






本文介绍一种面向AVS3可缩放的帧内优化方法。该工作为北京大学Zhang Jiaqi等人所做,隶属于高文院士团队。
摘要:提出的优化方案为scalable intra coding optimization (SICO) scheme。该文章分析了在AVS3中帧内编码过程中不同划分之间以及不同预测模式之间的复杂度分布和继承关系,在快划分和预测两个过程中分别提出了优化方法:
- 对于块划分,使用一个训练好的由数据驱动的二元分类器,进行CU划分的决策。
- 对于预测模式,之前编码的信息可以被充分利用,以决策当前的模式。
所提方案内嵌了一个可以调节的因子,通过调整该因子可是实现在不同编码收益和编码复杂度之间的权衡。实验结果表明,该方案可以将编码复杂度减少18%~76%。
I 在introduction中,作者列出了文章的主要贡献:
- 全面的分析了AVS3中CU划分和帧内预测的复杂度分布。这是一个先驱性的工作,由于与未来AVS3商业编码器的发展。
- 借助于一个one-for-all的分类器,为CU划分提出了一个提前终止方案。该分类器能够和不同的QP协同工作。此外,通过定义一些在帧内模式决策过程中的继承属性,设计了一个inheritability-inspired 的决策规则,用来跳过一些模式。
- 提出了一个联合块划分和帧内预测优化的框架。编码时间可以减少18%到76%。
II related works (跳过)
III Motivation and Analysis
首先分析了CU划分中的编码复杂度和继承关系。这里面可以注意一下作者对于AVS3复杂度的描述:编码尺寸从AVS2的64x64扩展到AVS3的128x128。划分形状从QT扩展到增加额外的BT和EQT。这样带来的复杂度提升是,所有划分的可能从85种扩展到224324。有做硬件编码器的朋友就能够体会到,如果没有快速算法的辅助或者不删掉一些模式,这样22万种模式的遍历,硬件上压力会非常大。而对于软件来说,这直观的体现在编码时间的剧增上。
