







目录
4、中文分词
4.1、什么是分词
分词就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。
举例:我是中国人 --> 我/是/中国人
4.2、分词api
指定分词器进行分词
POST /_analyze
{
"analyzer":"standard",
"text":"hello world"
}
POST /itcast/_analyze
{
"analyzer": "standard",
"field": "hobby",
"text": "听音乐"
}
4.4、中文分词
中文分词的难点在于,在汉语中没有明显的词汇分界点,如在英语中,空格可以作为分隔符,如果分隔不正确就会造
成歧义。
如:
我/爱/炒肉丝
我/爱/炒/肉丝
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,
IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算
法的中文分词组件。新版本的IK Analyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提
供了对Lucene的默认优化实现。
采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力 采用了多子处理器分析模式,支
持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇
(姓名、地名处理)等分词处理。 优化的词典存储,更小的内存占用。
IK分词器 Elasticsearch插件地址:https://github.com/medcl/elasticsearch-analysis-ik
#安装方法:将下载到的elasticsearch-analysis-ik-6.5.4.zip解压到/elasticsearch/plugins/ik目录下
即可。
mkdir es/plugins/ik
cp elasticsearch-analysis-ik-6.5.4.zip ./es/plugins/ik
#解压
unzip elasticsearch-analysis-ik-6.5.4.zip
#重启
./bin/elasticsearch
测试:
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
结果:
{
"tokens":[
{
"token":"我",
"start_offset":0,
"end_offset":1,
"type":"CN_CHAR",
"position":0
},
{
"token":"是",
"start_offset":1,
"end_offset":2,
"type":"CN_CHAR",
"position":1
},
{
"token":"中国人",
"start_offset":2,
"end_offset":5,
"type":"CN_WORD",
"position":2
},
{
"token":"中国",
"start_offset":2,
"end_offset":4,
"type":"CN_WORD",
"position":3
},
{
"token":"国人",
"start_offset":3,
"end_offset":5,
"type":"CN_WORD",
"position":4
}
]
}
5、全文搜索
全文搜索两个最重要的方面是:
- 相关性(Relevance) 它是评价查询与其结果间的相关程度,并根据这种相关程度对结果排名的一种能力,这
种计算方式可以是 TF/IDF 方法、地理位置邻近、模糊相似,或其他的某些算法。 - 分词(Analysis) 它是将文本块转换为有区别的、规范化的 token 的一个过程,目的是为了创建倒排索引以及查询倒排索引。
5.1、构造数据
PUT 127.0.0.1:9200/itcast
{
"settings":{
"index":{
"number_of_shards":"1",
"number_of_replicas":"0"
}
},
"mappings":{
"person":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"mail":{
"type":"keyword"
},
"hobby":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
}
post 127.0.0.1:9200/itcast/_bulk
{"index":{"_index":"itcast","_type":"person"}}
{"name":"张三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、篮球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、篮球、游泳、听音乐"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"赵六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、篮球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"孙七","age": 24,"mail": "555@qq.com","hobby":"听音乐、看电影、羽毛球"}
5.2、单词搜索
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"match":{
"hobby":"音乐"
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
过程说明:
- 检查字段类型
爱好 hobby 字段是一个 text 类型( 指定了IK分词器),这意味着查询字符串本身也应该被分词。 - 分析查询字符串 。
将查询的字符串 “音乐” 传入IK分词器中,输出的结果是单个项 音乐。因为只有一个单词项,所以 match 查询执
行的是单个底层 term 查询。 - 查找匹配文档 。
用 term 查询在倒排索引中查找 “音乐” 然后获取一组包含该项的文档,本例的结果是文档:3 、5 。 - 为每个文档评分 。
用 term 查询计算每个文档相关度评分 _score ,这是种将 词频(term frequency,即词 “音乐” 在相关文档的hobby 字段中出现的频率)和 反向文档频率(inverse document frequency,即词 “音乐” 在所有文档的hobby 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。
5.3、多词搜索
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"match":{
"hobby":"音乐 篮球"
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
可以看到,包含了“音乐”、“篮球”的数据都已经被搜索到了。
可是,搜索的结果并不符合我们的预期,因为我们想搜索的是既包含“音乐”又包含“篮球”的用户,显然结果返回的“或”的关系。
在Elasticsearch中,可以指定词之间的逻辑关系,如下:
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"match":{
"hobby":{
"query":"音乐 篮球",
"operator":"and"
}
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
前面我们测试了“OR” 和 “AND”搜索,这是两个极端,其实在实际场景中,并不会选取这2个极端,更有可能是选取这种,或者说,只需要符合一定的相似度就可以查询到数据,在Elasticsearch中也支持这样的查询,通过
minimum_should_match来指定匹配度,如:70%;
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"match":{
"hobby":{
"query":"游泳 羽毛球",
"minimum_should_match":"80%"
}
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
5.4、组合搜索
在搜索时,也可以使用过滤器中讲过的bool组合查询,示例:
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"bool":{
"must":{
"match":{
"hobby":"篮球"
}
},
"must_not":{
"match":{
"hobby":"音乐"
}
},
"should":[
{
"match":{
"hobby":"游泳"
}
}
]
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
