









一、HDFS的读写过程
1. 写流程
<1>HDFS获取客户端;
<2>向NameNode请求上传文件;
<3>NameNode检查目录树是否可以创建文件;
检查权限
检查目录结构,目录是否存在
<4>NameNode 响应可以上传文件;
<5>HDFS客户端 请求上传第一个Block(0-128M),请求返回DataNode;
<6>NameNode返回三个DataNode节点,表示采用这三个节点存储数据;
<7> HDFS客户端请求建立Block传输通道,进行写数据;
<8>DataNode应答成功;
<9>传输,最小单位Packet,64K

2. 网络拓扑-节点距离计算
<1>在HDFS写入数据的时候,NameNode会选择距离待上传数据最近距离的DataNode接受数据
<2>节点距离:两个节点到达最近的共同祖先的距离总和

3.机架感知
副本存储节点选择
<1>第一个副本在Client所在节点上,如果客户端在集群外,随机选一个
<2>第二个副本在另一个机架的随机一个节点
<3>第三个副本在第二个副本所在机架的随机节点

4. 读数据
<1> HDFS获取客户端;
<2> HDFS客户端 请求下载文件;
<3> NameNode 检查数据;
<4> NameNode 返回目标文件的元数据;
<5> HDFS客户端 创建读取数据流;
<6> HDFS客户端 读取数据;
<7>DataNode 返回数据

二、NameNode和SecondaryNameNode
1. 概念
<1>Fsimage文件
HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息。
<2>Edits文件
存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中
<3>seen_txid文件
保存的是一个数字,就是最后一个edits的数字
<4>nameNode启动过程
每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的,同步的,可以看成NameNode启动的时候就将Fsimage和Edits文件进行了合并。
2. NN和2NN工作机制
第一阶段:NameNode启动
<1>第一次启动NameNode格式化后,创建Fsimage和Edits文件,如果不是第一次启动,直接加载Fsimage和Edits文件到内存。
<2>客户端对元数据进行增删改的操作
<3>NameNode记录操作日志,更新滚动日志
<4>NameNode在内存中对元数据进行增删改。
第二阶段:SecondaryNameNode工作
<1>SecondaryNameNode 询问NameNode 是否需要CheckPoint,直接带回NameNode是否检查结果
<2> SecondaryNameNode请求执行CheckPoint
<3> NameNode滚动正在写的Edits日志
<4>将滚动前的Fsimage和Edits文件拷贝到SecondaryNameNode
<5> SecondaryNameNode 加载Fsimage和Edits文件到内存,并合并
<6>生成新的镜像文件fsimage.chkpoint
<7>拷贝fsimage.chkpoint到NameNode
<8>NameNOde将fsimage.chkpoint重命名为fsimage

3.Fsimage 和Edits查看
<1>oiv
查看Fsimage文件
Hadoop oiv -p 文件类型 -i 镜像文件 -o 转换之后文件输出的路径
<2> oev
查看Edits文件
Hadoop oev -p 文件类型 -i 编辑日志文件 -o 转换之后文件输出的路径
4. CheckPoint时间配置
hdfs-default.xml文件下
<1>通常情况下 SecondaryNameNode每隔一小时执行一次

<2>一分钟检查一次操作数,当操作次数达到一百万时,SecondaryNameNode执行一次


三、DataNode工作机制(了解)
1.DateNode简介
一个数据块在DataNode上以文件的形式存储在磁盘上,包括两个文件,一个数据本身,一个是元数据包括数据开的长度,块数据的校验和以及时间戳
DataNode启动后向NameNode注册,通过后,周期性的向NameNode上报所有的块信息
2. 工作机制
<1>DataNode启动后向NameNode注册
<2>NameNode返回注册成功
<3>DataNode以后周期(6小时)上报所有块信息
<4>心跳每三秒一次,心跳返回结果带有NameNode给该DateNode的命令
<5>超过10分钟+20秒没有收到DataNode的心跳,则认为该DataNode节点不可用

3. 时间配置
hdfs-default.xml文件下
<1> DataNode 向NameNode汇报当前解读信息的时间间隔,默认6小时

<2> DataNode扫描自己节点块信息列表的时间,默认6小时

4. 数据完整性
<1>DataNode节点保证数据完整性的方法
- 当DateNode读取Block的时候,它会计算CheckSum
- 如果计算后的CheckSum,与Block创建时值不一样,说明Blick已经损坏
- Client读取其他DataNode上的Block
- 常见的校验算法crc(32)、md5、shal(160)
- DataNode在其文件创建后周期验证CHeckSum
5. 掉线实现参数设置
<1>两个配置参数
hdfs-default.xml文件下
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
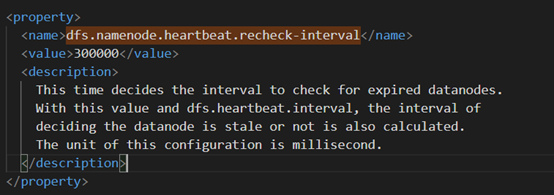

<2>解释图
















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