回到正文,作者使用下图表述了不同划分模式的复杂度分布。
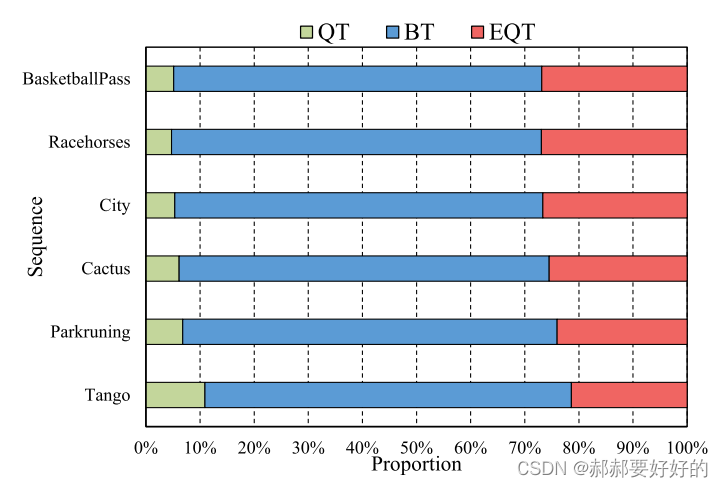
从上图中可以看出,BT和EQT占据了绝大多数的比例。值得一提的是,只有QT可以继续迭代使用三种划分方式,即QT划分的子节点,可以继续迭代使用QT+BT+EQT。而BT/EQT的子节点不能再使用QT划分了。这也是导致QT划分所占比例很少的原因。
为了更好的说明划分过程中继承特性,作者定义了PMγ来表征当前CU的最优划分模式。其中γ指的就是划分模式(QT、BT_HOR、BT_VER、EQT_HOR、EQT_HOR)。如下如所示:

在软件编码器中,整个划分模式的决策是基于深度优先的策略。如下如所示,对于128x128的LCU,首先会默认做QT,接着对于每个子CU,会基于深度优先一次遍历。即将CU1的所有模式遍历完之后,再进行CU的模式遍历。最终决策出最优的划分模式。
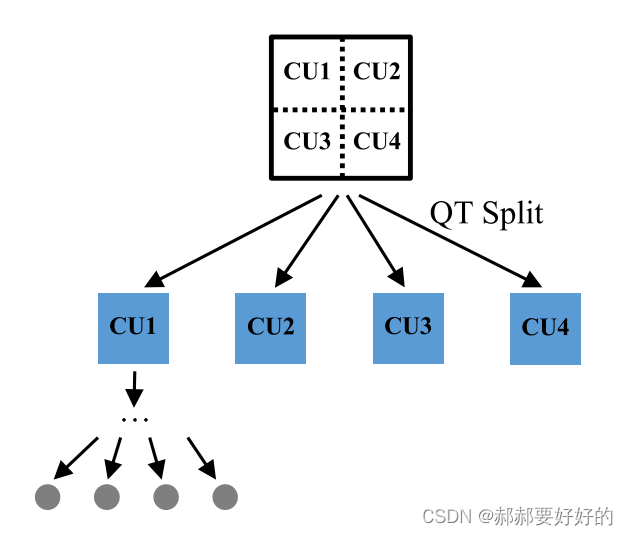
作者认为,这种顺序处理的顺序会导致尝试很多冗余的编码模式,带来非常大的RDO复杂度。他们认为,在已经编码过的模式的信息可能能够指导接下来的划分模式决策,这些信息包括但不限于RD cost和划分深度(split depth)。 作者使用Dq和Dbe分别表示QT和BT/EQT的划分深度。每进行一次QT划分,Dq会加一。每进行一次BT/EQT,Dbe会加一。注意,Dbe从QT的子节点开始从0计数。
接着,作者开始探索局部内容,RDcost,和划分结构之间的关系。以下图为例:作者做了如下归纳:
- 越平滑的区域,CU越大,深度更浅,RDcost更小。
- 越复杂的区域,CU越小,划分结构越复杂。
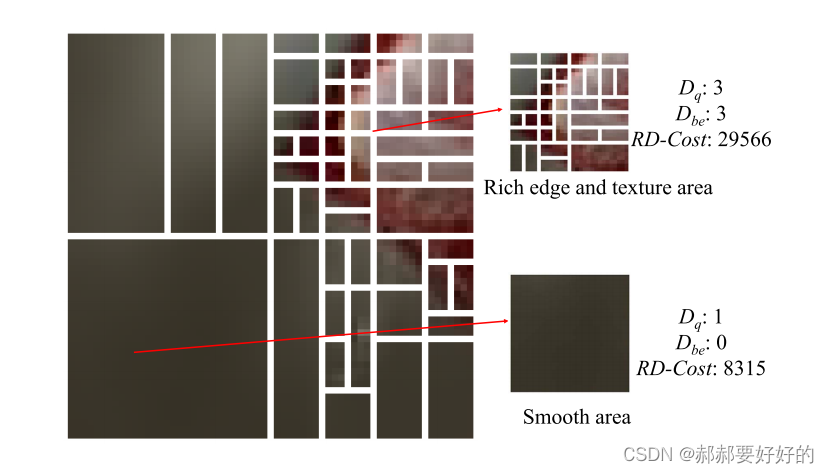
基于上述分析,作者猜测,RDcost,Dq和Dbe或许可以用来决定BT和EQT模式是否可以被跳过。
