







知识剖析
-
什么是RHCS?
-
RHCS是Red Hat Cluster Suite的缩写,也就是红帽子集群套件,RHCS是一个能够提供高可用性、高可靠性、负载均衡、存储共享且经济廉价的集群工具集合,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境。
-
更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
-
RHCS提供了集群系统中三种集群构架,分别是高可用性集群、负载均衡集群、存储集群。
-
RHCS提供的三个核心功能
-
高可用集群: 是RHCS的核心功能。当应用程序出现故障,或者系统硬件、网络出现故障时,应用可以通过RHCS提供的高可用性服务管理组件自动、快速从一个节点切换到另一个节点,节点故障转移功能对客户端来说是透明的,从而保证应用持续、不间断的对外提供服务,这就是RHCS高可用集群实现的功能。
-
负载均衡集群: RHCS通过LVS来提供负载均衡集群,而LVS是一个开源的、功能强大的基于IP的负载均衡技术,LVS由负载调度器和服务访问节点组成,通过LVS的负载调度功能,可以将客户端请求平均的分配到各个服务节点,同时,还可以定义多种负载分配策略,当一个请求进来时,集群系统根据调度算法来判断应该将请求分配到哪个服务节点,然后,由分配到的节点响应客户端请求,同时,LVS还提供了服务节点故障转移功能,也就是当某个服务节点不能提供服务时,LVS会自动屏蔽这个故障节点,接着将失败节点从集群中剔除,同时将新来此节点的请求平滑的转移到其它正常节点上来;而当此故障节点恢复正常后,LVS又会自动将此节点加入到集群中去。而这一系列切换动作,对用户来说,都是透明的,通过故障转移功能,保证了服务的不间断、稳定运行。
-
存储集群: RHCS通过GFS文件系统来提供存储集群功能,GFS是Global File System的缩写,它允许多个服务同时去读写一个单一的共享文件系统,存储集群通过将共享数据放到一个共享文件系统中从而消除了在应用程序间同步数据的麻烦,GFS是一个分布式文件系统,它通过锁管理机制,来协调和管理多个服务节点对同一个文件系统的读写操作。
-
集群结构:

-
集群套件的作用
-
集群中luci的作用:
luci是用来配置和管理集群,监听在8084上 -
集群中ricci的作用:
ricci是安装在每个后端的每个节点上的,luci管理集群上的各个节点就是通过和节点上的ricci进行通信,ricci监听在11111上 -
集群中fence的作用:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资源进行了释放,保证了资源和服务始终运行在一个节点上。并且有效的阻止了“脑裂"的发生。
实验环境:
| 主机名 | IP | 服务 |
|---|---|---|
| server1 | 172.25.79.1 | ricci 、luci、httpd |
| server2 | 172.25.79.2 | ricci、httpd |
| foundation79 | 172.25.79.250 | fence |
搭建RHCS环境
一、 配置主机和server1,server2的环境环境
- 首先在server1和server2搭建高级的yum源
vim /etc/yum.repo//rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.79.250/rhel6.5
enabled=1
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.79.250/rhel6.5/HighAvailability
enabled=1
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.79.250/rhel6.5/LoadBalancer
enabled=1
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.79.250/rhel6.5/ResilientStorage
enabled=1
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.79.250/rhel6.5/ScalableFileSystem
enabled=1
gpgcheck=0
[root@server1 ~]# yum clean all
[root@server1 ~]# yum repolist
server2上同理
- 添加解析(物理机,server1和server2上都要做)
[root@foundation79 images]# vim /etc/hosts
[root@foundation79 images]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.79.1 server1
172.25.79.2 server2
172.25.79.3 server3
172.25.79.4 server4
172.25.79.5 server5
172.25.79.6 server6
server1和server2同上配置
- 在server1下载rhcs的图形网页管理工具
- ricci(图形里的集群管理)
- luci(图形界面)
- 修改ricci用户密码
- 开启ricci和luci
- 并设置开机自启
[root@server1 ~]# yum install ricci luci -y
[root@server1 ~]# passwd ricci
[root@server1 ~]# /etc/init.d/ricci start
[root@server1 ~]# /etc/init.d/luci start
[root@server1 ~]# chkconfig ricci on
[root@server1 ~]# chkconfig luci on
- 在server2上下载ricci,其余同server1上设置
[root@server2 ~]# yum install ricci -y
[root@server2 ~]# passwd ricci
[root@server2 ~]# /etc/init.d/ricci start
[root@server2 ~]# chkconfig ricci on
二、创建集群
(1)在浏览器中输入https://172.25.79.1:8084
- 因为是https访问,所以需要添加信任网络,点击Advanced …



