









Kafka 作为老牌消息中间件, 高吞吐是它的拿手好戏. Spring 的生态中也有官方提供的 spring-kafka.jar. 本文主要学习 Spring 官方提供的 spring-kafka.jar 是怎么实现的.
环境
下面将本文用到的一些环境版本贴出来, Spring Kafka 在 1.X 版本和 2.X 源码上区别还是挺大的. 本文拉取的是当时的最新版.
- linux kafka server: kafka_2.13-2.7.0(注: 2.13 是 scala version, 2.7.0 才是 kafka version)
- spring-kafka: 2.7.0
- spring: 5.3.6
网上较多的对 Spring Kafka 1.X 版本的解读, 本文选用的是 2.X 请甄别后阅读
SpringKafka的依赖
下图不难看出, spring-kafka 的实现实际上是对 kafka-clients 这个包的又一次封装.
kafka-clients 是由 Apache 支持的开源项目
核心结构
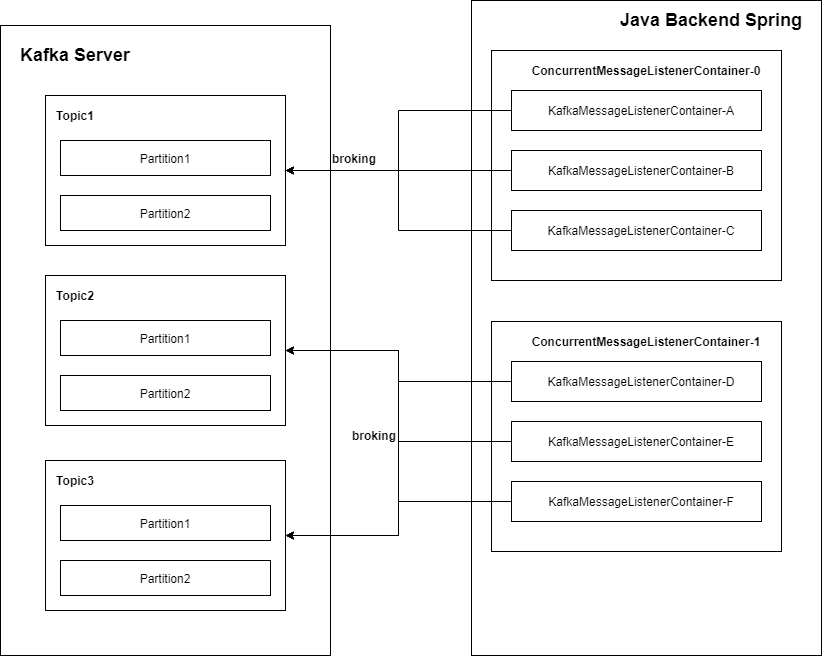
先来看一下 spring-kafka 核心图.
我们在 Spring 中注册一个 Listener, 框架就会为我们自动生成一个对应的 ConcurrentMessageListenerContainer 容器来管理.
再根据你配置的并发度来创建多个 KafkaMessageListenerContainer 容器. 每个 KafkaMessageListenerContainer 相当于一个线程, 这个线程会不断向 server 端发起 poll 请求来实现监听
核心方法调用关系
先看一下核心方法调用关系图. 笔者简化了方法栈中一些核心方法的执行过程.
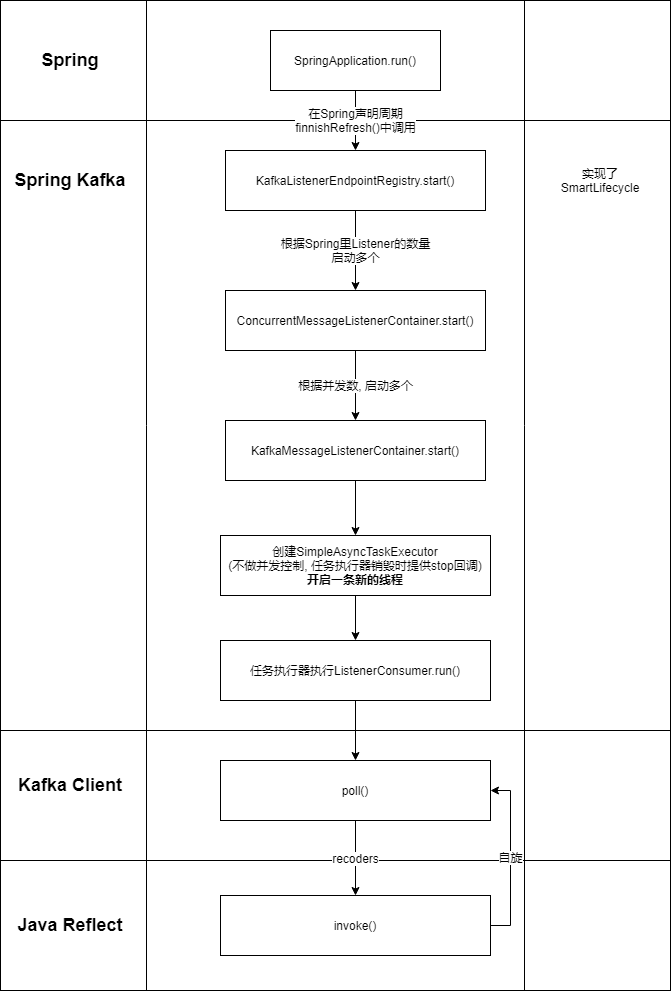
实际的执行过程应该是:
- Spring 启动
- Spring 生命周期为 finishRefresh() 时, 调用 KafkaListenerEndpointRegistry 中复写的钩子函数 start()
- 根据 Listener 创建对应数量的 ConcurrentMessageListenerContainer
- 根据并发配置 concurrency 创建对应数量的 KafkaMessageListenerContainer
- 在每个 KafkaMessageListenerContainer 中创建一个 SimpleAsyncTaskExecutor. 值得注意的是 SimpleAsyncTaskExecutor 的作用是创建一条新的线程, 并在线程停止时执行钩子 stop()
- 创建一个 ListenerConsumer 注册到 SimpleAsyncTaskExecutor 中
- ListenerConsumer 的 run() 方法被调用
- run 方法中开启自旋
- 不断调用 kafka-client 提供的 poll API 拉取新的消息
- 收到新的消息就执行, 执行完了就继续自旋
- 收不新消息, 重启下一轮自旋
源码解析
Spring
观察 Spring 线程方法栈, 我们可以知道
- Spring Kafka 其实是在 Spring 上下文的 finishRefresh() 这个生命周期中被唤醒的
- 最后调用调用 bean.start() 方法正式启动

DefaultLifecycleProcessor
@Override
public void onRefresh() {
// 入口
startBeans(true);
this.running = true;
}
