







问题:
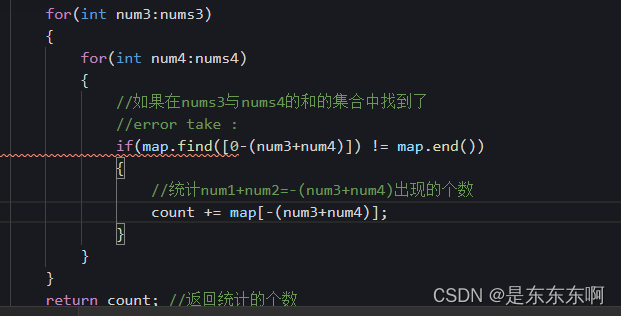
[ ]:在Lambda的方括号[ ]中命名局部变量称为捕获变量(capturing the variable),若在”[]“中没有指定变量,则在lambda表达式中不能使用。lambda捕获变量的方式是值传递的方式。
解决:去掉[]。
问题:
[ ]:在Lambda的方括号[ ]中命名局部变量称为捕获变量(capturing the variable),若在”[]“中没有指定变量,则在lambda表达式中不能使用。lambda捕获变量的方式是值传递的方式。
解决:去掉[]。











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 5164
5164