(2)登陆帐号和密码是server1中的系统用户和密码,普通用户需要经过超级用户的审核才能登陆,所以一般选择超级用户登陆


(3)点击集群管理(Manager Clusters),然后点击create出现以下页面,创建一个集群westos_ha


- 然后点击(CreateCluster),进入等待页面,此时server1和server2会重启,然后在重新连接server1和server2
- 节点添加成功如下图

- 此时,在两个主机中的任一个上执行clustat,或者cat /etc/cluster/cluster.conf ,都可以查看到集群的信息



三、配置fence
- FENCE的原理:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资 源进行了释放,保证了资源和服务始终运行在一个节点上。
- 配置过程:
- 在主机上安装fence

- 编辑fence的配置文件

- 除了修改此处,其余回车即可



- 如果没有密钥目录,自己建立一个,并截取密钥

- 将修改好的密钥文件发送给节点server1和server2,保证server1和server2利用的是同一个密钥

- 打开fence服务

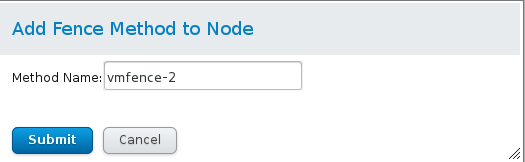
- 添加fence设备
- 点击Fence Devices,再点击Add
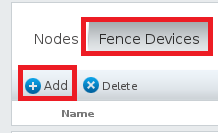
- 选择多播模式的fence

- 绑定节点(两个节点都要进行以下操作)
(1)server1
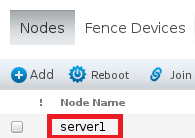

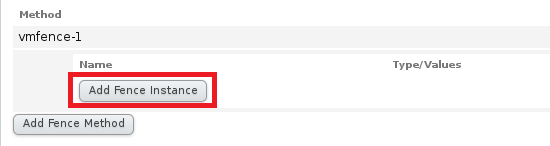

- UUID可以在虚拟机的管理截面看到

(2)server2同理

- 两个节点都绑定后配置文件内容应该如下:

- 测试:
在server2上通过fence干掉节点server2,使server2断电重启则为成功

四、高可用服务配置(httpd为例)
- 添加故障转移域

- 将sever1和server2添加在域中,即server1或server2出现故障时,切换到正常的那一个上,集群打开后,服务落在优先级高的节点上。(数字越小优先级越高)

- 添加服务中所要用到的资源(以httpd高可用为例)

- 添加IP Address(集群对外VIP) ,点击Submit提交
5 : 切换主机之间的时间

- 再点击Resources,点击Add,选择模式Script,添加启动httpd服务的脚本

- 向集群中添加上一步添加的资源(IP Address 和script)
- 第一步是创建一个资源组(服务中要用到资源的集合)apache


- 接着将资源添加进去


- 在server1 和server2上安装httpd服务,并编写默认测试页面内容

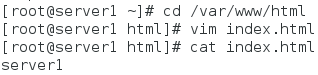

(2)server2上配置同理 - 刷新页面,显示httpd服务运行在server2上(优先级高)
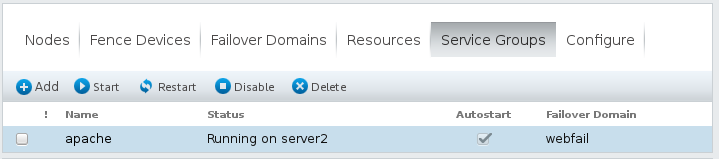

- 并且在server2上可以看到添加上的VIP

- 测试
(1)在物理机访问两台节点,正常
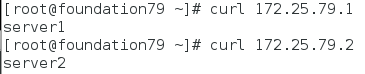
(2)在物理机访问VIP——>server2
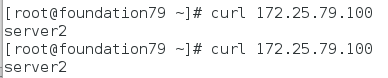
(3)测试高可用
- 在server2中,输入echo c> /proc/sysrq-trigger ,手动宕掉服务器

- 再次访问VIP,会发现访问切换到server1上,等server2重启成功之后,则又会切换到server2

- 注意:
一般在企业中,需要勾选 No Failback (故障不会切) 、
即当server2挂掉后,服务自动转到server1上,并且VIP也会自动飘过来,即使server2重启成功了,服务也不会再转回去 - 当关掉server2上的httpd,服务会自动转移到server1上

















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









