







目录
2 指定表名 @TableName(value="数据库表名")
3 指定列名 @TableField(value = "数据库字段名")
2.8 in,notInin 后面值列表, 在列表中都是符合条件的。
2.11 orderByAsc,orderByDesc,orderBy
零.引言
1.必备的知识
mybatis
spring或springboot
maven
2.非必要掌握的知识
lambda表达式
3.开发环境
idea,mysql5.x,maven 3,spring boot 2.x
一.快速开始
1.idea配置maven
2.创建spring boot项目,并添加依赖

3.application.yml添加数据库配置

4.数据库创建测试表,项目创建实体类


@TableId 设置主键,type指定主键的类型 ,如IdType.AUTO 主键自动增长
5.mapper文件

mapper文件一定要继承mybatis plus中的 baseMapper
6.添加@mapperScan 扫描Mapper文件夹

7.测试

8.配置mybatis 日志
application.yml

二.Mapper 的 CRUD
CURD的操作是来自 BaseMapper 中的方法。BaseMapper 中共有 17 个方法,
BaseMapper 方法列表:

1.insert 操作

注:insert()返回值 int,数据插入成功的行数,成功的记录数。getId()获取主键值
2.update 操作

注意:null 的字段不更新

日志:

email 没有赋值,是 null ,所有没有出现在 set 语句中;
如果将age的类型从Integer 改为 int,age 有默认 0,被更新了。
3.delete 操作
删除有多个方法

3.1 deleteById:按主键删除

3.2 根据 Map 中条件删除

注:删除条件封装在 Map 中,key 是列名,value 是值,多个 key 之间 and 联接。
日志

3.3 批量删除

注:list 集合的创建可以使用 lambda 表达式,也可以使用 add()。例如: idlist.add(1); idlist.add(2);idlist.add(3)…
把要删除的 id 放入 List ,传给 deleteBatchIds()。 批量操作使用 in(…)

4.select 操作
4.1 根据 id 主键查询

注:没有查询结果,不会报错。但是对象是空值,需要做是否为空的判断
日志:

4.2 批量查询记录

注:根据 id 查询记录,把需要查询的多个 id 存入到 List,调用 selectBatchIds(), 传入 List,返回值也是 List。 查询条件是 from user where in id (1,2)
4.3 使用 Map 的条件查询

把要查询的条件字段 put 到 Map,key 是字段,value 是条件值。多个条件是 and 联接。调用 selectByMap(),传入 Map 作为参数,返回值是 List 集合。

三 ActiveRecord(AR)
1 ActiveRecord 简介
- 每一个数据库表对应创建一个类,类的每一个对象实例对应于数据库中 表的一行记录; 通常表的每个字段在类中都有相应的 Field;
- ActiveRecord 负责把自己持久化. 在 ActiveRecord 中封装了对数据库的访 问,通过对象自己实现 CRUD,实现优雅的数据库操作。
- ActiveRecord 也封装了部分业务逻辑。可以作为业务对象使用。
2 准备
2.1 创建数据库
sql:
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`mobile` varchar(50) DEFAULT NULL,
`manager` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.2 创建实体类

必须继承 Model,Model 定义了表的 CRUD 方法,Dept 属性名和列名是一样的。
2.3 mapper文件

不使用 mapper,也需要定义这个类,MP 通过 mapper 获取到表的结构;不定义时,MP 报错无法获取表的结构信息。
3 insert

4 update

创建实体对象,对要更新的属性赋值,null 的属性不更新,根据主键更新记录。 返回值是 boolean,true 更新成功。没有更新记录是 false。
日志:

5 delete

使用主键作为删除条件,deleteById()参数是主键值,sql 语句条件是 where id=1。 返回值始终是 true。通过源码查看:

删除返回值判断条件是 result >=0 ,只有 sql 语法是正确的,返回就是 true。和 删除记录的数量无关。
日志:

6 select
6.1 对象调用selectById()

对象提供主键值,调用 selectById()无参数,使用 id=2 作为查询条件,返回值是查询的结果对象;没有查询到对象,返回是 null;不提供主键 id 值,报错如下: com.baomidou.mybatisplus.core.exceptions.MybatisPlusException: selectById primaryKey is null.
6.2 selectById(主键)