首先是深度Dq和Dbe是否和划分有关呢?对此,作者做了一组实验。在该实验中首先做了一些定义:
CUm,n:指的是,当前CU的Dq等于m,当前CU所处的最大QT子节点中最大Dq等于n。(这里理解可能有误,个人认为该变量指示了当前CU的划分深度。比如CU0,3指的是,当前LCU中,最大QT深度为3,但是当前CU只处于深度0)
Rm,n定义如下:
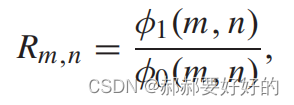
Φ1(m,n)指的是在CUm,n中选择QT作为划分模式的CU数量,Φ0(m,n)表示在CUm,n中选择划分的CU数量。这样的话,Rm,n其实就是反映了对于CUm,n(这是一大族CU),QT划分在所有划分结果中所占的比重。此外,还定义了δ=n-m。(当前CU的Dq深度与最大Dq深度之间的差距)。作者给出了如下的统计结果: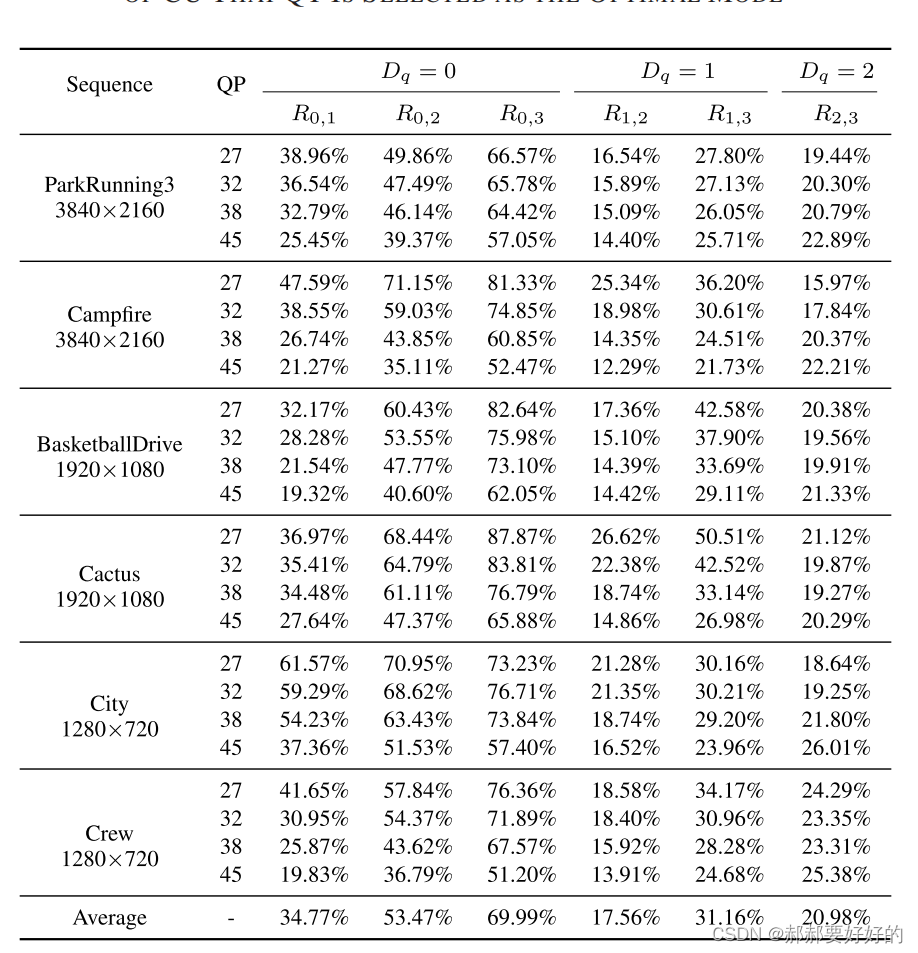
根据上述统计结果,作者总结了如下发现:
- 随着δ的增加,比例Rm,n也变得更大,甚至可以高达87%。当δ=3的时候,比例的平均值最大。
- R2,3的值比较小。平均只有20.98%。这是因为在AVS3中QT的最小尺寸是8x8,对于16x16以及他的子CU,QT仅能使用一次。
越高的Rm,n表明越多的CU选择跳过BT和EQT,即选择了QT。(这句话的内在含义是,因为QT,BT,EQT是顺序遍历的,如果选择QT的比例高,就意味着越多的CU可以跳过后面两种划分尝试,这是在保证编码效果的同时减少复杂度的内在机理。)此外,越大的δ,Rm,n越大。这就激励作者去探索,使用δ去决策BT/EQT的划分。为了验证有效性,作者设计了如下的算法实验:当δ大于或等于阈值S时,就跳过BT/EQT。S的取值可以为1,2,3。实验结果如下: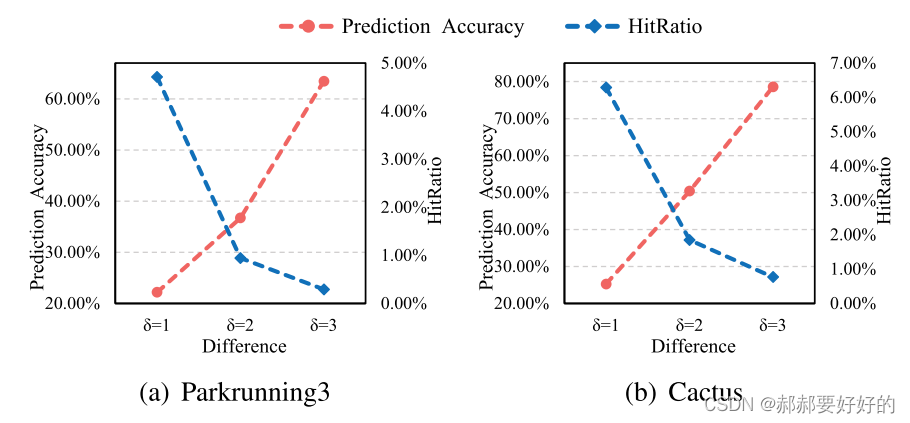
作者定义预测准确率和命中率如下:
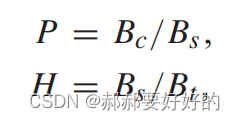