private void doStart(Map<String, ? extends Lifecycle> lifecycleBeans, String beanName, boolean autoStartupOnly) {
Lifecycle bean = lifecycleBeans.remove(beanName);
if (bean != null && bean != this) {
String[] dependenciesForBean = getBeanFactory().getDependenciesForBean(beanName);
for (String dependency : dependenciesForBean) {
doStart(lifecycleBeans, dependency, autoStartupOnly);
}
if (!bean.isRunning() &&
(!autoStartupOnly || !(bean instanceof SmartLifecycle) || ((SmartLifecycle) bean).isAutoStartup())) {
if (logger.isTraceEnabled()) {
logger.trace("Starting bean '" + beanName + "' of type [" + bean.getClass().getName() + "]");
}
try {
// =================================
// 在这里被启动真正启动
// =================================
bean.start();
}
catch (Throwable ex) {
throw new ApplicationContextException("Failed to start bean '" + beanName + "'", ex);
}
if (logger.isDebugEnabled()) {
logger.debug("Successfully started bean '" + beanName + "'");
}
}
}
}
Spring Kafka 启动
下文开始都是 Spring Kafka 启动运行时的相关源码
KafkaListenerEndpointRegistry
这个入口类主要用来管理侦听器容器的生命周期.
对于本文针对学习的启动时的入口则是 startIfNecessary()
public class KafkaListenerEndpointRegistry implements ListenerContainerRegistry, DisposableBean, SmartLifecycle,
ApplicationContextAware, ApplicationListener<ContextRefreshedEvent> {
...ignore any codes...
/**
* 这个方法让容器校验是否在正确的时机(refreshed)或者是自动启动的情况
* 然后再去启动 spring-kafka
*/
private void startIfNecessary(MessageListenerContainer listenerContainer) {
if (this.contextRefreshed || listenerContainer.isAutoStartup()) {
listenerContainer.start();
}
}
...ignore any codes...
}
ConcurrentMessageListenerContainer
这是个容器, 用于创建至少一个 KafkaMessageListenerContainer 容器.