上面搜索的意思是:
搜索结果中必须包含篮球,不能包含音乐,如果包含了游泳,那么它的相似度更高。
评分的计算规则
bool 查询会为每个文档计算相关度评分 _score , 再将所有匹配的 must 和 should 语句的分数 _score 求和,
最后除以 must 和 should 语句的总数。
must_not 语句不会影响评分; 它的作用只是将不相关的文档排除。
默认情况下,should中的内容不是必须匹配的,如果查询语句中没有must,那么就会至少匹配其中一个。当然了,也可以通过minimum_should_match参数进行控制,该值可以是数字也可以的百分比。
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"hobby":"游泳"
}
},
{
"match":{
"hobby":"篮球"
}
},
{
"match":{
"hobby":"音乐"
}
}
],
"minimum_should_match":2
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
minimum_should_match为2,意思是should中的三个词,至少要满足2个
5.5、权重
有些时候,我们可能需要对某些词增加权重来影响该条数据的得分。如下:
搜索关键字为“游泳篮球”,如果结果中包含了“音乐”权重为10,包含了“跑步”权重为2。
POST 127.0.0.1:9200/itcast/_search
{
"query":{
"bool":{
"must":{
"match":{
"hobby":{
"query":"游泳篮球",
"operator":"and"
}
}
},
"should":[
{
"match":{
"hobby":{
"query":"音乐",
"boost":10
}
}
},
{
"match":{
"hobby":{
"query":"跑步",
"boost":2
}
}
}
]
}
},
"highlight":{
"fields":{
"hobby":{
}
}
}
}
6、Elasticsearch集群
6.1、集群节点
ELasticsearch的集群是由多个节点组成的,通过cluster.name设置集群名称,并且用于区分其它的集群,每个节点通过node.name指定节点的名称。
在Elasticsearch中,节点的类型主要有4种:
- master节点
配置文件中node.master属性为true(默认为true),就有资格被选为master节点。
master节点用于控制整个集群的操作。比如创建或删除索引,管理其它非master节点等。 - data节点
- 配置文件中node.data属性为true(默认为true),就有资格被设置成data节点。
- data节点主要用于执行数据相关的操作。比如文档的CRUD。
- 客户端节点
- 配置文件中node.master属性和node.data属性均为false。
- 该节点不能作为master节点,也不能作为data节点。
- 可以作为客户端节点,用于响应用户的请求,把请求转发到其他节点
- 部落节点
- 当一个节点配置tribe.*的时候,它是一个特殊的客户端,它可以连接多个集群,在所有连接的集群上执行搜索和其他操作。
6.2、搭建集群
6.2.1、集群配置
#启动4个虚拟机,分别在3台虚拟机上部署安装
# 总本地上传
cd /usr/local
sudo rz
#分发到其它机器
scp -r /usr/local/elasticsearch-6.5.4 ip地址/usr/local/
#配置
vim config/elasticsearch.yml
#node01的配置:
cluster.name: es-kt-cluster
node.name: node01
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["master","salve1", "salve2","salve3"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.system_call_filter: false
#node02的配置:
cluster.name: es-kt-cluster
node.name: node02
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["master","salve1", "salve2","salve3"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.system_call_filter: false
#node03的配置:
cluster.name: es-kt-cluster
node.name: node03
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["master","salve1", "salve2","salve3"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.system_call_filter: false
#node04的配置:
cluster.name: es-kt-cluster
node.name: node04
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.ping.unicast.hosts: ["master","salve1", "salve2","salve3"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
bootstrap.system_call_filter: false
#分别启动4个节点
/bin./elasticsearch
6.2.2、遇到的问题
1. jdk必须1.8以上
linux安装openjdk1.8
1、使用yum查找jdk
yum search java|grep jdk
2、执行安装命令:
yum install java-1.8.0-openjdk
3、安装成功后,默认安装路径在
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
4、设置环境变量
修改/etc/profile文件:vi /etc/profile
在profile文件末尾新增如下内容:
#set java environment
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
5、使环境变量生效:
source /etc/profile
6、查看环境变量
echo $JAVA_HOME
2. 启动报错
[1]: max number of threads [1024] for user [hadoop] is too low, increase to at least [2048]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[3]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
解决方案
- max number of threads
vim /etc/security/limits.conf
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
vim /etc/security/limits.d/90-nproc.conf
soft nproc 2048
- vm.max_map_count
vi /etc/sysctl.conf
vm.max_map_count=262144
sudo sysctl -p
- system call filters
vim elasticsearch.yml
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
3.成功搭建集群

7、Java客户端
在Elasticsearch中,为java提供了2种客户端,一种是REST风格的客户端,另一种是Java API的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html
7.1、REST客户端
Elasticsearch提供了2种REST客户端,一种是低级客户端,一种是高级客户端。
- Java Low Level REST Client:官方提供的低级客户端。该客户端通过http来连接Elasticsearch集群。用户在使用该客户端时需要将请求数据手动拼接成Elasticsearch所需JSON格式进行发送,收到响应时同样也需要将返回的JSON数据手动封装成对象。虽然麻烦,不过该客户端兼容所有的Elasticsearch版本。
- Java High Level REST Client:官方提供的高级客户端。该客户端基于低级客户端实现,它提供了很多便捷的API来解决低级客户端需要手动转换数据格式的问题。
