






HBase基础
一、HBase的安装和配置
1、解压安装包到software文件夹下
tar -zxvf hbase-1.2.0-cdh5.14.2.tar.gz
2、修改文件名,配置文件hbase-env.sh和hbase-site.xml和 vi /etc/profile
[root@hadoop1 software]# mv hbase-1.2.0-cdh5.14.2/ hbase
[root@hadoop1 software]# cd hbase
[root@hadoop1 hbase]# cd conf
[root@hadoop1 conf]# vi hbase-env.sh
(1) vi hbase-env.sh
做如下配置

(2) vi hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
(3) vi /etc/profile
export HBASE_HOME=/opt/hbase
export PATH=.:$HBASE_HOME/bin
保存后:source使之生效
3、启动
start-all.sh
hbase-daemon.sh start master
hbase shell
4、验证
(1)jps
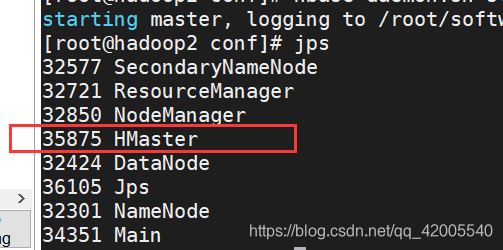
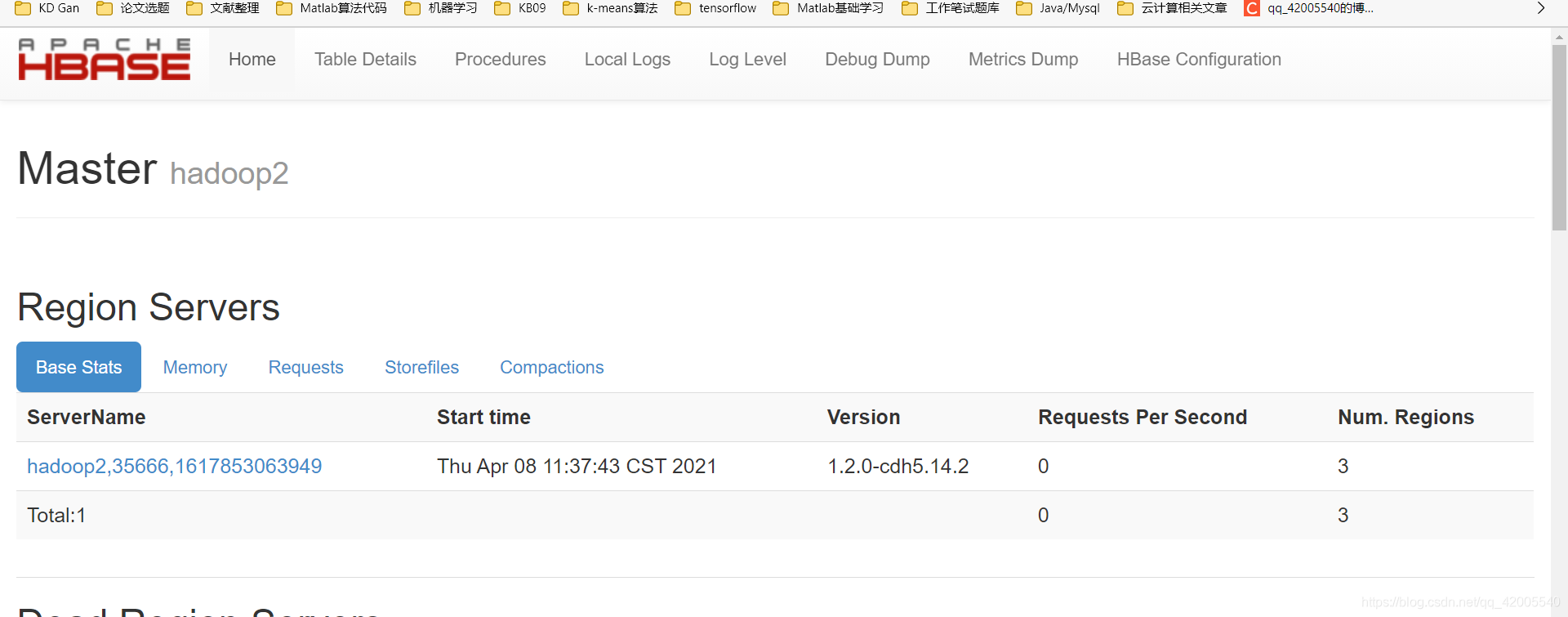
(2)网页验证
http://192.168.21.2:60010/
二、HBase概述
2.1 概述
HBase是一个领先的NoSQL数据库
是一个面向列存储的数据库
是一个分布式hash map
使用HDFS作为存储并利用其可靠性
HBase特点
数据访问速度快,响应时间约2-20毫秒
支持随机读写,每个节点20k~100k+ ops/s
可扩展性,可扩展到20,000+节点
为什么采用HBase?
HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。
HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。就点有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。
简单来说,你在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。你只需要 告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功能。
2.2 NoSql和关系型数据库的对比
| 对比 | NoSql | 关系型数据库 |
|---|---|---|
| 常用数据库 | HBase MongoDB Redis | Oracle DB2 MySql |
| 存储格式 | 文档 键值对 图结构 | 表格式 行和列 |
| 存储规范 | 鼓励冗余 | 规范性 避免重复 |
| 存储扩展 | 横向扩展 分布式 | 纵向扩展 |
| 查询方式 | 结构化查询 | 非结构化查询 |
| 事务 | 不支持事务一致性 | 支持事务 |
| 性能 | 读写性能高 | 读写性能差 |
| 成本 | 简单易部署,开源,成本低 | 成本高 |
2.3 NoSql的特点
最终一致性
应用程序增加了维护一致性和处理事务等职责冗余数据存储
NoSQL !=大数据
NoSQL产品是为了帮助解决大数据存储问题大数据不仅仅包含数据存储的问题
三、HBase逻辑结构
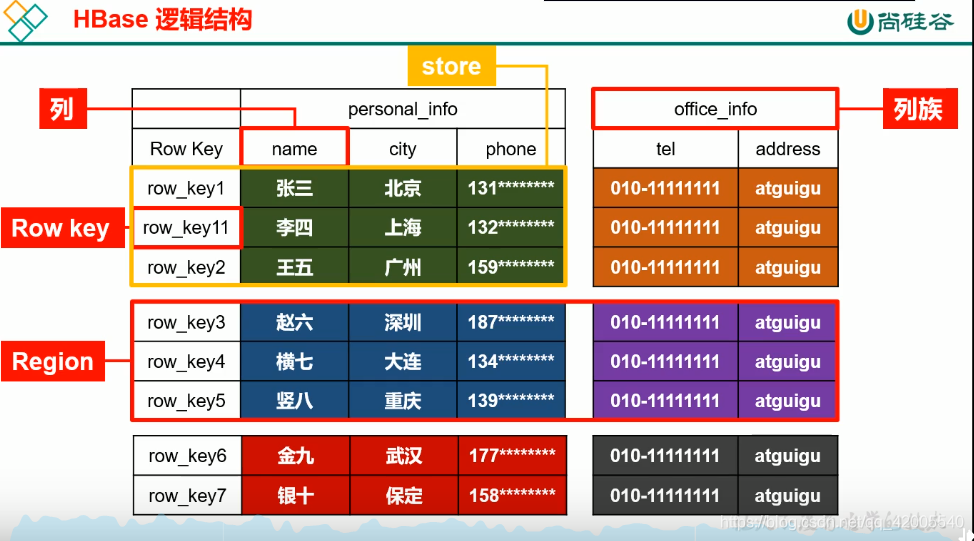
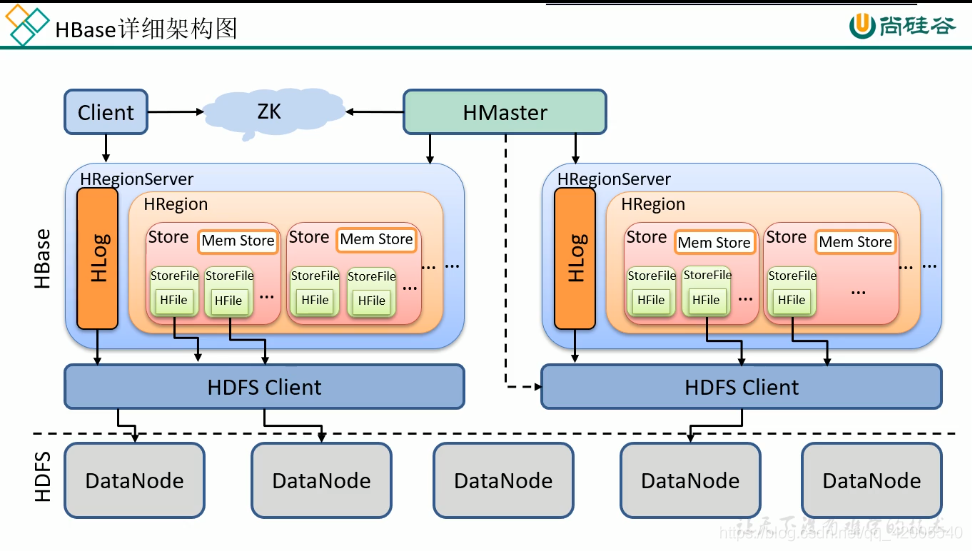
四、HBase详细架构
01 架构基础在第一部分中,我们先来了解一下HBase架构中的主要组件,包括Master、Region Server、Zookeeper、Client、HDFS、StoreFile。阅读过程中如果遇到不懂的名词可以先略过,我在本篇的第二部分中有详细介绍。
基础架构图
1.Master
Master是集群的主节点,本质上是一个进程。主要作用有:
1)负责管理元数据,如执行DDL操作、定期更新hbase:meta表
2)分配与移动region以保证集群的负载均衡
3)管理RegionServer,出现问题时进行故障转移 在分布式集群中,Master通常运行在NameNode上。
2.Region Server
Region Server是Region的管理者,本质上是一个进程。
主要作用是:
1)负责数据的增删改查,即DML操作
2)负责region的拆分与合并
3)将MemStore中数据刷写到StoreFiles
4)检查RegionServer的HLog文件 在分布式集群中,RegionServer都运行在DataNode上。
3.Client Client可不经过Master直接与Region Server通信,发出读或写请求,所以Master挂掉的情况下,集群仍然可以运行一段时间。
