







你一定听说过一些关于医疗保险的广告,承诺在任何医疗紧急情况下提供经济帮助。一个谁购买这种类型的保险必须每月支付保费,这个保费金额根据各种因素变化很大。
在本文中,我们将尝试从一个数据集中提取一些见解,该数据集包含有关购买医疗保险的人的背景,这些人收取的保费金额的详细信息,以及使用Python中的机器学习。
导入库和数据集
Python库使我们能够非常容易地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D阵列格式加载数据帧,并具有多种功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -这个库用于绘制可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.metrics import mean_absolute_percentage_error as mape
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor, AdaBoostRegressor
import warnings
warnings.filterwarnings('ignore')
现在,让我们使用panda的数据框架来加载数据集,并查看它的前五行。
df = pd.read_csv('medical_insurance.csv')
df.head()
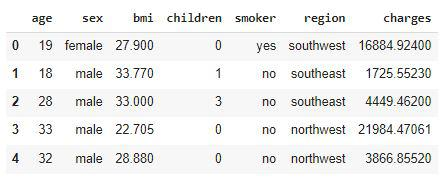
df.shape
"""
(1338, 7)
"""
该数据集包含1338个数据点,具有6个独立特征和1个目标特征。
df.info()
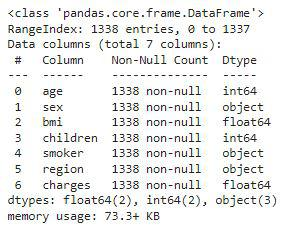
从上面我们可以看到,数据集包含2列浮点值,3列分类值,其余包含整数值。
df.describe()
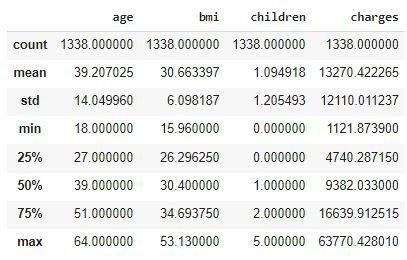
我们可以查看数据集中可用的连续数据的描述性统计度量。
探索性数据分析
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。在执行该数据集的EDA时,我们将尝试查看独立特征之间的关系,即一个特征如何影响另一个特征。
df.isnull().sum()
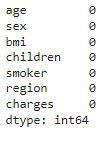
因此,在这里我们可以得出结论,在给定的数据集中没有空值。
features = ['sex', 'smoker', 'region']
plt.subplots(figsize=(20, 10))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