7.2、构造数据
PUT master:9200/haoke
{
"settings":{
"index":{
"number_of_shards":"5",
"number_of_replicas":"1"
}
},
"mappings":{
"house":{
"properties":{
"id":{
"type":"text"
},
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"price":{
"type":"integer"
}
}
}
}
}
POST master:9200/haoke/house/_bulk
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1001","title":"整租 · 南丹大楼 1居室 7500","price":"7500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1002","title":"陆家嘴板块,精装设计一室一厅,可拎包入住诚意租。","price":"8500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1003","title":"整租 · 健安坊 1居室 4050","price":"7500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1004","title":"整租 · 中凯城市之光+视野开阔+景色秀丽+拎包入住","price":"6500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1005","title":"整租 · 南京西路品质小区 21213三轨交汇 配套齐* 拎包入住","price":"6000"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1006","title":"祥康里 简约风格 *南户型 拎包入住 看房随时","price":"7000"}
7.3、REST低级客户端
7.3.1、创建工程
创建工程itcast-elasticsearch:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.qkongtao</groupId>
<artifactId>ElastSerarch</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.5.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.4</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.4.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
7.3.2、编写测试用例
package cn.kt.elastSearch;/*
*Created by tao on 2020-04-16.
*/
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.apache.http.util.EntityUtils;
import org.elasticsearch.client.*;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class TestElastSearch {
private static final ObjectMapper MAPPER = new ObjectMapper();
private RestClient restClient;
@Before
public void init() {
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("192.168.119.129", 9200, "http"),
new HttpHost("192.168.119.130", 9201, "http"),
new HttpHost("192.168.119.131", 9202, "http"),
new HttpHost("192.168.119.132", 9203, "http"));
restClientBuilder.setFailureListener(new RestClient.FailureListener() {
@Override
public void onFailure(Node node) {
System.out.println("出错了 -> " + node);
}
});
this.restClient = restClientBuilder.build();
}
@After
public void after() throws IOException {
restClient.close();
}
// 查询集群状态
@Test
public void testGetInfo() throws IOException {
Request request = new Request("GET", "/_cluster/state");
request.addParameter("pretty", "true");
Response response = this.restClient.performRequest(request);
System.out.println(response.getStatusLine());
System.out.println(EntityUtils.toString(response.getEntity()));
}
// 新增数据
@Test
public void testCreateData() throws IOException {
Request request = new Request("POST", "/haoke/house");
Map<String, Object> data = new HashMap<>();
data.put("id", "2001");
data.put("title", "张江高科");
data.put("price", "3500");
request.setJsonEntity(MAPPER.writeValueAsString(data));
Response response = this.restClient.performRequest(request);
System.out.println(response.getStatusLine());
System.out.println(EntityUtils.toString(response.getEntity()));
}
// 根据id查询数据
@Test
public void testQueryData() throws IOException {
Request request = new Request("GET", "/haoke/house/Qf5KgnEBGAiGoMOkYPTu");
Response response = this.restClient.performRequest(request);
System.out.println(response.getStatusLine());
System.out.println(EntityUtils.toString(response.getEntity()));
}
// 搜索数据
@Test
public void testSearchData() throws IOException {
Request request = new Request("POST", "/haoke/house/_search");
String searchJson = "{\"query\": {\"match\": {\"title\": \"拎包入住\"}}}";
request.setJsonEntity(searchJson);
request.addParameter("pretty", "true");
Response response = this.restClient.performRequest(request);
System.out.println(response.getStatusLine());
System.out.println(EntityUtils.toString(response.getEntity()));
}
}
从使用中,可以看出,基本和我们使用RESTful api使用几乎是一致的。
7.4、REST高级客户端
7.4.1、引入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.5.4</version>
</dependency>
7.4.2、编写测试用例
package cn.kt.elastSearch;/*
*Created by tao on 2020-04-16.