4.ZooKeeper HBase集群要依赖ZooKeeper才能运行。
主要作用是:
1)Master高可用,协助选举Master
2)监听RegionServer状态(心跳),向Master汇报RegionServer上下线信息
3)存放与维护集群配置信息,如hbase:meta表的地址。
5.HDFSHBase的数据最终要存储在HDFS上。
6.StoreFile保存实际数据的物理文件,StoreFile文件存储在 HDFS 上,格式是HFile。每个Store会产生 一个或多个StoreFile,数据在 StoreFile 中是有序的。 PS: NameSpace、Table、Region、Store、StoreFile之间的关系是什么? HBase表在HDFS存储路径为: / hbase / data / / / / / 可以认为它们依次构成了逻辑上的包含关系,StoreFile是最底层的物理存储文件。
02 架构进阶
第一部分中,我们对主要组件进行了介绍,接下来将深入细节,完善整个架构体系。
详细架构图
1.hbase:metahbase:meta(以前叫.META.)是之前说过的命名空间 hbase中的一张表。记录了全部表的所有region相关信息,如region位于哪个Region Server上。 重点:hbase:meta表的位置信息存储在Zookeeper中!!! PS:0.98版本前有一个 -ROOT-表,用来存储 hbase:meta表的信息,目前已经被弃用。有些博客还在介绍这个文件,直接忽略就行。
2.Meta Cache客户端元数据缓存。记录了 table的region信息和 habase:meta表位置信息,方便以后查询。
3.Block Cache读缓存。作用是缓存从HDFS读取的数据,以便下次查询使用。
4.WAL WAL(也称HLog)叫做预写入日志,记录了HBase中所有的数据变更,并以文件方式存储在HDFS。变更记录是以追加的形式添加到文件中,所以效率很高。 如果MemStore中的数据没有flush到磁盘,而Region Server出现了问题,就可以通过WAL恢复数据到磁盘。
5.MemStore往Store中写数据时,数据会先存储在内存中的MemStore。数据排好序后,等到达flush(刷写)时机时,再 flush到 StoreFile。 MemStore的数据写入磁盘的过程 叫做flush,MemStore每次 flush都会形成一个新的 StoreFile。 PS:刷写最小的单位是region,只要发生flush,整个region都会flush。
6.HFile HFile是HBase在HDFS中存储数据时使用的文件格式。它包含一个多层索引,允许HBase在不读取整个文件的情况下寻找数据。

五、HBase Shell的基本操作
5.1 创建表 create
语法:
create '表名称',{NAME => '列名‘},{NAME => '列名‘} ...

