






关于CRC的理论计算方法不做赘述,本文介绍基于查表的CRC优化算法的实现。
常规计算方法是如何实现的?
理论方法不赘述,这里简单说明程序实现。因为要处理的信息可能非常长,所以直接使用除法指令是不可行的,而且计算机提供的除法指令和有限域上的除法也不一样,所以我们要在一个寄存器的帮助下完成整个CRC除法得到余数的过程。
假设生成多项式(下面简称poly)最高有效位是4,比如10111。
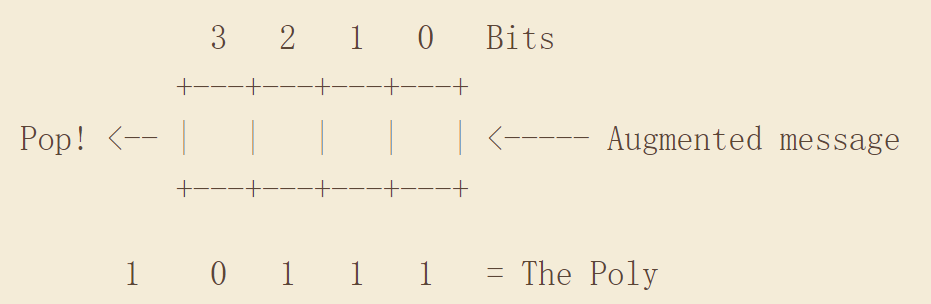
那么我们首先在待处理的数据后面添加4个0(预处理),并引入一个4比特的寄存器。将预处理后的数据以上图的形式从右到左“塞”进寄存器(先进去4比特,多的在后面等着),这样寄存器的最高位目前保存了数据的最高有效位(把数据看出一个很大的二进制数)。按照CRC理论计算的逻辑,我们当前到达了这一步:

想象寄存器内的正是上图红框的内容。我们考虑到,每次在理论计算中执行异或操作,都是1xxxx与10011进行异或,最高有效位的异或结果永远是0,而且这个0不会出现在以后的计算中,所以我们可以将理论计算中的5位异或约简到4位异或。这也是我们使用寄存器位数为4的原因:
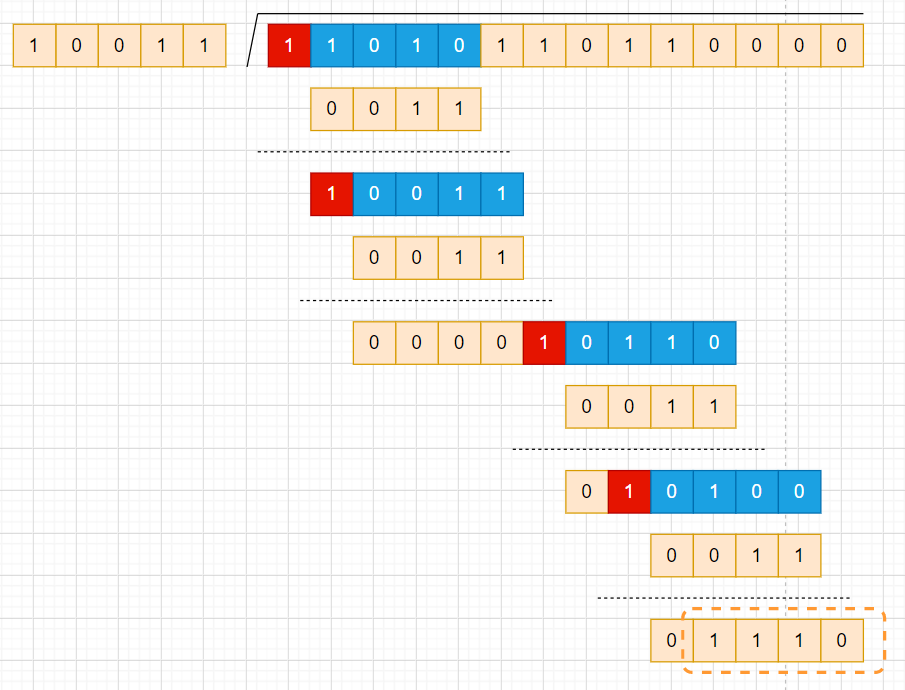
可以从这张改良过程的图片看出关联。想象寄存器循环执行左移操作,每次移出去一位,再从数据源移进一位,直到数据被取完,这个过程类似于寄存器是个大小为4的滑窗,从数据左边滑动到最右边,在这个遍历过程中,每次寄存器最高位(最左侧)上出现了1,就意味着当这个1被移出寄存器后,寄存器内容会和0011执行一次异或,蓝框可以看成每次执行异或时的寄存器,红框是那个刚刚被移出去的1。如果寄存器最高位始终是0,那么不用执行异或操作,只要循环左移直到最高位出现1或者数据被取完。由此可见,红框标出的1似乎是一个flag,每次验证flag后都会执行异或操作。数据被取完时寄存器的值就是最终CRC校验码。
伪代码:
Load the register with zero bits. Augment the message by appending W zero bits to the end of it. While (more message bits) Begin Shift the register left by one bit, reading the next bit of the augmented message into register bit position 0. If (a 1 bit popped out of the register during step 3) Register = Register XOR Poly. End The register now contains the remainder.
为什么常规计算方法不好?
常规计算方法对目标数所在寄存器在比特层面实施移位操作,然而C等高级语言一般处理数据的最小单位是字节,所以常规计算方法不利于程序执行,相对而言效率也不高。
为什么查表法更好?
查表法实现成伪代码后,操作的最小数据单元是字节,克服了上述问题。且每次循环处理目标数的一个字节肯定比循环处理一比特效率很多。
查表法是如何实现的?
以32位(4字节)poly为例,我们将寄存器相应扩展到32位。
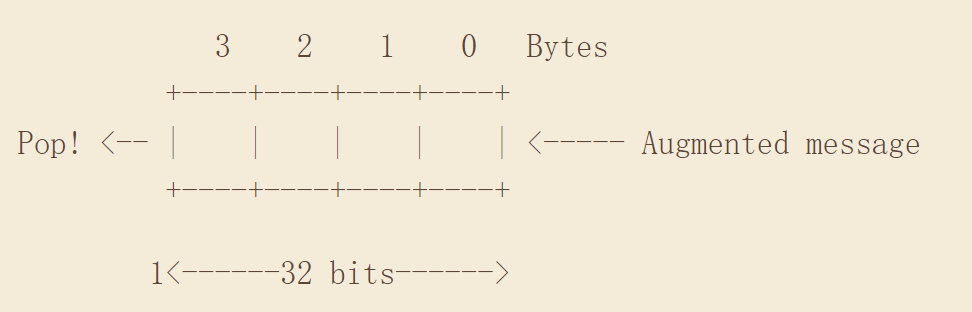
将预处理(补0)后的数据高4字节塞入寄存器中。假设此时寄存器内容如下图所示:

执行左移操作,如果移出去的t31是0,则移位之后的寄存器的内容是

如果移出去的t31是1,则移位之后的寄存器的内容还要与poly按位异或:

所以可以列出式子(t31 = 0 时意味着单纯左移,=1 意味着左移并异或):
t30 t29 t28 t27 t26 t25 t24 t23 ?? + t31 * (g31 g30 g29 g28 g27 g26 g25 g24 ??) [Reminder: + is XOR]
如此处理8次( << 和 XOR 为一次):
t31 t30 t29 t28 t27 t26 t25 t24 t23 ?? << 1 + t31 * (g31 g30 g29 g28 g27 g26 g25 g24 ??) << 1 + (t30 + t31 * g31) * (g31 g30 g29 g28 g27 g26 g25 g24 ??) << 1 + F(t31, t30, t29) * (g31 g30 g29 g28 g27 g26 g25 g24 ??) << 1 + F(t31, t30, t29, t28) * (g31 g30 g29 g28 g27 g26 g25 g24 ??) << 1 ... << 1 + F(t31~t23) * (g31 g30 g29 g28 g27 g26 g25 g24 ??) = new register [Reminder: + is XOR; ?? is remained register content]
简化成
t31 t30 t29 t28 t27 t26 t25 t24 t23 << 1 + A1 << 1 + A2 << 1 + A3 << 1 + A4 << 1 + A5 << 1 + A6 << 1 + A7 << 1 + A8 = new register
其中A1~A8都只和原寄存器最高位字节以及poly的内容有关。注意到每次异或前都会有一次左移的操作,我用另一幅图展示上述过程:
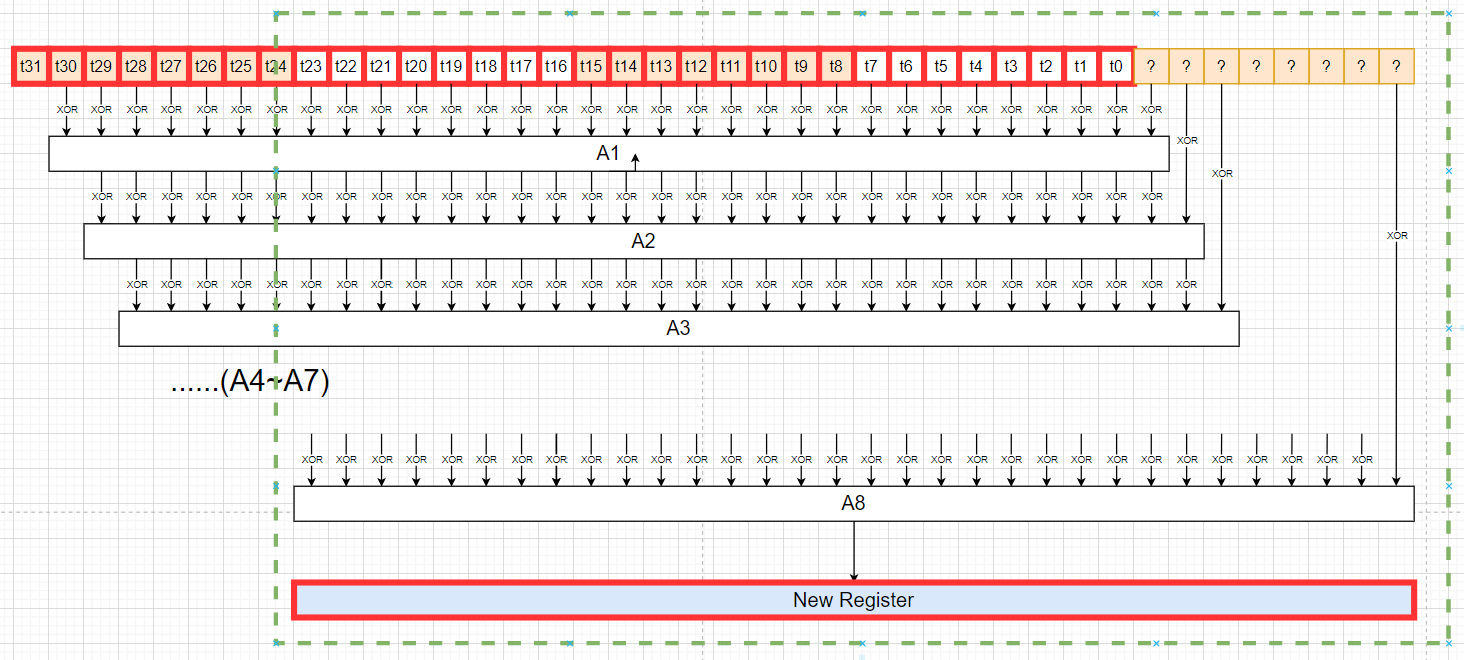
可以看出寄存器在循环左移8次之后的新值和之前寄存器的最高字节无关,新值(New Register)的计算公式已经由绿色框给出,也就是:
reg[t23:t0]|后移入的8个比特 + ((A1<<7)+(A2<<6)+(A3<<5)+(A4<<4)+(A5<<3)+(A6<<2)+(A7<<1)+(A8<<0)) [Reminder: + is XOR]
其中((A1<<7)^(A2<<6)^(A3<<5)^(A4<<4)^(A5<<3)^(A6<<2)^(A7<<1)^(A8<<0)可以由原寄存器最高字节计算出来。
这样我们就有了查表解决CRC的想法。首先建立一张包含2^8=256个表项的表,每个表项的长度是4字节。每个表项可以由唯一的一字节内容索引(原寄存器最高字节就是索引字节),表项内容就是由索引字节和poly一起计算出的((A1<<7)^(A2<<6)^(A3<<5)^(A4<<4)^(A5<<3)^(A6<<2)^(A7<<1)^(A8<<0)。
考虑到这样我们得到伪代码实现:
While (augmented message is not exhausted)
control_bytes = table[(reg >> 24) & 0xFF]
reg = reg << 8
reg = reg XOR control_bytes
# 考虑到操作的一致性,寄存器的值可以初始化成0,每次将数据的一个字节左移到寄存器中,循环4次填满
r=0;
while (len--)
{
byte t = (r >> 24) & 0xFF;
r = (r << 8) | *p++;
r^=table[t];
}
查表法如何进一步优化?
