







文本幽默相关研究
作者贡献
1、 第一次通过相关句子信息以及相关知识背景生成笑点。
2、 提出了一个框架,可以将知识融合到端到端的模型。
3、 提供了第一个与笑话配对的知识数据集。
一、数据集准备
采用Kaggle上的Short Joke dataset和Reddit-Joke dataset当做生语料,然后对笑话语料进行笑话过滤、笑点分割以及笑话重复删除:
1、 过滤:删除特殊符号,并保留笑话中至少两个句子和15个单词。
2、 笑点分割:笑话最后一句作为笑点,之前作为相关句子信息(set-up sentence)。
3、 笑话重复删除:用词袋模型和余弦相似度来删除重复,大于0.93的就删除。
同时,为了获得set-up sentence中的知识背景,作者使用了实体链指工具TagMe将句子中的实体与维基百科链接,并保留置信区间大于0.1的实体,然后在使用SPARQL链指维基百科以获得与实体相关的三元组k。
二、模型大纲:
1.主体思路
知识库三元组由头实体-关系-尾实体组成,表示为k=(s, r, o)。已知相关句子背景X = { x 1 x_1 x1, x 2 x_2 x2, . . . , x p x_p xp}和知识库三元组K = { k 1 k_1 k1, k 1 k_1 k1, . . . , k u k_u ku},得出笑点Y = { y 1 y_1 y1, y 2 y_2 y2, . . . , y q y_q yq}。
2.模型方法
模型架构:
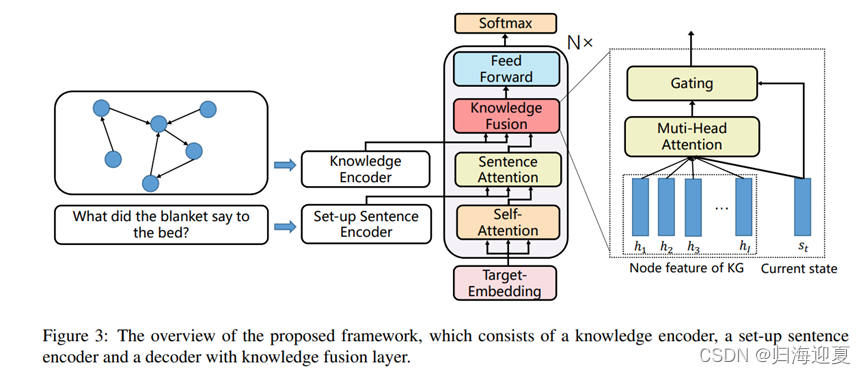
以原始transformer结构为基础,加入了knowledge encoder和knowledge fusion layer,knowledge encoder主要包含了知识图谱中的隐藏特征,而knowledge fusion layer是将知识特征融合到了解码过程。
1、 构建知识图谱:
利用三元组集合K创建知识图谱并建立头实体-关系-尾实体之间的链接,同时为了使得信息流能够从尾实体转向头实体,作者加入了反转关系节点,如下,三元组以及对应的知识图谱,红色是实体,绿色是关系节点,蓝色是反转关系节点:
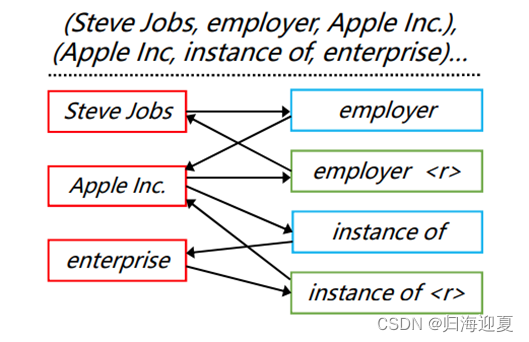
由于维基数据中的实体和关系可能会有多重含义表达,因此作者使用双向LSTM对这些字进行编码,并采用最后一层的隐藏状态作为初始节点特征(具体使用LSTM对字进行编码的方式不太清楚,感觉是直接把三元组放到LSTM来获取最后一个隐藏状态)。最终得到一个链接图谱,G = (V, E,
H
0
H_0
H0 ),V是节点集合,E是边的集合,H0是V的初始特征集。
2、 知识编码:
编码层使用graph attention network来融合相邻节点的特征,下面是一个graph attention network的网络结构,网络细节可以参考:graph attention network阅读笔记
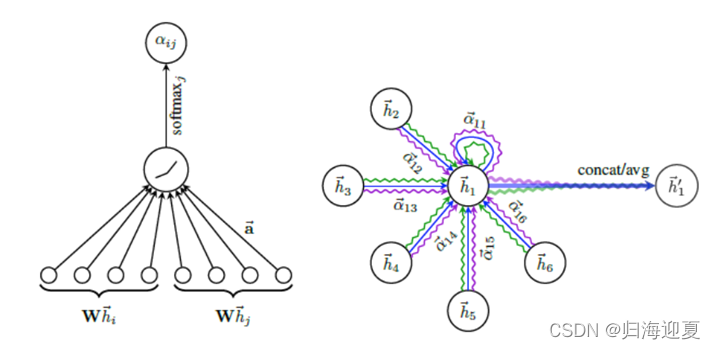
计算过程跟self attention基本一致:
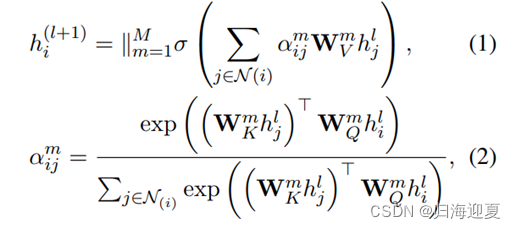
h
i
l
h_i^l
hil表示节点i在l层的特征,乘以QK权重并经过softmax函数得到分数a,然后再乘V得到下一层节点i的特征。
3、 知识融合层:
Decoder部分由n个blocks构成,每一个blocks由图中四个子层构成。在知识融合层之前与transformer的操作一致,set-up sentence encoder + sentence attention是多头掩码注意力层,由此输出的隐藏状态为
s
n
s_n
sn。
知识融合层包含多头注意力以及门控机制:
(1)、 多头注意力:
A
n
A_n
An = MultiHead(
s
n
s_n
sn , H, H).
(2)、 门控机制(高速网络结构):与原始论文解决深度网络难以训练的目标不同,作者引入门控机制目的是权衡set-up sentence和相关知识图谱之间的影响,原因是因为知识图谱会受到知识链指工具的扰动(应该就是LSTM的结果不准确)。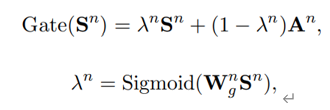
其中λ是门机制权重,
W
g
W_g
Wg是模型参数
最后再通过全连接层,得到最后的状态,通过softmax函数得到概率,选出最优的目标单词。
评估
使用ROUGE-1, ROUGE-2和ROUGE-L自动化评估工具,用来测量输出和参考之间的相似度,同时还进行了人为评估生成文本的幽默程度。
参考
https://arxiv.org/abs/2004.13317
https://zhuanlan.zhihu.com/p/34232818


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









