







1、Redis_主从复制
前期准备
1.官网下载最新redis-7.0.2.tar.gz
2.创建目录mkdir opt 把安装包放在这个文件夹底下
3.解压tar -zxvf redis-7.0.2.tar.gz
4.复制redis-7.0.2文件夹里面的redis.conf
5.创建文件夹myredis并把redis.conf复制过来
6.修改vi redis.conf 后台启动设置daemonize no改成yes
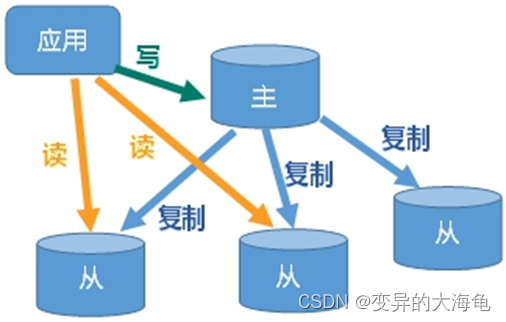
(1)主从复制是什么
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
(2)怎么玩:主从复制
1.我们创建三个配置文件:redis6379.conf、redis6380.conf、redis6381.conf
文件内容以redis6379.conf为例
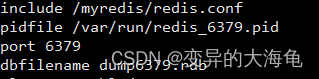
include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
其他文件配置一样,注意修改里面的端口一一对应上
:%s/6379/6380这个命令是全局替换。
2.启动三台redis服务器

3.查看系统进程,看看三台服务器是否启动

4.查看三台主机运行情况
info replication
打印主从复制的相关信息
下面可以知道全部都是主还没有配置

5.配从(库)不配主(库)
slaveof
在6380和6381上执行: slaveof 127.0.0.1 6379
配置完毕需要注意的事项:
在主机上写,在从机上可以读取数据
在从机上写数据报错
主机挂掉,重启就行,一切如初
从机重启需重设:slaveof 127.0.0.1 6379
(3)常用三招
1.一主二仆
2. 薪火相传
3. 反客为主(自动版哨兵模式(sentinel))
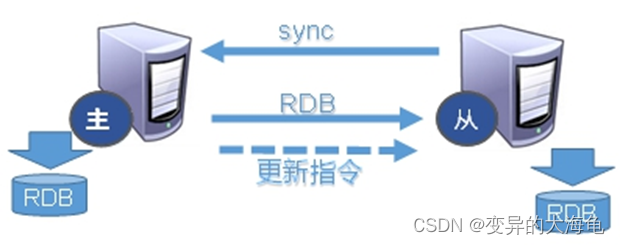
(4)复制原理
Slave启动成功连接到master后会发送一个sync命令
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
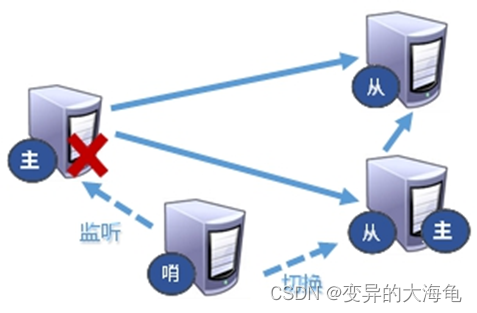
(5)哨兵模式(sentinel)
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
1.在自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错
sentinel monitor mymaster 127.0.0.1 6379 1
其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。
2.启动哨兵
执行redis-sentinel /myredis/sentinel.conf

3.当主机挂掉,从机选举中产生新的主机
对6379输入shutdown或者kill -9 进程模拟主机挂机。
(大概10秒左右可以看到哨兵窗口日志,切换了新的主机)
哪个从机会被选举为主机呢?根据优先级别:slave-priority 原主机重启后会变为从机。
2、redis_集群搭建
1.问题
容量不够,redis如何进行扩容?
并发写操作, redis如何分摊?
2.什么是集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
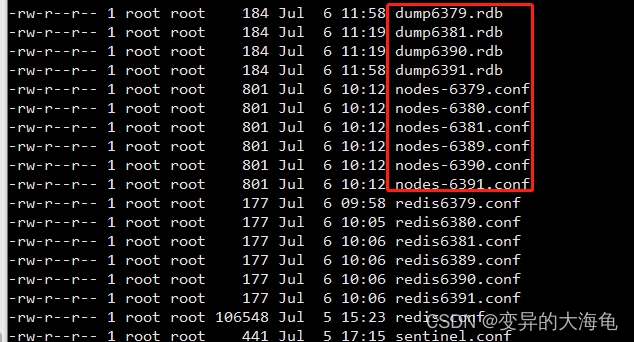
3.删除持久化数据
将rdb,aof文件都删除掉。
4.制作6个实例,6379,6380,6381,6389,6390,6391
5.redis cluster配置修改
在之前的基础上面新增下面三个配置用redis6379.conf为例
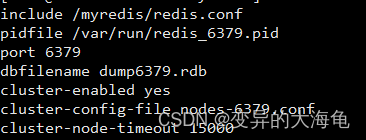
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进
6.其他的配置文件全部都需要更改
7.启动redis服务