其中Bc是正确跳过BT/EQT的数量。Bs是使用δ进行跳过BT/EQT的CU数量。Bt是在块划分过程中,所有的CU的数量。可以看到,随着δ的增加,预测精度不断提高。将近80%。但是命中率却在下降,低于1%。(这里给出一些笔者对该结果的理解:命中率低,说明随着阈值的增加,使用δ进行跳过BT/EQT的条件越苛刻,所以用该方法进行跳过操作的CU数量就越少。反应在具体的编码过程中,就是能够使方法生效的CU越少,对编码时间的减少就越不明显。预测精度高,与上面的统计实验给的结果相符,即当δ大于一定阈值的时候,该CU就是倾向于跳过BT/EQT)。
因此,为了增加命中率(减少编码时间)以及保持较高的预测精度,作者将纹理特征,梯度等信息纳入了考量。因为像下图所示,BT/EQT划分对于方向性的纹理特征比较敏感。于是,作者引入了四个纹理梯度:Sh, Sv, S45, S135。结合刚刚所描述的继承信息δ,作者提出了一个二元分类器去预测使用BT/EQT的概率。这会在后面详细介绍。
以上是对划分模式的分析,下面作者对于帧内编码工具之间的复杂度和继承性进行了探索。
首先作者给出了一个复杂度分布的总览,如下:
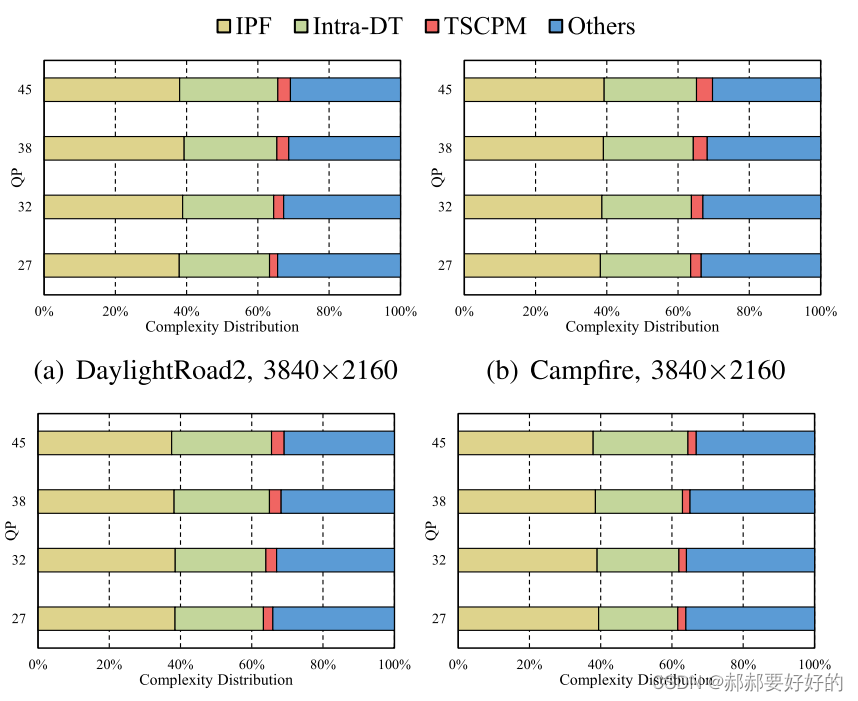
可以看到,Intra_DT和IPF占据了平均60%的复杂度。TSCPM和常规的帧内预测占据了大约40%。在这里简要说明一下AVS3中帧内编码模式的过程:
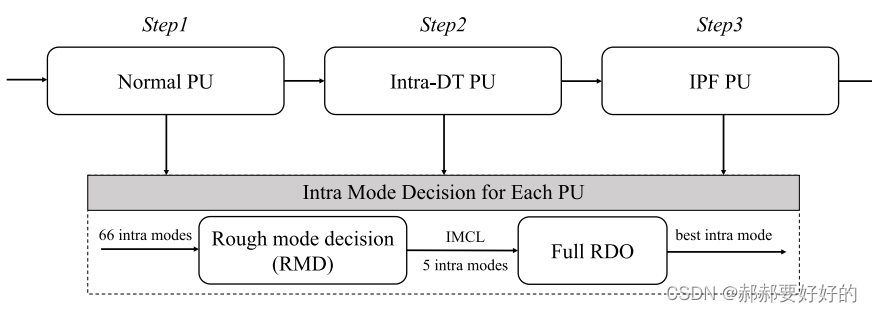
主要分为三个步骤。 依次是,常规PU,Intra-DT PU以及IPF PU。常规PU指的是当前CU不使用intra_DT和IPF工具,直接进行各种模式的判决。Intra_DT PU指的是会将当前的CU进行划分,具体的划分原则如下:
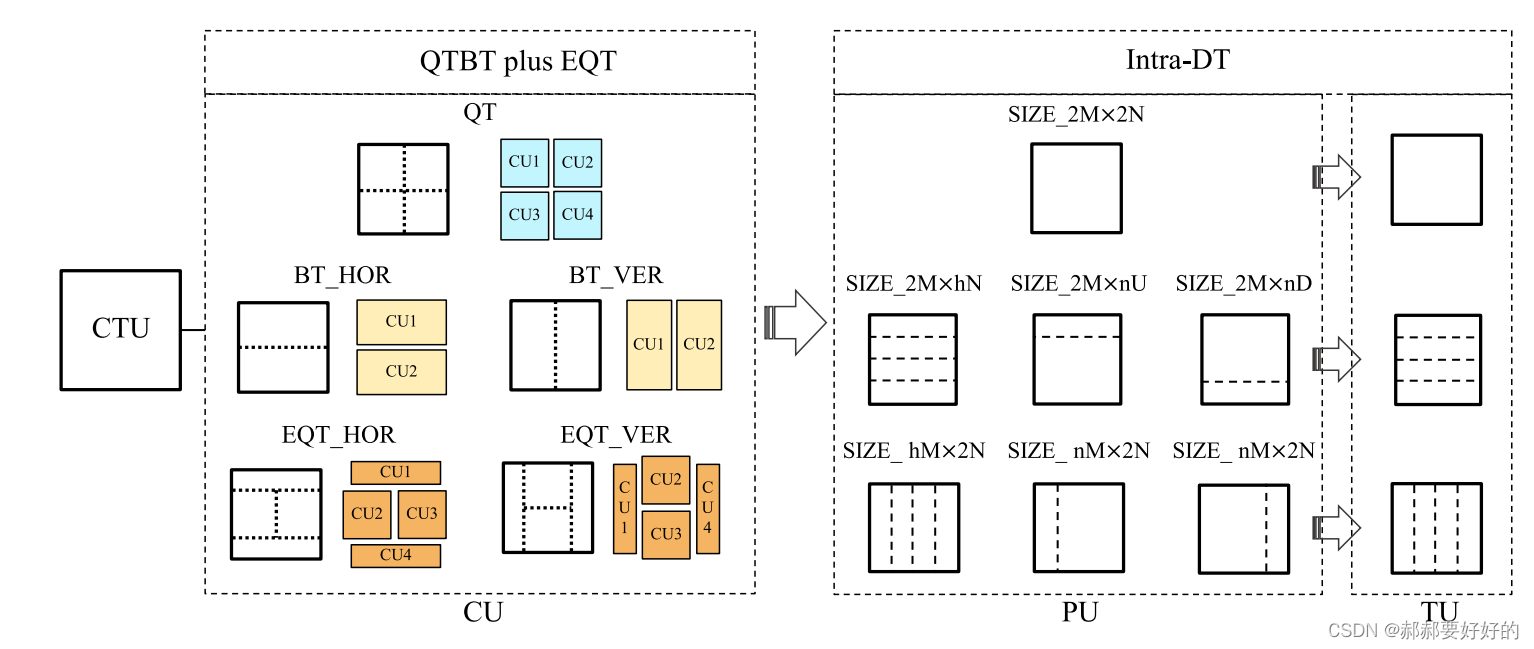
IPF指的是,对相应的PU进行滤波之后产后的PU。这是在做帧内预测时,PU的三种来源。
