







在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D阵列格式加载数据帧,并具有多种功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -这个库用于绘制可视化。
- Sklearn -此模块包含多个库,这些库具有预实现的功能,以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error as mae
import warnings
warnings.filterwarnings('ignore')
现在,让我们将数据集加载到panda的数据框中,并打印它的前五行。
df = pd.read_csv('StoreDemand.csv')
display(df.head())
display(df.tail())
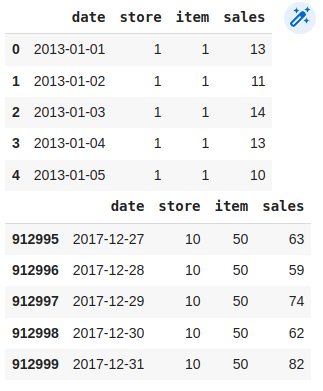
如我们所见,我们有10家商店和50种产品的5年数据,可以计算得,
(365 * 4 + 366) * 10 * 50 = 913000
现在让我们检查一下我们计算的数据大小是否正确。
df.shape
输出:
(913000, 4)
让我们检查数据集的每列包含哪种类型的数据。
df.info()
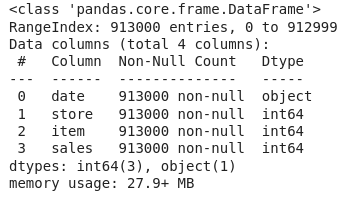
根据上面关于每列数据的信息,我们可以观察到没有空值。
df.describe()
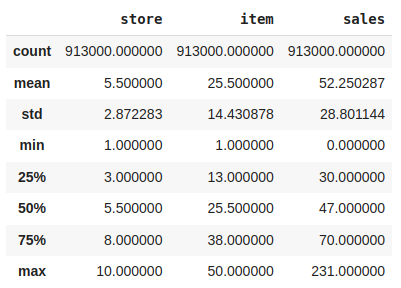
特征工程
有时候,同一个特征中提供了多个特征,或者我们必须从现有的特征中派生一些特征。我们还将尝试在数据集中包含一些额外的功能,以便我们可以从我们拥有的数据中获得一些有趣的见解。此外,如果导出的特征是有意义的,那么它们将成为显著提高模型准确性的决定性因素。
parts = df["date"].str.split("-", n = 3, expand = True)
df["year"]= parts[0].astype('int')
df["month"]= parts[1].astype('int')
df["day"]= parts[2].astype 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











