









文章目录
介绍
ThreadLocal,作者:Josh Bloch and Doug Lea
- ThreadLocal提高一个线程的局部变量,访问某个线程拥有自己局部变量。
- 当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
static final ThreadLocal<T> sThreadLocal = new ThreadLocal<T>();
sThreadLocal.set()
sThreadLocal.get()
在 ThreadLocal 源码实现中 ,涉及到了 :数据结构、拉链存储、斐波那契数列、神奇的 0x61c88647、弱引用Reference、过期 key 探测清理等等
应用场景
局部变量案例
public class test {
public static void main(String[] args) {
Res res=new Res();
Thread thread = new Thread(res,"线程1");
Thread thread2 = new Thread(res,"线程2");
thread.start();
thread2.start();
}
}
class Res implements Runnable {
public static Integer count = 0;
public Integer getNumber(){
return count++;
}
@Override
public void run() {
for (int i = 0; i < 3 ; i++) {
System.out.println(Thread.currentThread().getName()+ ","+getNumber());
}
}
}

- 发现我们线程1 和 线程2 多线程情况下,共享了线程变量,我们需要一个线程获取私有变量
public class test {
public static void main(String[] args) {
Res res=new Res();
Thread thread = new Thread(res,"线程1");
Thread thread2 = new Thread(res,"线程2");
thread.start();
thread2.start();
}
}
class Res implements Runnable {
//创建ThreadLocal
public static ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public Integer getNumber() {
int count = threadLocal.get() + 1;
threadLocal.set(count);
return count;
}
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println(Thread.currentThread().getName() + "," + getNumber());
}
}
}