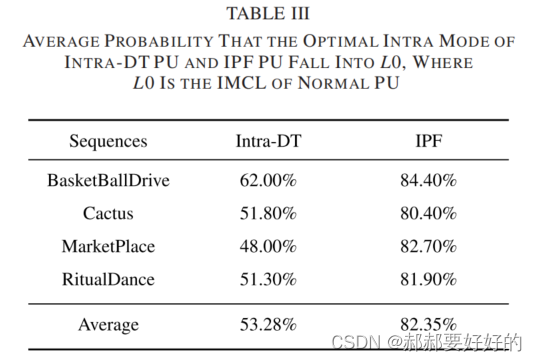
作者用L0来表征normal PU。下表给出了最优模式从Intra_DT 和IPF模式落在L0(尝试Intra_DT和IPF模式后,最终RDO仍然选择了normal PU作为最优模式)上的概率。可以看到,最终落到L0上的概率还是蛮高的。作者展示了一个内在机理,即Intra_DT会将PU进行划分,在一定程度上增加了灵活性,倾向于获得更好的预测结果,因此Intra_DT落回L0的概率相对偏低。IPF是对整个CU进行处理,相对灵活度不是那么高,因为额外增加了标志位等,所以落回L0的概率会更大。因此,作者推测,可以使用前一种工具在决策时的一些信息,用来指导后续工具的决策。具体表述为“First, the IMCL in step1 can be inherited by step2 and step3. Second, the decision state of step2 can be inherited by step3.”即step1中的信息可以被step2和3利用,step2的信息可以被step3利用。
IV The proposed SICO Method
(这一章介绍了具体的SICO的方案,上面只是给出了分析,说明所提方案的合理性,这一章中给出了具体的proposal的设计)
下图是SCIO中对于块划分和预测模式决策的流程图: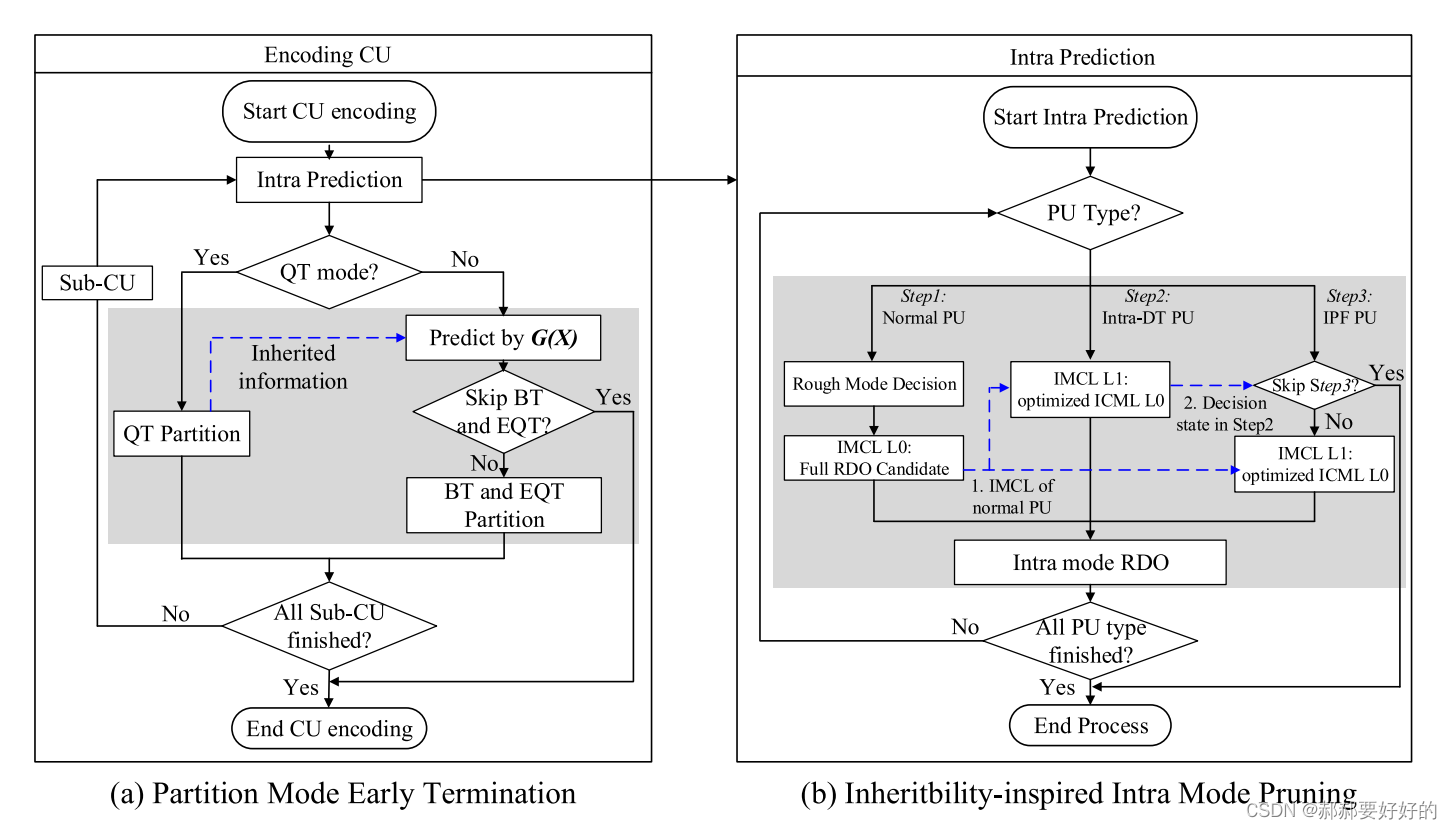
首先介绍基于决策分类器的提前终止机制:
由前文介绍可知,δ可以用来用来决定是否跳过BT/EQT,但是会存在命中率比较低的情况(也就是对复杂度的减少并不明显)。为了能够提高命中率同时保证预测精度,将BT/EQT的使用定义为二元分类的问题:C={w0,w1}。w0代表跳过BT/EQT,w1代表进行BT/EQT划分。
