







籍贯分类器
数据预处理
由于籍贯是新的分类量,原始数据存在部分错误的”脏“数据,还有不同标准情况下填写的籍贯信息。在分类的第一步对所有的籍贯信息进行整理是十分有必要的。
地理信息提取
我们按照以下步骤进行处理:
-
原始数据提取并转换成numpy格式
-
调用接口,建立”中国地理信息库“
数据转换后,需要提供一个标准数据库用以检索筛选。这里我们使用高德地图开发者API,考虑数据库规模以及实际填表情况,我们只调用全中国所有市级及以上行政单位信息。接口返回JSON格式信息,如下图所示。
我们对JSON数据进行提取,并按照中文习惯重新构建地理字典。在中文里,我们习惯将籍贯信息后面的省、市、自治区、特别行政区等进行简写,如”江苏省南京市“我们一般直接写成”江苏南京“。所以我们的字典里将相关信息删去,这样构建字典不仅可以为后面正则匹配提高准确率,还可以减小数据库规模。我们将构建好的数据库以JSON格式文件保存在本地,这样下次调用就无需再请求API。
-
正则匹配
数据库建立完成后,我们就可以在进行查找匹配了。我们将数据库以字典形式导入,字典键值分别为市级单位及其对应的省级单位。我们采用二次全局正则匹配的方式进行匹配:即第一次以省级单位作为模板对待匹配籍贯进行查找,若检索到则对原始值进行标准替换;否则再以市级单位进行查找,若检索到则直接对原始值以库内键值对应标准省级名称进行替换;若两次检索均失败,则抛出错误,进行人工手动标注。
最终经过匹配,在前期处理过后的437条数据中,共有432条数据匹配成功,5条匹配失败。这5条数据分别为:
原始序号 原始籍贯信息 9 重亲 212 寿光 215 吴浪 216 贺星 341 雷皓云 可以看到,这5条数据的匹配失败大致缘于3个原因:第9条数据将重庆误写成“重亲”;第212条数据“寿光”为山东潍坊市县级行政单位;第215、216、341条数据不存在中国的行政区划内,考虑可能将姓名误填成籍贯。
对第9、第212数据,我们将其修改正确后重新投入数据集,而最后三条数据由于缺乏其它可以佐证的信息,无法推断修正籍贯,故在籍贯分类器设计里将其去除。最终,我们获得了拥有434条数据,以省为元素的标准籍贯数据集。其中各省份统计如下表所示:
籍贯 数量 籍贯 数量 四川 129 甘肃 10 河南 36 广东 9 江西 26 贵州 9 重庆 24 江苏 7 安徽 24 广西 6 山东 22 内蒙古 5 湖北 20 吉林 3 湖南 15 新疆 3 陕西 14 辽宁 3 河北 14 黑龙江 3 福建 13 天津 2 山西 13 北京 1 浙江 11 海南 1 云南 11
地理信息划分
1. 按省份划分