- 每个线程都有自己的私有变量也就是局部变量
- ThreadLocal对象可以提供线程局部变量,每个线程Thread拥有一份自己的副本变量,多个线程互不干扰。
数据结构
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
……
}
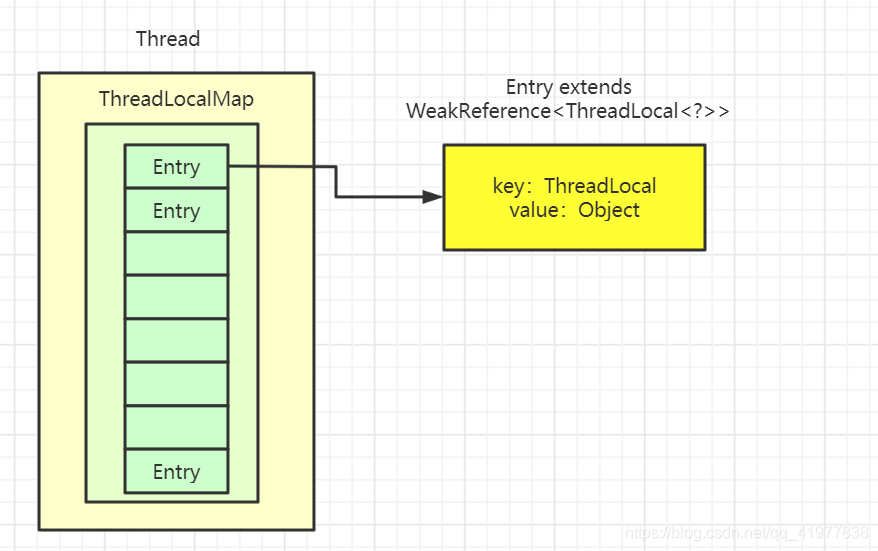
从源码中可以看到 ,ThreadLocal 底层采用的数组数据存储结构 如图 :
-
它是一个数组结构 Entry[] ,它的key是ThreadLocal<?> k ,继承自WeakReference, 也就是我们常说的弱引用类型
-
Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,也就是说每个线程有一个自己的ThreadLocalMap。
-
每个线程在往ThreadLocal里放值的时候,都会往自己的ThreadLocalMap里存,读也是以ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
-
ThreadLocalMap有点类似HashMap的结构,只是HashMap是由数组+链表实现的,而ThreadLocalMap中并没有链表结构。
ThreadLocal 为什么要用弱引用 ?
弱引用解释:
只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
注意:WeakReference引用本身是强引用,它内部的(T reference)才是真正的弱引用字段,WeakReference就是一个装弱引用的容器而已。
为什么用弱引用:
Thread -> ThreadLocal.ThreadLocalMap -> Entry[] -> Enrty -> key(threadLocal对象)和value
如上链路所示,这个链路全是强引用,当前线程还未结束时,他持有的都是强引用,包括递归下去的所有强引用都不会被垃圾回收器回收,
当把ThreadLocal对象的引用置为null后,没有任何强引用指向内存中的ThreadLocal实例,threadLocals的key是它的弱引用,故它将会被GC回收。下次,我们就可以通过Entry不为null,而key为null来判断该Entry对象该被清理掉了。
key为什么被设计为弱引用
假如每个key都强引用指向ThreadLocal的对象,也就是强引用,那么这个ThreadLocal对象就会因为和Entry对象存在强引用关联而无法被GC回收,造成内存泄漏,除非线程结束后,线程被回收了,map也跟着回收。
当把ThreadLocal对象的引用置为null后,没有任何强引用指向内存中的ThreadLocal实例,threadLocals的key是它的弱引用,故它将会被GC回收。下次,我们就可以通过Entry不为null,而key为null来判断该Entry对象该被清理掉了。
Hash算法
既然是Map结构,那么ThreadLocalMap当然也要实现自己的hash算法来解决散列表数组冲突问题。
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
private static final int HASH_INCREMENT = 0x61c88647;
private static AtomicInteger nextHashCode =
new AtomicInteger();
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
每当创建一个 ThreadLocal 对象 ,这个 ThreadLocal.nextHashCode 这个值就会增长 0x61c88647
这个值 ,它是斐波那契数 也叫 黄金分割线。 为了让数据更加散列,减少 hash 碰撞
为什么使用 0x61c88647
- 学过数学都应该知道,黄金分割点是,(√5 - 1) / 2,取 10 位近似 0.6180339887。
- 之后用 2 ^ 32 * 0.6180339887,得到的结果是:-1640531527,也就是 16 进制的,0x61c88647。这个数呢也就是这么来的
public class test {
private static final int HASH_INCREMENT = 0x61c88647;
public static void main(String[] args) {
test_idx();
}
static public void test_idx() {
int hashCode = 0;
for (int i = 0; i < 16; i++) {
hashCode = i * HASH_INCREMENT + HASH_INCREMENT;
int idx = hashCode & 15;
System.out.println("斐波那契散列:" + idx + " 普通散列: " + (String.valueOf(i).hashCode() & 15));
} }
}
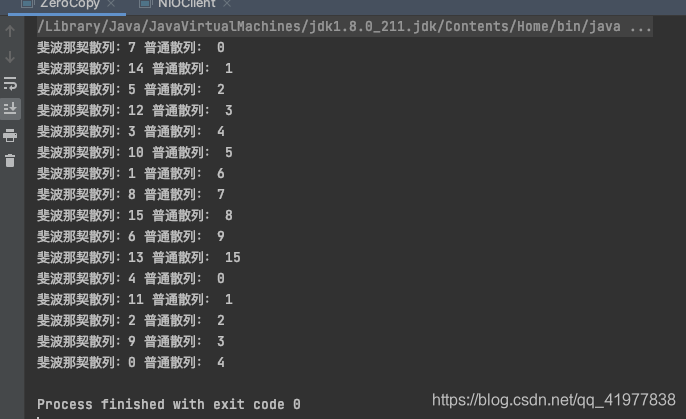
斐波那契散列的非常均匀,普通散列到 15 个以后已经开发生产碰撞。这也就是斐波那契散列的魅力,减少碰撞也就可以让数据存储的更加分散,获取数据的时间复杂度基本保持在 O(1)。
Hash冲突
- 虽然ThreadLocalMap中使用了黄金分割数来作为hash计算因子,大大减少了Hash冲突的概率,但是仍然会存在冲突。
- HashMap 中解决冲突的方法 是在数组傻狗构造一个链表结构,冲突的数据挂载到链表上,如果链表长度超过一定数量会转化成红黑树,而 ThreadLocal 中没有链表结构,所以这里不能使用 HashMap解决冲突的方式了。
- ThreadLocal 采用线性探测的方式,所谓线性探测,就是根据初始key的hashcode值确定元素在table数组中的位置,如果发现这个位置上已经有其他key值的元素被占用,则利用固定的算法寻找一定步长的下个位置,依次判断,直至找到能够存放的位置。
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
源码解读
ThreadLocalMap
- ThreadLocal中的嵌套内部类ThreadLocalMap,这个类本质上是一个map,和HashMap之类的实现相似,依然是key-value的形式,其中有一个内部类Entry,其中key可以看做是ThreadLocal实例,但是其本质是持有ThreadLocal实例的弱引用
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
/**