论文作者使用AdaBoost分类器作为解决上述问题的方案。由于网上对于AdaBoost的介绍比较详细,在这里就不赘述了。不清楚的小伙伴可以参考这篇博客:AdaBoost介绍。在分类器G(X)中使用的特征集合如下:
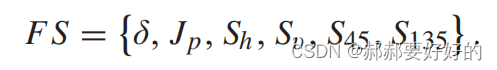
其中,Jp=J/PN,J是QT划分的cost,当前CU总的像素数量(相当于将cost做了一个归一化)。四个角度方向的梯度定义如下:
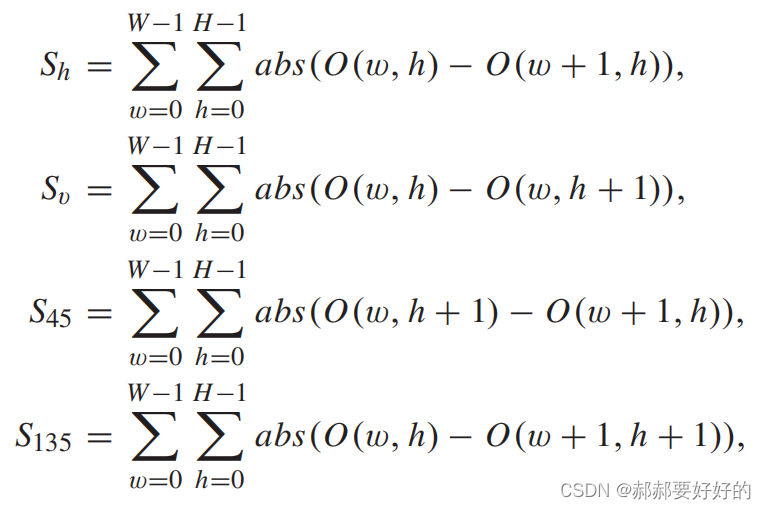
最终分类器的决策式子为:
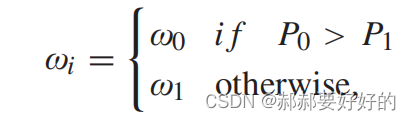
其中P0和P1就是对应不使用BT/EQT和使用BT/EQT的相对概率(文章在介绍AdaBoost分类器的时候给了结算过程)。 P0和P1的值调控了划分的决策。
对于上述分类过程,如果分类器给出的结果是w0,这说明跳过了BT/EQT,这可以减少编码复杂度。但是一旦,有原本应该使用BT/EQT的CU被错误的决策成了w0,那么就会带来编码性能的损失。因此为了调控这个过程,作者加了一个调控因子θ。如下:
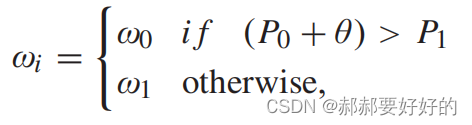
通过调整θ可以控制算法选择跳过BT/EQT的难易程度,当θ增大时,if判断会更容易满足,从而使得更多的块倾向于选择跳过BT/EQT,进而导致编码复杂度下降以及编码精度的下降。(这也是文章标题scalable含义的由来,通过调控θ控制精度和复杂度的tradeoff。)
下面介绍继承性启发式的帧内模式剪枝:
在对模式的处理上,作者提了两个方法
第一,省略Intra_DT和IPF模式下RMD的过程。RMD是从65中帧内预测模式中,粗选出5种,送入到完整的RDO过程中,进而做出最优决策。在原始的AVS3帧内编码的过程中,normal PU,Intra_DT PU,以及IPF PU三者都要各自完成自己的RMD过程,这样复杂度就会很高。