8.将六个节点合成一个集群
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
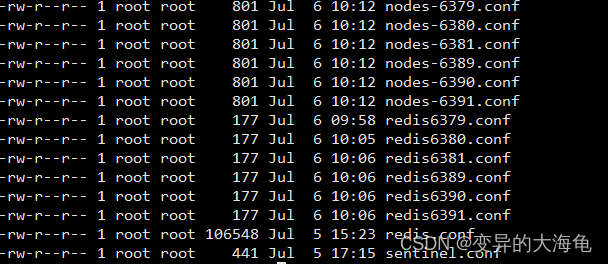
合体:
在cd /opt/redis-6.2.1/src:
执行命令:
redis-cli --cluster create --cluster-replicas 1 101.35.51.101:6379 101.35.51.101:6380 101.35.51.101:6381 101.35.51.101:6389 101.35.51.101:6390 101.35.51.101:6391

9.-c 采用集群策略连接,设置数据会自动切换到相应的写主机
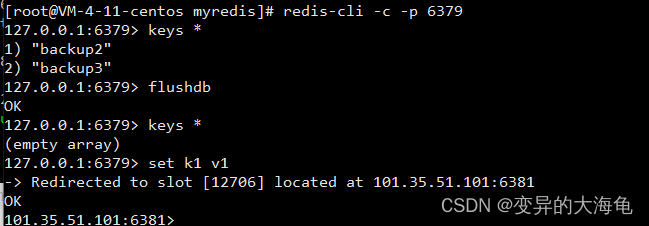
10.通过 cluster nodes 命令查看集群信息
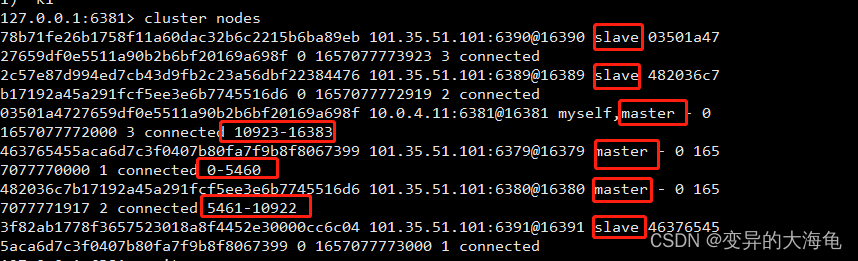
11.redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点。
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
12.什么是slots
[OK] All nodes agree about slots configuration.
Check for open slots…
Check slots coverage…
[OK] All 16384 slots covered.
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5460 号插槽。
节点 B 负责处理 5461 号至 10922 号插槽。
节点 C 负责处理 10923 号至 16383 号插槽。
13.故障恢复
如果主节点下线?从节点能否自动升为主节点?注意:15秒超时
主节点恢复后,主从关系会如何?主节点回来变成从机。
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
redis.conf中的参数 cluster-require-full-coverage
14.删除redis集群
ps -ef|grep redis 杀掉进程 kill -9 进程号
cd /myredis
删除 dump开头和nodes开头的文件
rm -rf dump*
然后可以重新部署跟上面的一样
15.集群的Jedis开发
public static void main(String[] args) throws IOException {
HostAndPort hostAndPort=new HostAndPort("101.35.51.101",6379);
JedisCluster jedisCluster=new JedisCluster(hostAndPort);
jedisCluster.set("b3","value3");
String b1 = jedisCluster.get("b3");
System.out.println("获取值"+b1);
jedisCluster.close();
}
16.Redis 集群提供了以下好处
实现扩容
分摊压力
无中心配置相对简单
17.Redis 集群的不足
多键操作是不被支持的
多键的Redis事务是不被支持的。lua脚本不被支持
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
3、Redis应用问题解决:
1. 缓存穿透
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
一个一定不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决方案:
(1) 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过五分钟
(2) 设置可访问的名单(白名单):
使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
(3) 采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
(4) 进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
2.缓存击穿
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
解决问题:
(1)预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
(2)实时调整:现场监控哪些数据热门,实时调整key的过期时长
(3)使用锁:
(1) 就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
(2) 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
(3) 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
(4) 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
3.缓存雪崩
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key正常访问缓存失效瞬间
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
解决方案:
(1) 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列:
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
4.分布式锁
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
- 基于缓存(Redis等)
- 基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点: - 性能:redis最高
- 可靠性:zookeeper最高,基于redis实现分布式锁。
第一种没有考虑过期时间