* The initial capacity -- MUST be a power of two.
*/
private static final int INITIAL_CAPACITY = 16;
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
/**
* The number of entries in the table.
*/
private int size = 0;
/**
* The next size value at which to resize.
*/
private int threshold; // Default to 0
/**
* Increment i modulo len.
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
……
}
}
set 添加元素
ublic void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
//获取当前map中是否存在 key 注:key就是当前线程
ThreadLocalMap map = getMap(t);
// map 不等于 null 调用 ThreadLocalMap 的 set(this, value);
if (map != null)
map.set(this, value);
else
// 在当前线程创建ThreadLocalMap
createMap(t, value);
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new `ThreadLocalMap`(this, firstValue);
}
private void set(ThreadLocal<?> key, Object value) {
//Entry,是一个弱引用对象的实现类,static class Entry extends WeakReference<ThreadLocal<?>>,
// 以在没有外部强引用下,会发生GC,删除 key。
Entry[] tab = table;
int len = tab.length;
//计算数组下标 hash算法
int i = key.threadLocalHashCode & (len-1);
// for循环快速找到插入位置
for (Entry e = tab[i];
e != null;
//向后查找值
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// 如果k已经有了,则直接覆盖
if (k == key) {
e.value = value;
return;
}
// 如果为 null
if (k == null) {
// 替换过期数据的方法 ---- 下面讲解
replaceStaleEntry(key, value, i);
return;
}
}
// 设置值
tab[i] = new Entry(key, value);
int sz = ++size;
// cleanSomeSlots 清除老旧的Entry(key == null)启发式清理)
// 如果没有清理陈旧的 Entry 并且数组中的元素大于了阈值,则进行 rehash (扩容)
if (!cleanSomeSlots(i, sz) && sz >= threshold)
//扩容方法 ------后面讲
rehash();
}
replaceStaleEntry 替换元素
// 在执行set操作时,获取对应的key,并替换过期的entry
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// slotToExpunge 表示开始探测式清理过期数据的开始下标 默认当前是staleSlot 开始
// 以当前的 staleSlot 开始,向前迭代查找,找到没有过期的数据
// for许那还一直碰到Entry 为 null 才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为i,即 slotToExpunge = i
int slotToExpunge = staleSlot;
//向前遍历查找第一个过期的实体下标
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 开始从 staleSlot 向后查找,也是碰到 Entry 为null 的桶结果
// 如果迭代中 碰到k == key,这说明了这里是替换逻辑,替换新数据并且交换当前 staleSlot 位置
// 如果 slotToExpunge == staleSlot, 说明 之前向前查询过期数据和向后查找都未找到过期数据
// 修改开始探测式清理过期下标为当前循环的index ,即slotToExpunge = i。
// 最后调用cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);进行启发式过期数据清理。
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果找到key 和新数据替换
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 进行清理过期数据
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果 k != key往下走,key = null 说明当前遍历的 Entry 是一个过期数据
// slotToExpunge == staleSlot说明,一开始的向前查找数据并未找到过期的Entry
// 如果条件成立,则更新 slotToExpunge 为当前位置(这个前提是前驱节点扫描未发现过期数据)
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// 往后迭代过程中如果没有找到 k = key的数据,且碰到Entry为null的数据,
// 则结束当前的迭代操作,此时说明这里是个添加逻辑,将新的数据添加到table[staleSlot] 对应的slot中
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// 如果有其他已经过期的对象,那么需要清理他
if (slotToExpunge != staleSlot)
// 进行清理过期数据
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
为什么要交换
- 我们先来看看如果不交换的话,经过设置值和清理过期对象,会是以下这张图

