关闭窗口后redis就自动关闭了
修改nginx配置(后台启动Redis)
vim redis.conf,将该配置文件中的daemonize no改为daemonize yes
 启动redis
启动redis
[root@jd-1 redis-6.2.1]# redis-server redis.conf
redis-server redis.conf查看redis进程
如:想清理缓存,可直接把进程杀掉后重启 Redis















 8583
8583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