- 多个客户端同时获取锁(setnx)
- 获取成功,执行业务逻辑{从db获取数据,放入缓存},执行完成释放锁(del)
- 其他客户端等待重试
问题:setnx刚好获取到锁,业务逻辑出现异常,导致锁无法释放
解决:设置过期时间,自动释放锁。
第二种设置过期时间
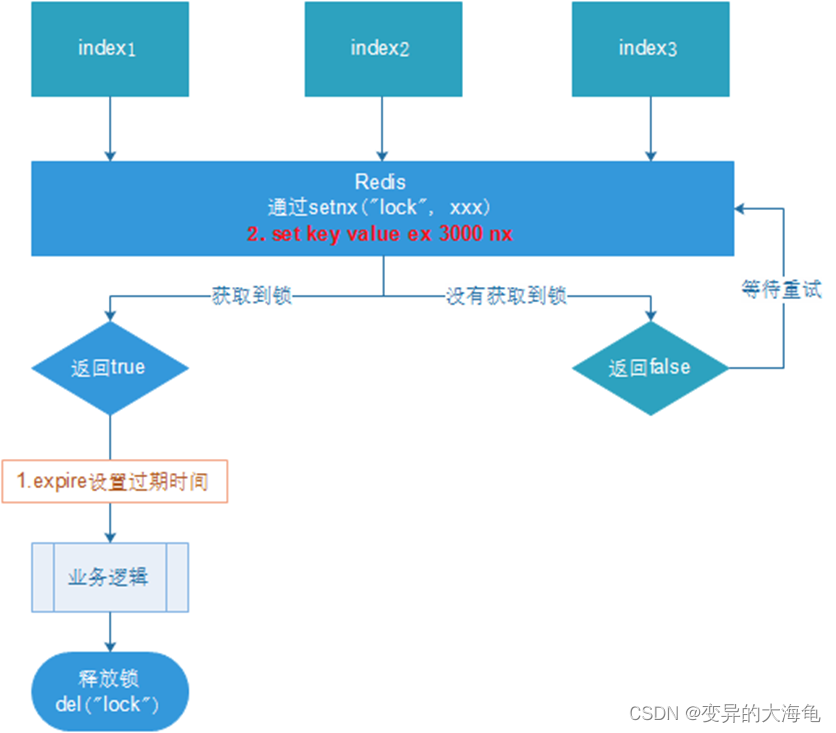
问题:可能会释放其他服务器的锁。
场景:如果业务逻辑的执行时间是7s。执行流程如下
- index1业务逻辑没执行完,3秒后锁被自动释放。
- index2获取到锁,执行业务逻辑,3秒后锁被自动释放。
- index3获取到锁,执行业务逻辑
- index1业务逻辑执行完成,开始调用del释放锁,这时释放的是index3的锁,导致index3的业务只执行1s就被别人释放。
最终等于没锁的情况。
解决:setnx获取锁时,设置一个指定的唯一值(例如:uuid);释放前获取这个值,判断是否自己的锁
第三种加UUID防误删

问题:删除操作缺乏原子性。
场景:
- index1执行删除时,查询到的lock值确实和uuid相等
- index1执行删除前,lock刚好过期时间已到,被redis自动释放在redis中没有了lock,没有了锁。
- index2获取了lock
index2线程获取到了cpu的资源,开始执行方法
uuid=v2
set(lock,uuid); - index1执行删除,此时会把index2的lock删除
index1 因为已经在方法中了,所以不需要重新上锁。index1有执行的权限。index1已经比较完成了,这个时候,开始执行删除的index2的锁!
第四种优化之LUA脚本保证删除的原子性
@GetMapping("testLockLua")
public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*使用lua脚本来锁*/
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
4、遇到的问题:
1.在合体的时候一直报Waiting for the cluster to join 后面百度了
是因为我的腾讯云没有开放redis集群端口
Redis服务在集群中还有一个叫集群总线端口,其端口为客户端连接端口加上10000,即 6379 + 10000 = 16379


2.集群的Jedis开发报No more cluster attempts left.
网上找了 很多都是说redis集群部署有问题,但是redis部署正常。
经过多番折腾,确认不是redis搭建部署问题,是本地jedis版本问题,原来是3.2.0版本 后调整为 2.8.1 问题解决。后面我在把版本弄回去发现不报错了,神奇,经过我的反复测试,还是没办法还原之前的报错
有小伙伴知道的请留言告知。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