- 这个时候如果我们再一次设置一个key=15,value=new2 的值,通过f(15)=5,这个时候由于上次index=5是过期对象,被清空了,所以可以存在数据,那么就直接存放在这里了

- 这样整个数组就存在两个key=15 的数据了,这样是不允许的,所以一定要交换数据
expungeStaleEntry 探测清理
- ThreadLocalMap的两种过期key数据清理方式:探测式清理和启发式清理。
- expungeStaleEntry 探测式清理,是以当前遇到的 GC 元素开始,向后不断的清理。直到遇到 null
为止,才停止 rehash 计算 Rehash until we encounter null。
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 首先将 tab[staleSlot] 槽位的数据清空
// 然后设置 然后设置size--
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
// 以 staleSlot 位置往后迭代
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果遇到 key == null 的 过期数据,也是清空该槽位数据,然后 size--
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
// 如果 key != null 表示key没有过期,重新计算当前key的下标位置是不是当前槽位下标位置
// 如果不是 h != i ,那么说明产生了 hash 冲突 ,此时以新计算出来正确的槽位位置往后迭代
// 找到最后一个存放 entry 的位置
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
---------- 翻译 ----------
/**
* 这段话提及了Knuth的 R算法 我们和 R算法的不同
* 我们必须扫描到null,因为可能多个条目可能过期
* ThreadLocal使用了弱引用,即有多种状态,(已回收、未回收)所以不能安全按照R算法实现
*/
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
cleanSomeSlots 启发式清理
- ThreadLocalMap的两种过期key数据清理方式:探测式清理和启发式清理。
- cleanSomeSlots 启发式清理 试探的扫描一些单元格,寻找过期元素,也就是被垃圾回收的元素。当添加新元素或删除另一个过时元素时,将调用此函数。它执行对数扫描次数,作为不扫描(快速但保留垃圾)和与元素数量成比例的扫描次数之间的平衡,这将找到所有垃圾,但会导致一些插入花费 O(n)时间。
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
// do while 循环 循环中不断的右移进行寻找被清理的过期元素
// 最终都会使用expungeStaleEntry 进行处理
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
rehash 扩容机制
- 在ThreadLocalMap.set() 方法最后,如果执行完成启发式清理工作后,未清理到任何数据,且当前散列数组中 Entry 的数量已经达到了列表的扩容阀值 就开始执行 rehash() 逻辑
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
rehash()具体实现:
private void rehash() {
// 先进行探测式清理工作,从table的起始位置往后清理,------清理过程如上------
expungeStaleEntries();
// 清理完成之后,table 中kennel有一些 key 为 null 的 Entry 数据被清理掉
// 所以此时通过判断 size >= threshold - threshold / 4 来决定扩容
if (size >= threshold - threshold / 4)
resize();
}
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
// 从table的起始位置往后清理
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
resize()具体实现
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
// 扩容后的大小为 oldLen * 2
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
//然后遍历老的散列表
for (int j = 0; j < oldLen; ++j) {
Entry e = oldTab[j];
//当前 Entry 不为null
if (e != null) {
ThreadLocal<?> k = e.get();
// 如果 key 为null,将value 也设置为null 帮助 GC垃圾回收
if (k == null) {
e.value = null; // Help the GC
} else {
// key不为null的情况,重新计算 hash 位置
int h = k.threadLocalHashCode & (newLen - 1);
//放到新的 tab 中,如果出现hash冲突则往后寻找最近的entry为null的槽位
//遍历完成之后,oldTab中所有的entry数据都已经放入到新的tab中了。重新计算tab下次扩容的阈值
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
get 获取元素
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取 map 是否有值
ThreadLocalMap map = getMap(t);
//不等于空
if (map != null) {
//获取值
ThreadLocalMap.Entry e = map.getEntry(this);
// 如果不等于空直接返回
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//设置初始化
return setInitialValue();
}
private Entry getEntry(ThreadLocal<?> key) {
//定位出数组中的下标
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
// 对应的entry存在且未失效且弱引用指向的ThreadLocal就是key,则命中返回
if (e != null && e.get() == key)
return e;
else
// 因为用的是线性探测,所以往后找还是有可能能够找到目标Entry的。
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 基于线性探测法不断向后探测直到遇到空entry。
while (e != null) {
ThreadLocal<?> k = e.get();
// 找到目标 直接返回
if (k == key)
return e;
if (k == null)
// 该entry对应的ThreadLocal已经被回收,调用expungeStaleEntry来清理无效的entry
expungeStaleEntry(i);
else
// 环形意义下往后面走
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
remove 删除元素
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
//计算key下标
int i = key.threadLocalHashCode & (len-1);
// 遍历清除元素
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
// 探测清理
expungeStaleEntry(i);
return;
}
}
}
ThreadLocal内存泄露
- 如上,我们知道 expungestaleEntry() 方法是帮助垃圾回收的,根据源码,我们会发现 get 和 set 方法都会触发清理方法 expungestaleEntry() ,所以正常方法不会有内存益处,但是如果我们没有调用 get 与 set 方法的时候可能会面临这内存溢出,所以我们要养成不使用的时候调用 remove 方法加快垃圾回收,避免内存溢出
- 在线程的复用中,一个线程的寿命很长,大对象长期不被回收而影响系统运行效率与安全,导致内存泄漏
InheritableThreadLocal
- 我们使用 ThreadLocal 的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的
- 为了解决这个问题,JDK中还有一个 InheritableThreadLocal 类
测试:
public class a {
public static void main(String[] args) {
ThreadLocal<String> ThreadLocal = new ThreadLocal<>();
ThreadLocal<String> inheritableThreadLocal = new InheritableThreadLocal<>();
ThreadLocal.set("父类数据:threadLocal");
inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("子线程获取父类`ThreadLocal`数据:" + ThreadLocal.get());
System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());
}
}).start();
}
}

实现原理是子线程通过父线程中通过调用 new Thread() 方法 创建子线程,Thread#init方法在Thread的构造方法中被调用。在init方法中拷贝父线程数据到子线程中:
Thread init() 方法源码
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
/* Stash the specified stack size in case the VM cares */
this.stackSize = stackSize;
/* Set thread ID */
tid = nextThreadID();
但InheritableThreadLocal仍然有缺陷,一般我们做异步化处理都是使用的线程池,而InheritableThreadLocal是在new Thread中的init()方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个TransmittableThreadLocal组件就可以解决这个问题,这里就不再延伸,感兴趣的可自行查阅资料。
个人博客地址:http://blog.yanxiaolong.cn/














 2684
2684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