*/
import org.apache.http.HttpHost;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.*;
import org.elasticsearch.common.Strings;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/*
* REST高级客户端
*/
public class TestRestHighLevel {
private RestHighLevelClient client;
@Before
public void init() {
RestClientBuilder restClientBuilder = RestClient.builder(
new HttpHost("192.168.119.129", 9200, "http"),
new HttpHost("192.168.119.130", 9201, "http"),
new HttpHost("192.168.119.131", 9202, "http"),
new HttpHost("192.168.119.132", 9203, "http"));
this.client = new RestHighLevelClient(restClientBuilder);
}
@After
public void after() throws Exception {
this.client.close();
}
/**
* 新增文档,同步操作
*
* @throws Exception
*/
@Test
public void testCreate() throws Exception {
Map<String, Object> data = new HashMap<>();
data.put("id", "2002");
data.put("title", "南京西路 拎包入住 一室一厅");
data.put("price", "4500");
IndexRequest indexRequest = new IndexRequest("haoke", "house")
.source(data);
IndexResponse indexResponse = this.client.index(indexRequest,
RequestOptions.DEFAULT);
System.out.println("id->" + indexResponse.getId());
System.out.println("index->" + indexResponse.getIndex());
System.out.println("type->" + indexResponse.getType());
System.out.println("version->" + indexResponse.getVersion());
System.out.println("result->" + indexResponse.getResult());
System.out.println("shardInfo->" + indexResponse.getShardInfo());
}
/**
* 新增文档,异步操作
*
* @throws Exception
*/
@Test
public void testCreateAsync() throws Exception {
Map<String, Object> data = new HashMap<>();
data.put("id", "2003");
data.put("title", "南京东路 最新房源 二室一厅");
data.put("price", "5500");
IndexRequest indexRequest = new IndexRequest("haoke", "house")
.source(data);
this.client.indexAsync(indexRequest, RequestOptions.DEFAULT, new
ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
System.out.println("id->" + indexResponse.getId());
System.out.println("index->" + indexResponse.getIndex());
System.out.println("type->" + indexResponse.getType());
System.out.println("version->" + indexResponse.getVersion());
System.out.println("result->" + indexResponse.getResult());
System.out.println("shardInfo->" + indexResponse.getShardInfo());
}
@Override
public void onFailure(Exception e) {
System.out.println(e);
}
});
System.out.println("ok");
Thread.sleep(5000);
}
@Test
public void testQuery() throws Exception {
GetRequest getRequest = new GetRequest("haoke", "house",
"Hdxrg3EBeYpX1uNrluLH");
// 指定返回的字段
String[] includes = new String[]{"title", "id"};
String[] excludes = Strings.EMPTY_ARRAY;
FetchSourceContext fetchSourceContext =