作者通过,使用L0(normal PU通过RMD得到的mode list)的modes以及邻域PU的modes,为Intra_DT和IPF重新构造了IMCL L1,从而使他们不用再去做RMD,而直接进入RDO过程。进一步的,因为L0的最优模式一定会保留在L1中,所以对于Intra_DT和IPF,实际进入RDO过程的modes只有4中(这是因为L0中的最优模式一定会保存下来,该模式的cost是可以直接拿到的)。
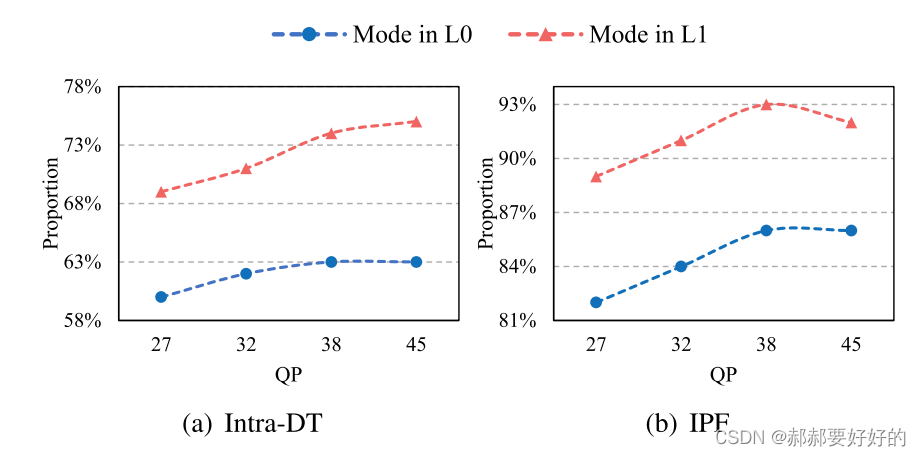
之所以可以像上面那样构造L0,省去独立的RMD,是因为作者的统计实验表明,在Intra_DT和IPF的决策过程中,选出的最优模式最终落在L0中的概率高达63%和86%。说明在这两种模式在决策时,更倾向于选择normal PU选出的最优结果。同时,下图也展示了,在编码过程中,Intra_DT和IPF选出的最优模式,落在所构建的L1中的比例高达75%和93%。这反映了L1能够提供比较高的预测精度。
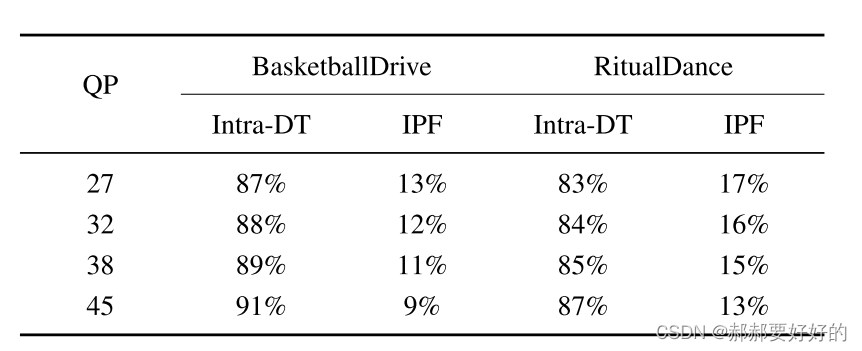
第二,通过Intra_DT的计算过程决定是否跳过IPF。作者做了一个统计实验。同意了当Intra_DT的RD-cost比normal PU小时,最优模式落在Intra_DT和IPF上的比例。下表给出了实验结果。可以看到,在上述条件下,约86%的PU选择Intra_DT作为最优的模式,而IPF的比例则非常小。这说明,在满足上述条件下,跳过IPF也不会带来太大的损失。
V Experimental Results
最后展示文章给出的实验结果。
首先是加速效果。时间节省定义如下:
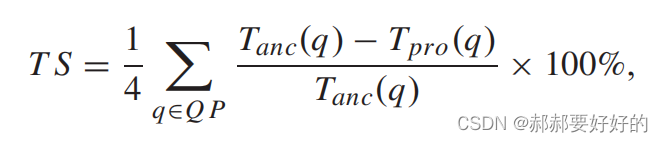
性能表格如下:
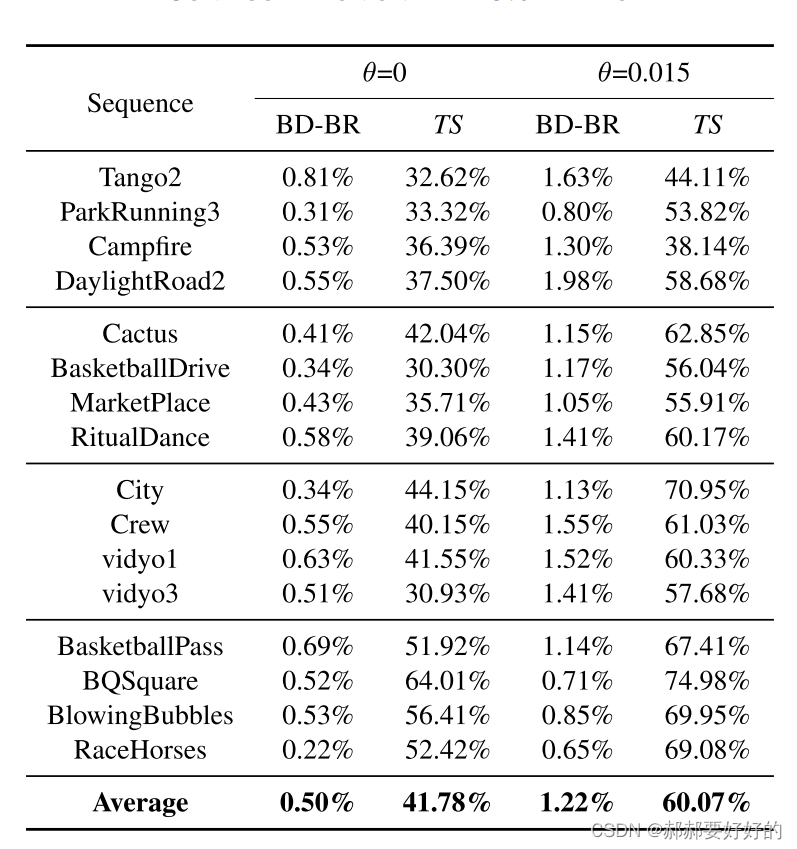
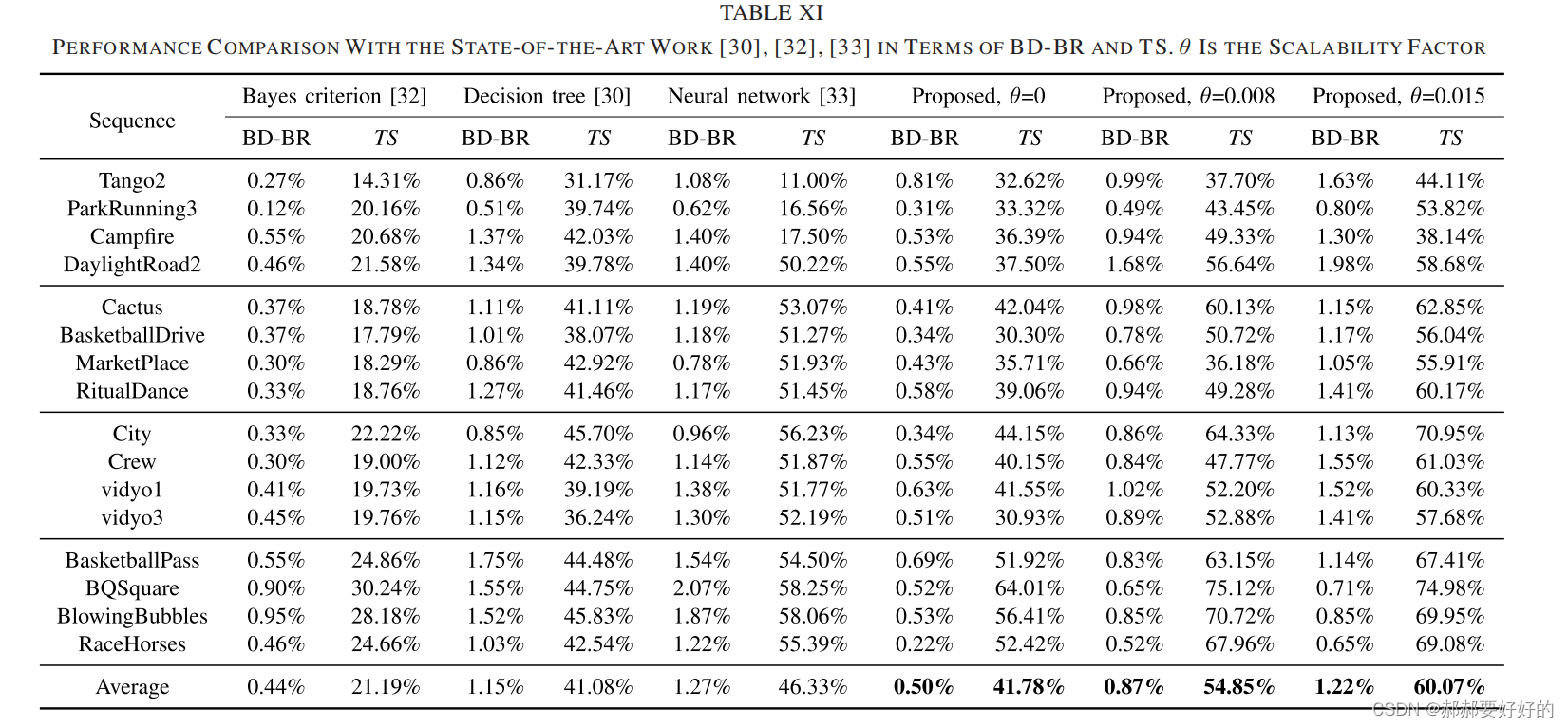