5.2 查看所有表:list,describe
–列出表的详细信息
desc 'student'
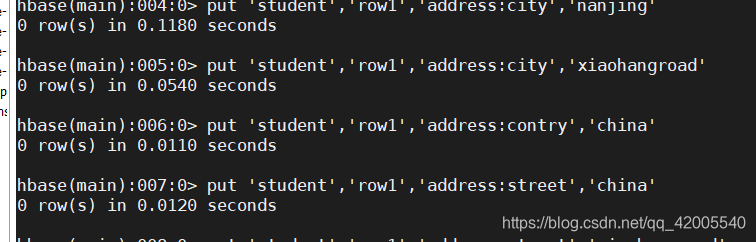
5.3 添加数据:put
语法:
put '表名' ,'行键' , '列簇名:列名’,'值'
5.4 扫描表:scan
scan ‘表名称’
hbase(main):103:0> scan 'customer'
ROW COLUMN+CELL
1001 column=addr:address, timestamp=1600937534433, value=ahha
2 column=addr:address, timestamp=1600927647563, value=baohua
jsmith column=addr:city, timestamp=1600925557395, value=montreal
3 row(s) in 0.0110 seconds
hbase(main):007:0> scan 'customer',{LIMIT=>1}
ROW COLUMN+CELL
2 column=addr:address, timestamp=1600927553710, value=baohua
1 row(s) in 0.0140 seconds
hbase(main):008:0> scan 'customer',{COLUMNS=>'addr:city'}
ROW COLUMN+CELL
jsmith column=addr:city, timestamp=1600925557395, value=montreal
1 row(s) in 0.0090 seconds
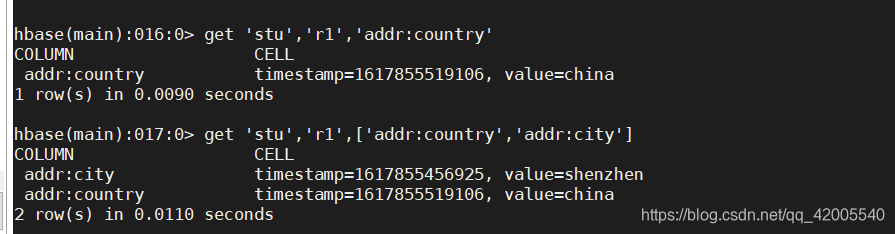
5.5 获取数据:get
查看表内容: get '表名', 'rowkey'
get '表名', 'rowkey','列簇名'
get '表名', 'rowkey','列簇名:列'
get '表名', 'rowkey', [ '列簇名:列,'列簇名:列'...]
5.6 删除数据:delete
delete ‘表名称’,‘行键’,‘列簇’
deleteall ‘表名称’,‘行键’

5.7 修改表:alter
删除指定的列族
hbase(main):002:0> alter 'User', 'delete' => 'info'
增加指定的列族
alter 'stu',NAME=>'address'
5.8 删除表:drop
要先将表置为 disable 状态才能删除表
--使用disable将表置为不可用状态
disable 'customer'
--使用enable将表置为可用状态
enable 'customer'
disable 'customer'
--删除
drop 'customer'














 3430
3430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