创建对象,不设值 id 主键值, selectById 的参数是查询条件,和对象的属性值 无关。返回值是结果对象,id 不存在返回 null。
四.常用注解
1 主键注解 @TableId
IdType 枚举类,主键定义如下:
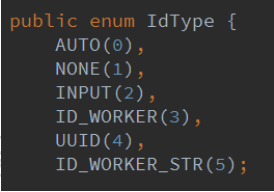
0.none 没有主键
1.auto 自动增长(mysql, sql server)
2.input 手工输入
3.id_worker: 实体类用 Long id , 表的列用 bigint ,int 类型大小不够
4.id_worker_str 实体类使用 String id, 表的列使用 varchar 50
5.uuid 实体类使用 String id, 列使用 varchar 50
id_worker: Twitter 雪花算法-分布式 ID
2 指定表名 @TableName(value="数据库表名")
定义实体类,默认的表名和实体类同名;如果不一致,在实体类定义上面使用 @TableName 说明表名称。
例如:@TableName(value=”数据库表名”)

生成的SQL日志中:

3 指定列名 @TableField(value = "数据库字段名")

日志:

4 驼峰命名
列名使用下划线,属性名是驼峰命名方式。MyBatis 默认支持这种规则


日志:
五.自定义sql
1.创建数据库和相关文件
1.1数据库

1.2 实体类

1.3 mapper

1.4 sql映射文件

1.5 配置xml文件位置

2 测试

日志:

六.查询构造器 Wrapper(重点)
1.概念
QueryWrapper(LambdaQueryWrapper) 和 UpdateWrapper(LambdaUpdateWrapper) 的父类用于生成 sql 的 where 条件, entity 属性也用于生成 sql 的 where 条 件. MP3.x开始支持lambda表达式,LambdaQueryWrapper,LambdaUpdateWrapper 支持 lambda 表达式的构造查询条件。
| 条件 | 说明 |
|---|---|
| allEq | 基于map的相等 |
| eq | 等于 = |
| ne | 不等于<> |
| gt | 大于> |
| ge | 大于等于 >= |
| lt | 小于< |
| le | 小于等于<= |
| between | between A and B |
| notBetween | not between A and B |
| like | like '%值%' |
| notLike | not like '%值%' |
| likeLeft | like '%值' |
| likeRight | like '值%' |
| isNull | 字段 is null |
| isNotNull | 字段 is not null |
| in | 字段 in (value1,value2,...) |
| notIn | 字段 NOT IN (value1, value2, ...) |
| inSql | 字段 IN ( sql 语句 ) 例: inSql("age", "1,2,3")--->age in (1,2,3,4,5,6) 例: inSql("id", "select id from table where id < 3")--->id in (select id from table where id < 3) |
| notInSql | 字段 NOT IN ( sql 语句 ) |
| groupBy | GROUP BY 字段 |
| orderByAsc | 升序 ORDER BY 字段, ... ASC |
| orderByDesc | 降序 ORDER BY 字段, ... DESC |
| orderBy | 自定义字段排序 orderBy(true, true, "id", "name")--->order by id ASC,name ASC |
| having | 条件分组 |
| or | OR 语句,拼接 + OR 字段=值 |
| and | AND 语句,拼接 + AND 字段=值 |
| apply | 拼接 sql |
| last | 在 sql 语句后拼接自定义条件 |
| exists | 拼接 EXISTS ( sql 语句 ) 例 : exists("select id from table where age = 1")--->exists (select id from table where age = 1) |
| notExists | 拼接 NOT EXISTS ( sql 语句 ) |
| nested | 正常嵌套 不带 AND 或者 OR |
| 方法 | 说明 |
| select | 设置查询字段 select 后面的内容 |
| 方法 | 说明 |
| set | 设置要更新的字段,MP 拼接 sql 语句 |
| setSql | 参数是 sql 语句,MP 不在处理语句 |
2 例子
2.1 初始数据(mapper,实体类已省略)
Student 表