new FetchSourceContext(true, includes, excludes);
getRequest.fetchSourceContext(fetchSourceContext);
GetResponse response = this.client.get(getRequest, RequestOptions.DEFAULT);
System.out.println("数据 -> " + response.getSource());
}
/**
* 判断是否存在
*
* @throws Exception
*/
@Test
public void testExists() throws Exception {
GetRequest getRequest = new GetRequest("haoke", "house",
"Hdxrg3EBeYpX1uNrluLH");
// 不返回的字段
getRequest.fetchSourceContext(new FetchSourceContext(false));
boolean exists = this.client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println("exists -> " + exists);
}
/**
* 删除数据
*
* @throws Exception
*/
@Test
public void testDelete() throws Exception {
DeleteRequest deleteRequest = new DeleteRequest("haoke", "house",
"_analyze");
DeleteResponse response = this.client.delete(deleteRequest,
RequestOptions.DEFAULT);
System.out.println(response.status());// OK or NOT_FOUND
}
/**
* 更新数据
*
* @throws Exception
*/
@Test
public void testUpdate() throws Exception {
UpdateRequest updateRequest = new UpdateRequest("haoke", "house",
"Pf5IgnEBGAiGoMOkV_S7");
Map<String, Object> data = new HashMap<>();
data.put("title", "张江高科2");
data.put("price", "5000");
updateRequest.doc(data);
UpdateResponse response = this.client.update(updateRequest,
RequestOptions.DEFAULT);
System.out.println("version -> " + response.getVersion());
}
/**
* 测试搜索
*
* @throws Exception
*/
@Test
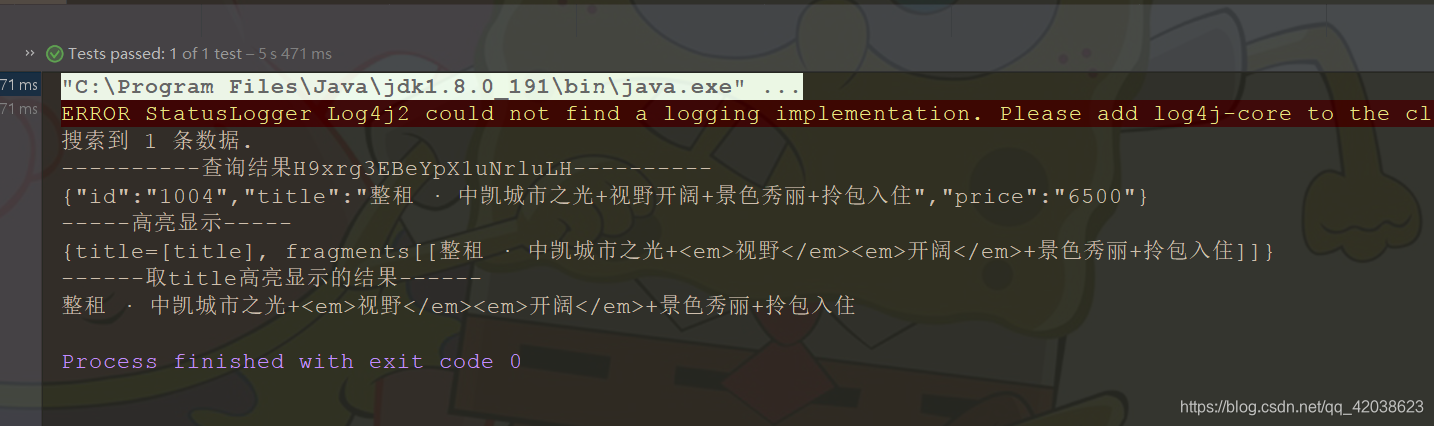
public void testSearch() throws Exception {
SearchRequest searchRequest = new SearchRequest("haoke");
searchRequest.types("house");
//高亮显示字段
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("<em>");
highlightBuilder.postTags("</em>");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("title", "视野开阔"));
sourceBuilder.from(0);
sourceBuilder.size(5);
sourceBuilder.highlighter(highlightBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse search = this.client.search(searchRequest,
RequestOptions.DEFAULT);
System.out.println("搜索到 " + search.getHits().totalHits + " 条数据.");
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
System.out.println("----------查询结果" + hit.getId() + "----------");
System.out.println(hit.getSourceAsString());
System.out.println("-----高亮显示-----");
System.out.println(hit.getHighlightFields());
//取title高亮显示的结果
HighlightField field = hit.getHighlightFields().get("title");
Text[] fragments = field.getFragments();
System.out.println("------取title高亮显示的结果------");
if (fragments != null) {
String title = fragments[0].toString();
System.out.println(title);
}
}
}
}
测试搜索结果
其余的api可以自己手动去测试

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