可以看到在不同的调控因子θ的控制下,proposal可以提供不同的编码收益和加速效果的tradeoff。时间节省从41.78%~60.07%。
然后作者又给出了独立使用两种优化方法所带来的单独的效果。
首先是对于划分的提前终止算法:

也是可以通过θ进行调控,BD_rate损失范围为0.05%~0.73%。加速比范围为17.98%~44.26%。
接着是对模式的剪枝算法:
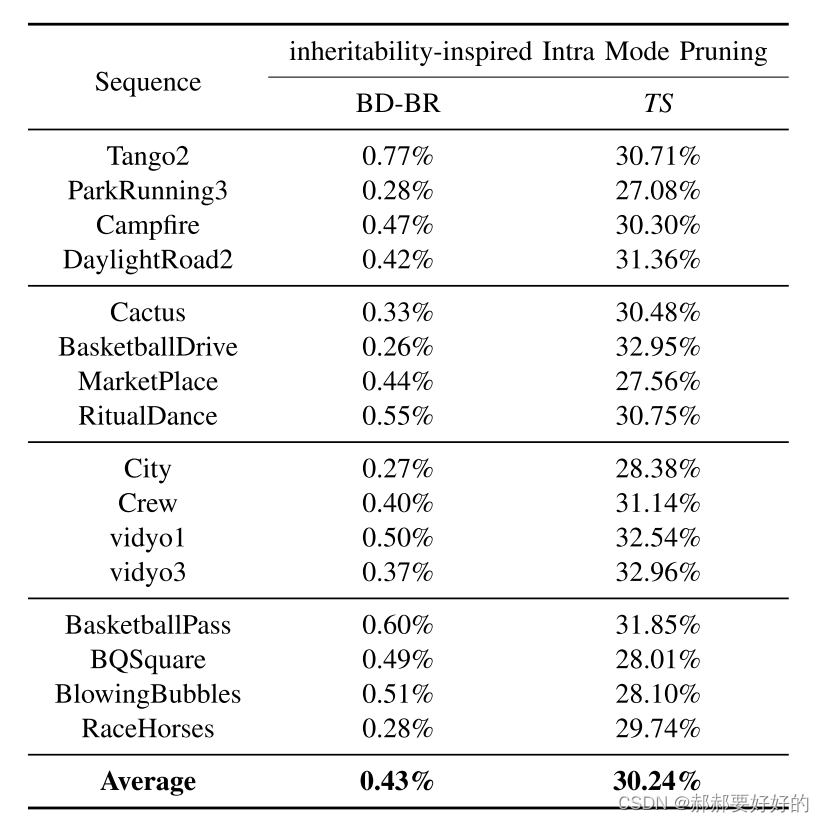
该剪枝算法能够提供30.24%的加速,损失仅有0.43%。
此外,作者还提供了预测精度和命中率的分析。
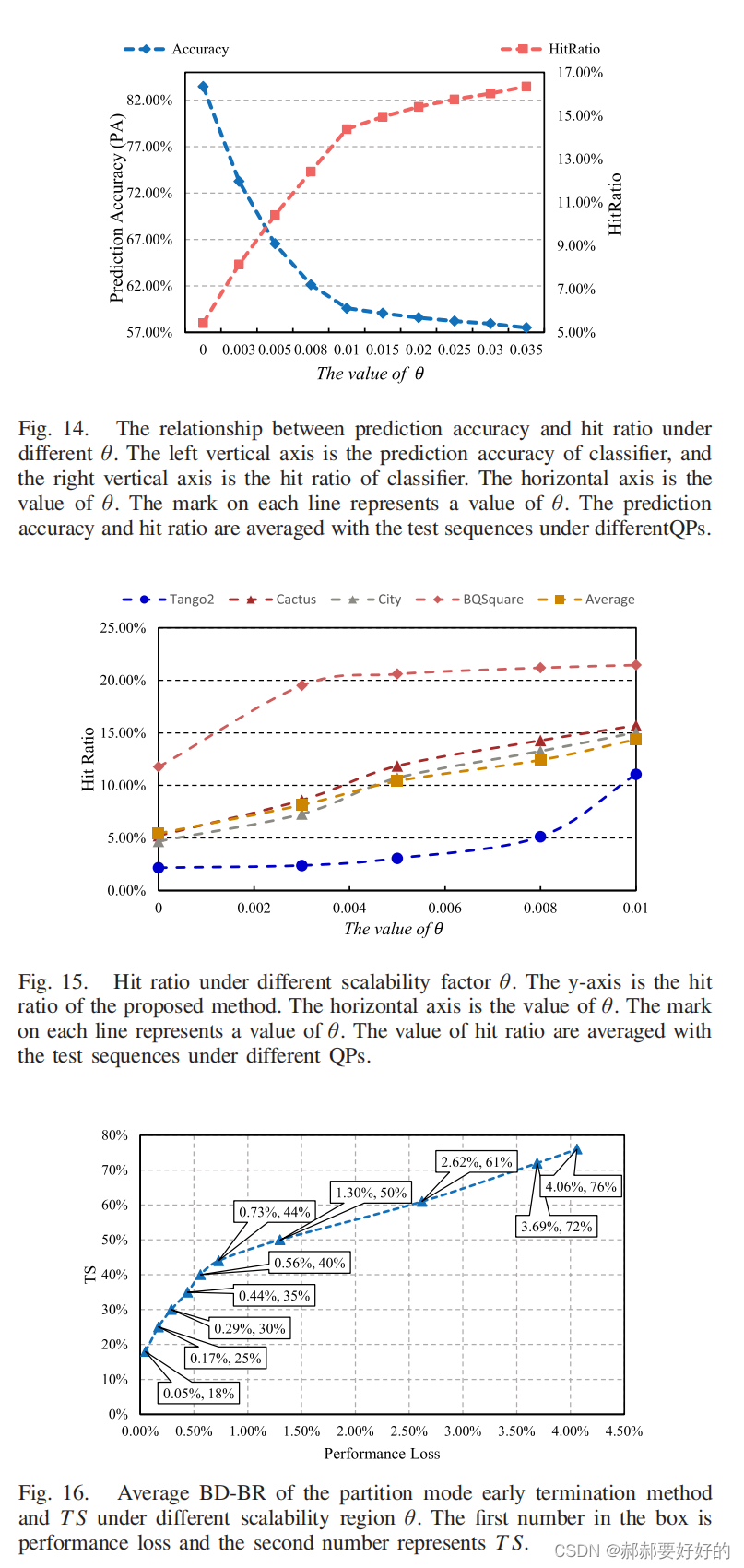
这里没什么好说的,就是给出了在不同θ下,预测精度,命中率,节省时间,和BD-rate的表现。
最后,作者给出了和其他工作的对比:
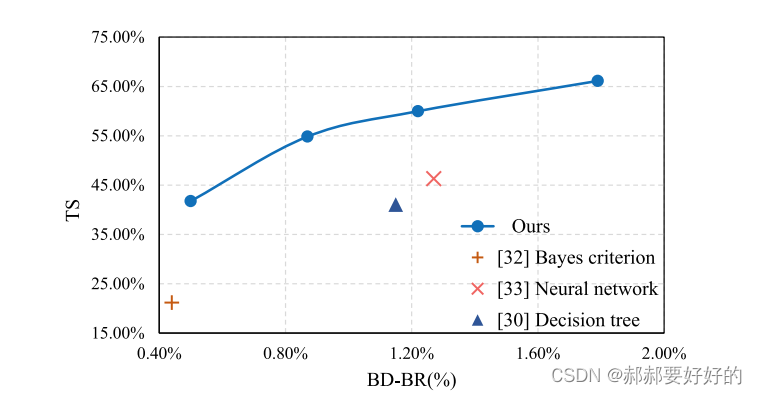
该工作的优势确实非常明显。以下面的线图进行说明:在任意一个BD-rate处画一条竖线,得到的加速效果都会比相应的对比工作要好。
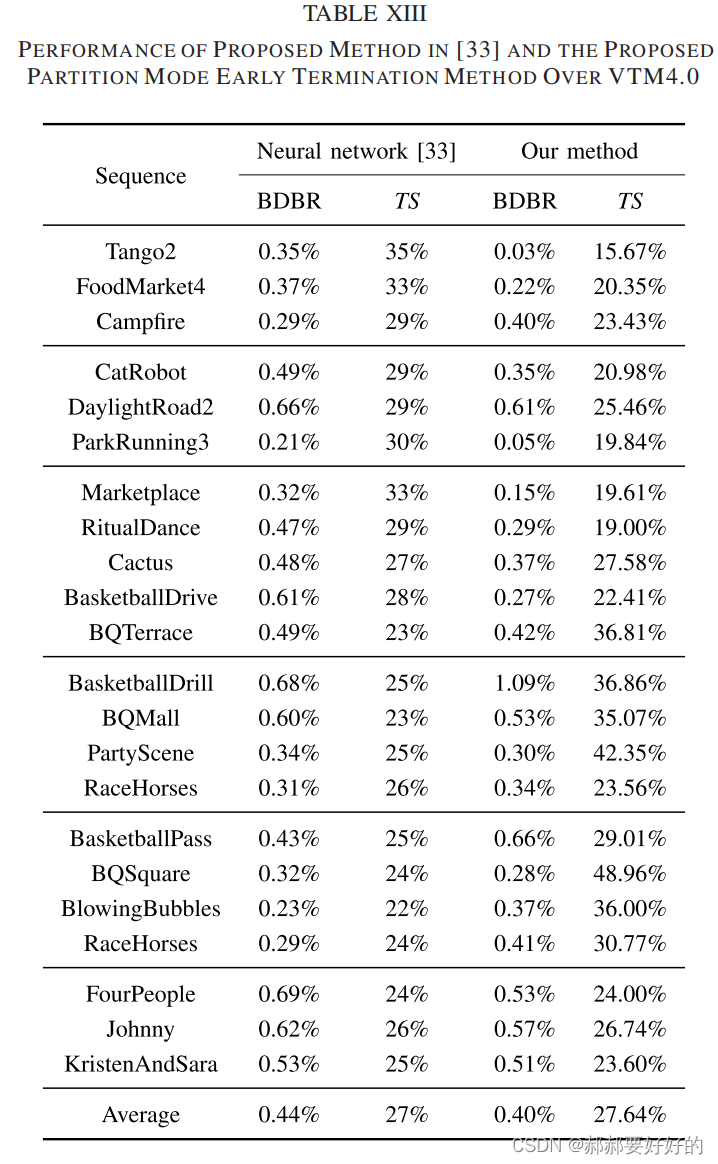
作者也将他们的工作扩展到了VVC上,在相似的加速效果下,BD_rate损失会更小。

总结:目前坐在AVS3上的工作相对较少,毕竟是国标。作者这篇论文的发表也说明了,只要工作做得好,做在什么标准上并不是问题(甚至还可以作为卖点)。这篇文章主要贡献在笔者看来,是做了大量的统计实验,利用统计特征来倒逼算法的产生。能够想到统计什么,在哪里统计,以及这些基于这些统计特征所设计的算法最终能够提供比较好的性能,这些都是非常重要的探索。作者虽然在paper中只展示了这些工作,但相信背后的探索过程一定是花了更多心血。值得大家学习。

















 5008
5008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