@Override
protected void doStart() {
if (!isRunning()) {
checkTopics();
ContainerProperties containerProperties = getContainerProperties();
TopicPartitionOffset[] topicPartitions = containerProperties.getTopicPartitions();
if (topicPartitions != null && this.concurrency > topicPartitions.length) {
this.logger.warn(() -> "When specific partitions are provided, the concurrency must be less than or "
+ "equal to the number of partitions; reduced from " + this.concurrency + " to "
+ topicPartitions.length);
this.concurrency = topicPartitions.length;
}
setRunning(true);
// 根据并发参数 concurrency, 来确定最终会创建多少个 KafkaMessageListenerContainer
// concurrency 缺省为 1
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer<K, V> container =
constructContainer(containerProperties, topicPartitions, i);
configureChildContainer(i, container);
if (isPaused()) {
container.pause();
}
container.start();
this.containers.add(container);
}
}
}
KafkaMessageListenerContainer
这个类主要作用如下:
- 通过配置文件生成 consumerExecutor, 用户如果没有配置, 则使用 SimpleAsyncTaskExecutor(后文会提到类似于线程池) 来创建
- 然后根据用户配置的 Listener 参数生成 ListenerConsumer(实现了Runnable接口)
- 最后让 consumerExecutor 去执行 ListenerConsumer
对 SimpleAsyncTaskExecutor 感兴趣的同学可以看这里: https://blog.csdn.net/weixin_30430169/article/details/99490928
@Override
protected void doStart() {
if (isRunning()) {
return;
}
if (this.clientIdSuffix == null) { // stand-alone container
checkTopics();
}
ContainerProperties containerProperties = getContainerProperties();
checkAckMode(containerProperties);
Object messageListener = containerProperties.getMessageListener();
// 试图从配置文件中获取 consumerExecutor
AsyncListenableTaskExecutor consumerExecutor = containerProperties.getConsumerTaskExecutor();
if (consumerExecutor == null) {
// 如果用户没有自定义配置, 则提供 SimpleAsyncTaskExecutor 为缺省实现
consumerExecutor = new SimpleAsyncTaskExecutor(
(getBeanName() == null ? "" : getBeanName()) + "-C-");
containerProperties.setConsumerTaskExecutor(consumerExecutor);
}
GenericMessageListener<?> listener = (GenericMessageListener<?>) messageListener;
ListenerType listenerType = determineListenerType(listener);
// 生成 listenerConsumer 对象
this.listenerConsumer = new ListenerConsumer(listener, listenerType);
setRunning(true);
this.startLatch = new CountDownLatch(1);
// 让 consumerExecutor 去执行 ListenerConsumer
this.listenerConsumerFuture = consumerExecutor
.submitListenable(this.listenerConsumer);
try {
if (!this.startLatch.await(containerProperties.getConsumerStartTimeout().toMillis(), TimeUnit.MILLISECONDS)) {
this.logger.error("Consumer thread failed to start - does the configured task executor "
+ "have enough threads to support all containers and concurrency?");
publishConsumerFailedToStart();
}
}
catch (@SuppressWarnings(UNUSED) InterruptedException e) {
Thread.currentThread().interrupt();
}
}
SimpleAsyncTaskExecutor
简单介绍一下 SimpleAsyncTaskExecutor, 虽然这个不是 spring-kafka 提供的, 但是在这里引用到了. 为了方便理解, 就提一下.
这个类主要是创建一个新的线程, 并在这个线程中执行 其他线程 submit(task) 到 SimpleAsyncTaskExecutor 中的 task 方法. 这些 task 需要实现 Runnable (Callable) 接口, SimpleAsyncTaskExecutor 会去消费他们.
这个类另一个作用呢, 其实是在关闭线程的时候, 提供一个钩子回去, 方便上文 KafkaListenerEndpointRegistry 进行管理
// 跟线程池一样都实现了 Executor 接口
public void execute(Runnable task, long startTimeout) {
Assert.notNull(task, "Runnable must not be null");
Runnable taskToUse = this.taskDecorator != null ? this.taskDecorator.decorate(task) : task;
if (this.isThrottleActive() && startTimeout > 0L) {
this.concurrencyThrottle.beforeAccess();
// 创建新线程
this.doExecute(new SimpleAsyncTaskExecutor.ConcurrencyThrottlingRunnable(taskToUse));
} else {
// 创建新线程
this.doExecute(taskToUse);
}
}
protected void doExecute(Runnable task) {
Thread thread = this.threadFactory != null ? this.threadFactory.newThread(task) : this.createThread(task);
thread.start();
}
ListenerConsumer.run
这个方法中总共做了三件事
- 初始化一些操作(对本文中电来说, 不太要紧)
- 开启自旋
- 在自旋中不断拉取 kafka 消息
- 拉取不到消息也有心跳机制保证连接
- 拉取到了则通过反射执行 Java 中对应业务处理的代码
public class KafkaMessageListenerContainer<K, V> // NOSONAR line count
extends AbstractMessageListenerContainer<K, V> {
...ignore any codes...
