







 java中for循环遍历和stream流内部遍历究竟谁更好?究竟哪种遍历操作效率更好呢?数据说话,下面做了一组小测试,分别统计了遍历100、1000、100000等等数据量的情况下的耗时情况,考虑到jdk存在自动gc操作,所以耗时数据取三次测试的均值,均值方式也仅仅只是减少gc对测试结果的影响—(测试方法有待斟酌,数据仅做参考) 注:测试代码贴在文章最后测试结果下面是所有测试数据:数据量for循环串行流并行流1000988.7100014.390
java中for循环遍历和stream流内部遍历究竟谁更好?究竟哪种遍历操作效率更好呢?数据说话,下面做了一组小测试,分别统计了遍历100、1000、100000等等数据量的情况下的耗时情况,考虑到jdk存在自动gc操作,所以耗时数据取三次测试的均值,均值方式也仅仅只是减少gc对测试结果的影响—(测试方法有待斟酌,数据仅做参考) 注:测试代码贴在文章最后测试结果下面是所有测试数据:数据量for循环串行流并行流1000988.7100014.390
java中for循环遍历和stream流内部遍历究竟谁更好?

究竟哪种遍历操作效率更好呢?数据说话,下面做了一组小测试,分别统计了遍历100、1000、100000等等数据量的情况下的耗时情况,考虑到jdk存在自动gc操作,所以耗时数据取三次测试的均值,均值方式也仅仅只是减少gc对测试结果的影响—(测试方法有待斟酌,数据仅做参考)
注:测试代码贴在文章最后
测试结果
下面是所有测试数据:
| 数据量 | for循环 | 串行流 | 并行流 |
|---|---|---|---|
| 100 | 0 | 9 | 88.7 |
| 1000 | 1 | 4.3 | 90 |
| 10000 | 2 | 6 | 105 |
| 50000 | 6 | 5.3 | 68.7 |
| 100000 | 10.7 | 11.7 | 80.7 |
| 500000 | 15 | 14.7 | 103 |
| 1000000 | 15.3 | 16.7 | 101 |
| 5000000 | 23 | 24.3 | 90.3 |
| 10000000 | 31.3 | 26.7 | 76.7 |
| 50000000 | 82 | 50.7 | 73.7 |
| 100000000 | 141.7 | 102.3 | 102.3 |
图表展示如下,耗时单位ms:
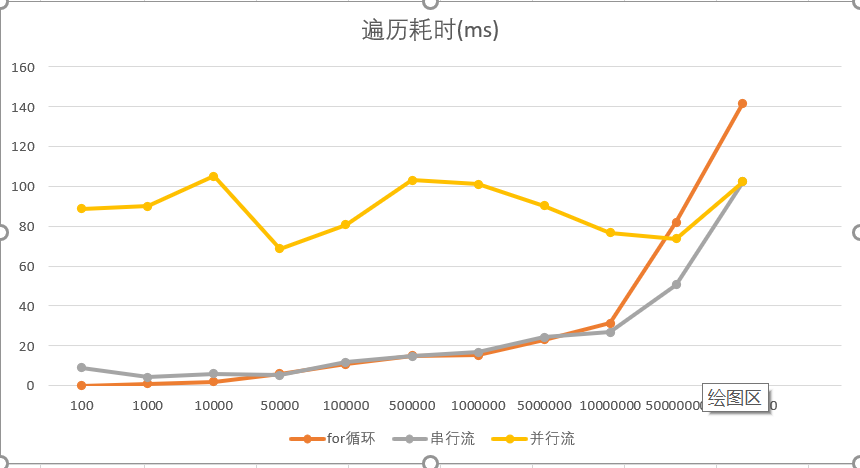
测试结论:数据量较少的时候(<50000),for循环遍历效率高于流操作,当数据量较大时,流操作的内部遍历效率将高于for循环遍历。
数据量小时使用流操作,在构建流时会产生性能消耗,当数据量变大后,使用到并行流时,多线程情况,这时速度也就起来了
总结:stream这种“高端操作”效率就一定比for循环效率高只是映像流,在数据量不大的情况下for循环会拥有更高的遍历速度,我们使用到流操作是为什么呢?—函数式编程整体代码也更加简洁,可读性也更高
java中的那些遍历操作
在java当中遍历数据的方式分为三种:普通for循环遍历、迭代器(Iterator)遍历、增强for循环(for each)遍历,如下代码所示:
// 普通for循环遍历
for(int var1 = 0 ; var1 < list.size() ; var1++){
System.out.println(list.get(var1));
}
// 迭代器遍历
Iterator<Integer> iterator = list.listIterator();
while (iterator.hasNext()){
Integer integer = iterator.next();
System.out.println(integer) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