下文讨论的前提:poly最高有效位是32位。
优化的初衷是:一般查表法需要在原数据上补0,然而有些场合不支持补0的操作。
一种直接的优化办法是:将不补0的数据输入一般的查表CRC算法,并在最后补充执行一段代码:
# 假设我们原本需要append w/8字节在message的末尾 While (message is not exhausted) control_bytes = table[(reg >> 24) & 0xFF] reg = reg << 8 reg = reg XOR control_bytes for (i=0; i<W/8; i++) reg = (reg << 8) XOR table[(reg >> 24) & 0xFF];
然而这个方法不够优雅。
细究一般查表法的过程,可以发现:
-
message的第一个字节异或四次后作为表格的输入
-
message的第二个字节异或四次后作为表格的输入
-
message的第三个字节异或四次后作为表格的输入
-
...
-
message的最后一个字节异或四次后作为表格的输入
可以这么说,message的每个字节其实都是经过四次异或后输入表格,输出再与寄存器的值异或,并存储到寄存器中。一般查表法就是通过循环左移,将每个字节在寄存器中“过”一遍(移动四次就异或四次),最后左端弹出作为表格的输入,这样的流程势必导致需要在结尾补32比特0来帮助message最后一个有效字节从寄存器左端弹出。
我们可以通过调整运算顺序来避免这个问题。如果byte ^ A1 ^ A2 ^ A3 ^ A4需要通过将message在寄存器中移位来实现,那如果我们提前计算好B = A1 ^ A2 ^ A3 ^ A4,就可以每次从message提取一个字节byte,计算byte ^ B,并将table[byte ^ B]与当前寄存器进行异或。不用再考虑补0问题。
上面说了思路,下面讲具体实现:
+-----<Message (non augmented) | v 3 2 1 0 Bytes | +----+----+----+----+ XOR----<| | | | | | +----+----+----+----+ | ^ | | | XOR | | | 0+----+----+----+----+ Algorithm v +----+----+----+----+ --------- | +----+----+----+----+ 1. Shift the register left by | +----+----+----+----+ one byte, reading in a new | +----+----+----+----+ message byte. | +----+----+----+----+ 2. XOR the top byte just rotated | +----+----+----+----+ out of the register with the +----->+----+----+----+----+ next message byte to yield an +----+----+----+----+ index into the table ([0,255]). +----+----+----+----+ 3. XOR the table value into the +----+----+----+----+ register. +----+----+----+----+ 4. Goto 1 iff more augmented 255+----+----+----+----+ message bytes.
寄存器初始化为0,假设message的字节流为b1,b2,b3,b4,b5,...,则寄存器在四次循环中的历史值如下所示:

解释一下,
在一般查表法中,若b1在弹出寄存器前执行了b1^A1^A2^A3^A4,则上图中 0 = A1^A2^A3^A4 在一般查表法中,若b2在弹出寄存器前执行了b2^A1^A2^A3^A4,则上图中B1 = A1^A2^A3^A4 在一般查表法中,若b3在弹出寄存器前执行了b3^A1^A2^A3^A4,则上图中C1 = A1^A2^A3^A4 在一般查表法中,若b4在弹出寄存器前执行了b4^A1^A2^A3^A4,则上图中D1 = A1^A2^A3^A4 在一般查表法中,若b5在弹出寄存器前执行了b5^A1^A2^A3^A4,则上图中E1 = A1^A2^A3^A4
简单理解就是,优化后的查表法,寄存器保存的是若干异或的结果,可以想象在算法执行到最后的时候:
-
假如message最后四个字节是
b97, b98, b99, b100,-
在一般查表法中,
-
b97在弹出寄存器前执行了b97 ^ A1 ^ A2 ^ A3 ^ A4, -
b98在弹出寄存器前执行了b98 ^ B1 ^ B2 ^ B3 ^ B4, -
b99在弹出寄存器前执行了b99 ^ C1 ^ C2 ^ C3 ^ C4, -
b100在弹出寄存器前执行了b100 ^ D1 ^ D2 ^ D3 ^ D4, 设table[ b100 ^ D1 ^ D2 ^ D3 ^ D4] = E4, -
那么寄存器最后保存的CRC码为
B4 ^ C4 ^ D4 ^ E4, C4 ^ D4 ^ E4, D4 ^ E4, E4
-
-
在优化查表法中,
-
b97在从message中取出前,寄存器内容为A1^A2^A3^A4, B1^B2^B3, C1^C2, D1
-
b98在从message中取出前,寄存器内容为B1^B2^B3^B4, C1^C2^C3, D1^D2, B4
-
b99在从message中取出前,寄存器内容为C1^C2^C3^C4, D1^D2^D3, B4^C4, C4
-
b100在从message中取出前,寄存器内容为D1^D2^D3^D4, B4^C4^D4, C4^D4, D4
-
那么寄存器最后保存的CRC码为
B4 ^ C4 ^ D4 ^ E4, C4 ^ D4 ^ E4, D4 ^ E4, E4
-
-
由此证明两个算法取得的最终结果一致。
伪代码实现为:
r=0; while (len--) r = (r<<8) ^ t[(r >> 24) ^ *p++];
如此优化后的CRC算法称为 DIRECT TABLE ALGORITHM.















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