2.2 allEq
以 Map 为参数条件
2.2.1 name 是张三,age 是 22

日志:where name=”张三” and age = 22

2.2.2 查询条件有 null

true 日志:
![]()
false 日志:
![]()
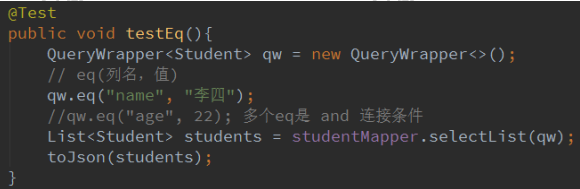
2.3 eq,ne,gt,ge,lt,le
等于 = ,name 等于李四
2.4 between,notBetween
between 在两个值范围之间
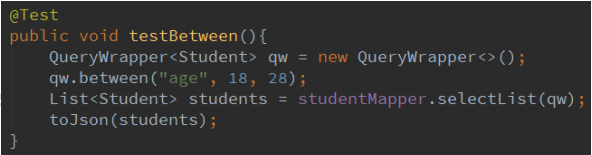
日志:

2.5 like,notLike
like 匹配值 “%值%”
notLike 不匹配 “%值%”
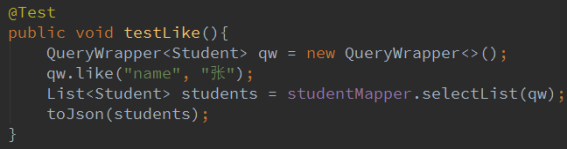
日志:

2.6 likeLeft,likeRight
likeLeft 匹配 like “%值” likeRight 匹配 like “值%”
2.7 isNull ,isNotNull
isNull 判断字段值为 null
isNotNull 字段值不为 null
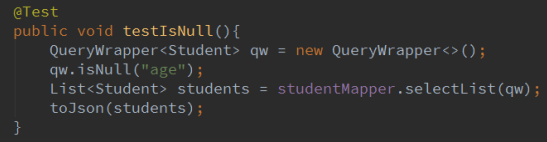
日志

2.8 in,notIn
in 后面值列表, 在列表中都是符合条件的。
notIn 不在列表中的
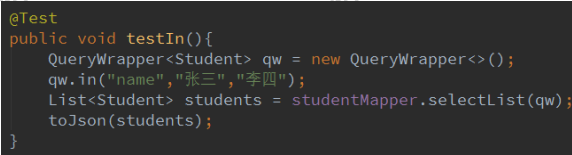
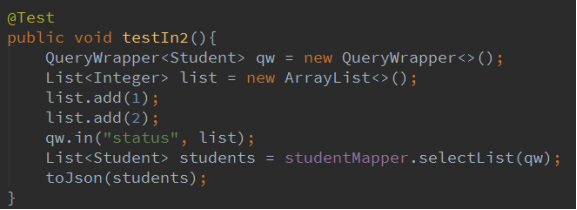
日志:

2.9 inSql,notInSql
inSql 常用来做子查询 类似 in()
notInSql 类似 notIn()
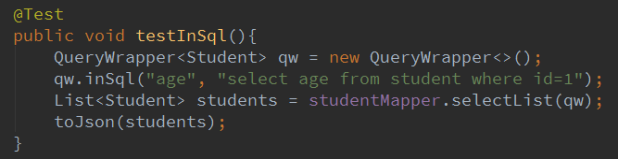
日志:

2.10 groupBy
groupBy 基于多个字段分组
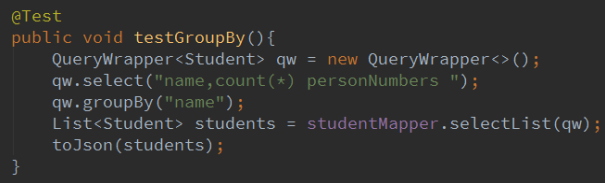
日志:

2.11 orderByAsc,orderByDesc,orderBy
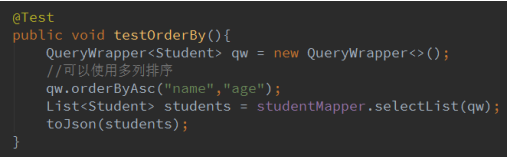
日志:
2.12 or,and
or 连接条件用 or,默认是 and and 连接条件用 and
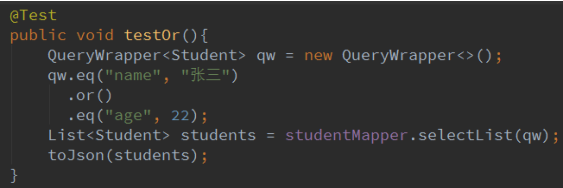
日志:

2.13 last
last 拼接 sql 语句
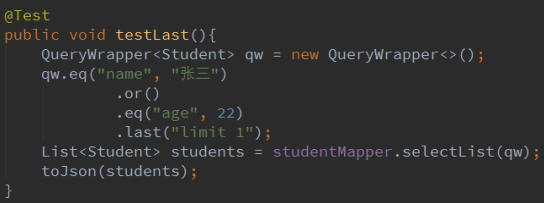
日志:
![]()
2.14 exists,notExists
exists 拼接 EXISTS ( sql 语句 ) notExists 是 exists 的相反操作
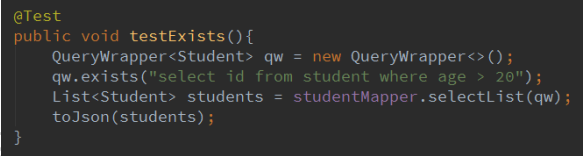
日志:
![]()
2.15 nested
2.16 having
2.17 apply
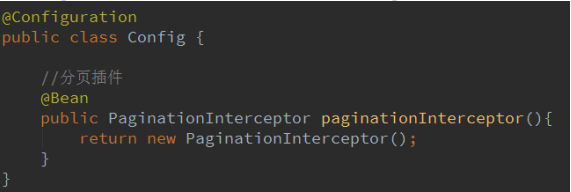
3.分页
前提: 配置分页插件,实现物理分页。默认是内存分页
分页查询:
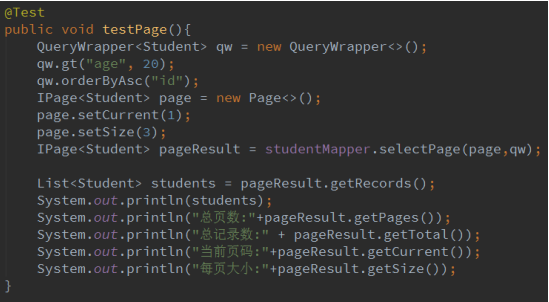
日志:
![]()
输出:

七.MP生成器
1.导入依赖
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.0</version>
</dependency>2.创建生成类

3.全局配置
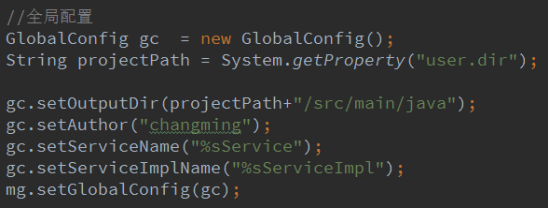
4.数据源配置
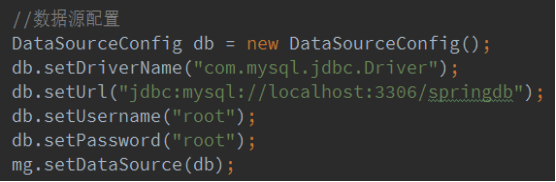
5.包和策略配置
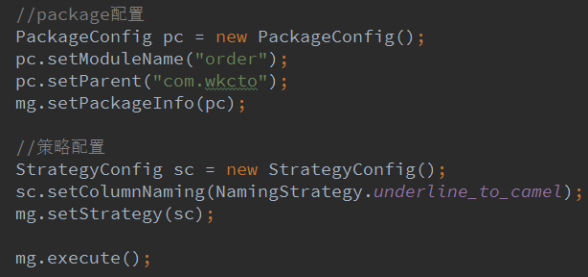
八.报错
九.思考















 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