@Override // NOSONAR complexity
public void run() {
ListenerUtils.setLogOnlyMetadata(this.containerProperties.isOnlyLogRecordMetadata());
publishConsumerStartingEvent();
this.consumerThread = Thread.currentThread();
setupSeeks();
KafkaUtils.setConsumerGroupId(this.consumerGroupId);
this.count = 0;
this.last = System.currentTimeMillis();
initAssignedPartitions();
publishConsumerStartedEvent();
Throwable exitThrowable = null;
// 开启自旋, 即失败重试机制
while (isRunning()) {
try {
// 见名知意, 向 kafka-server 发起 poll 请求
// 收到后, 执行对应的方法
pollAndInvoke();
}
// ===============
// 这里为了方便阅读省略了一大段类似下文的异常处理
// ===============
catch (Exception e) {
handleConsumerException(e);
}
}
wrapUp(exitThrowable);
}
...ignore any codes...
}
ListenerConsumer.pollAndInvoke
这是调用 kafka-clients 并执行业务代码的入口方法
调用本类的 doPoll() 方法, 拉取 kafka 消息
调用 invokeIfHaveRecords() 对消息进行处理
protected void pollAndInvoke() {
if (!this.autoCommit && !this.isRecordAck) {
processCommits();
}
fixTxOffsetsIfNeeded();
idleBetweenPollIfNecessary();
if (this.seeks.size() > 0) {
processSeeks();
}
pauseConsumerIfNecessary();
pausePartitionsIfNecessary();
this.lastPoll = System.currentTimeMillis();
if (!isRunning()) {
return;
}
this.polling.set(true);
// 这个方法真正封装了 kafka-client 的 API
ConsumerRecords<K, V> records = doPoll();
if (!this.polling.compareAndSet(true, false) && records != null) {
/*
* There is a small race condition where wakeIfNecessary was called between
* exiting the poll and before we reset the boolean.
*/
if (records.count() > 0) {
this.logger.debug(() -> "Discarding polled records, container stopped: " + records.count());
}
return;
}
resumeConsumerIfNeccessary();
resumePartitionsIfNecessary();
debugRecords(records);
// 不管有没有值, 都会交给这个方法进行处理
// 有值则会反射调用 java handler method
// 没有值的话, 则直接返回
invokeIfHaveRecords(records);
// 该方法结束后进入下一次自旋
}
ListenerConsumer.doPoll
通过调用 this.consumer.poll(this.pollTimeout) 方法, 我们可以知道, this.consumer 其实是 kafka-client 提供的消费者实例
@Nullable
private ConsumerRecords<K, V> doPoll() {
ConsumerRecords<K, V> records;
if (this.isBatchListener && this.subBatchPerPartition) {
if (this.batchIterator == null) {
// 底层都是调用 kafka-client 提供的 poll api
this.lastBatch = this.consumer.poll(this.pollTimeout);
if (this.lastBatch.count() == 0) {
return this.lastBatch;
}
else {
this.batchIterator = this.lastBatch.partitions().iterator();
}
}
TopicPartition next = this.batchIterator.next();
List<ConsumerRecord<K, V>> subBatch = this.lastBatch.records(next);
records = new ConsumerRecords<>(Collections.singletonMap(next, subBatch));
if (!this.batchIterator.hasNext()) {
this.batchIterator = null;
}
}
else {
// 底层都是调用 kafka-client 提供的 poll api
records = this.consumer.poll(this.pollTimeout);
checkRebalanceCommits();
}
return records;
}
ListenerConsumer.invokeIfHaveRecords
看了堆栈树之后可以知道, invokeIfHaveRecords () 方法其实底层是调用了 Java 反射实现的. 那么这个方法就不具体展开了(一层一层剥离源码调用的逻辑), 因为太多次调用到了别处实现, 这里展示一下在 spring-kafka 源码层面最底层的调用
其实在 KafkaMessageListenerContainer 生成时, 就会在全局内存中存储一个对应的 RecordMessagingMessageListenerAdapter 当新消息来了之后, RecordMessagingMessageListenerAdapter 会自动适合的方法去执行(配合 @KafkaHandler 注解使用).
RecordMessagingMessageListenerAdapter 见名知意, 适配器模式, 寻找合适的 Handler 方法来适配这次返回的参数结构
public Object invoke(Message<?> message, Object... providedArgs) throws Exception { //NOSONAR
if (this.invokerHandlerMethod != null) {
// 这是执行的入口
return this.invokerHandlerMethod.invoke(message, providedArgs); // NOSONAR
}
else if (this.delegatingHandler.hasDefaultHandler()) {
// Needed to avoid returning raw Message which matches Object
Object[] args = new Object[providedArgs.length + 1];
args[0] = message.getPayload();
System.arraycopy(providedArgs, 0, args, 1, providedArgs.length);
return this.delegatingHandler.invoke(message, args);
}
else {
return this.delegatingHandler.invoke(message, providedArgs);
}
}















 4891
4891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