从上一步的表格信息可以看出,我们的数据集分散分布在27个省份,且各个省份之间差距较大,显然直接按省份分类是不合理的。按照基本的理解,我们首先想到的就是去掉部分数量很小的省份。
小于10的省份并合并成其它,将生成的标准数据图进行数据统计,可以统计出各个省级单位的人员分布情况,如下图表所示:
从图上看出,虽然数据较之前密集了,但依然存在很多的类别。这种方式训练的决策树对判断是不利的,从下文的结果也可以佐证我们的猜想。
2. 按地理分区划分
既然直接省份划分不太合理,那我们就需要寻找一种合适的分类方式来对分类输出进行归并,解决输出的稀疏性问题。这里我参照百度词条:中国地理区划,将省份信息进行划分归组。
地理分区
| 地区名称 | 范围 |
|---|---|
| 北方地区 | 北京、天津、河北、山西、陕西、河南、山东 、黑龙江、吉林、辽宁 |
| 南方地区 | 江苏、安徽、浙江、上海、湖北、湖南、江西、福建、云南、贵州、四川、重庆、陕西、广西、广东、香港、澳门、海南、台湾、河南 |
| 西北地区 | 内蒙古、新疆、宁夏、甘肃 |
| 青藏地区 | 青海、西藏 |
行政分区
| 地区名称 | 范围 |
|---|---|
| 华北 | 北京市、天津市、河北省、山西省、内蒙古自治区 |
| 东北 | 黑龙江省、吉林省、辽宁省 |
| 华东 | 上海市、江苏省、浙江省、安徽省、江西省、山东省、福建省,以及台湾省 |
| 华中 | 河南省、湖北省、湖南省 |
| 华南 | 广东省、广西壮族自治区、海南省,以及香港特别行政区、澳门特别行政区 |
| 西南 | 重庆市、四川省、贵州省、云南省、西藏自治区 |
| 西北 | 陕西省、甘肃省、青海省、宁夏回族自治区、新疆维吾尔自治区、内蒙古自治区 |
经济分区
| 地区名称 | 范围 |
|---|---|
| 东部 | 北京、天津、河北、辽宁、上海、江苏、浙江、福建、山东、广东、广西、海南 |
| 中部 | 山西、内蒙古、吉林、黑龙江、安徽,江西、河南、湖北、湖南 |
| 西部 | 重庆、四川、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆 |
生成决策树
按照不同形式进行省份划分后,我们可以根据各个形式划分的方式进行决策树的搜索生成,并对比结果。我们利用sklearn官方库的寻优迭代器进行自动调参,并以5*5交叉验证后的平均准确率作为评估指标。下面是我们实验的结果。
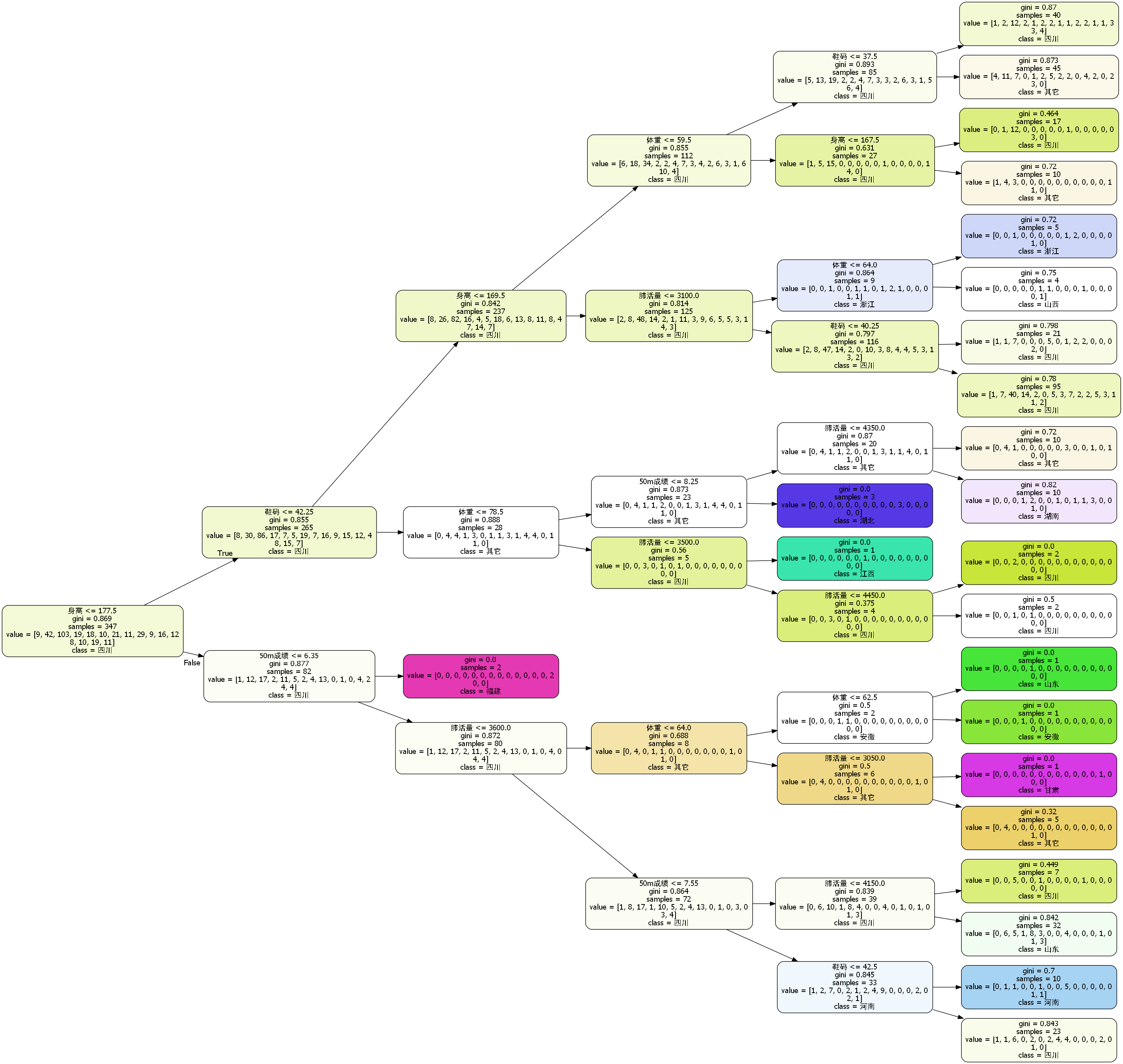
按省份划分
寻优调参后,最大得分划分结果如下,以省份划分之后检测平均准确率为25%:
按地理分区划分
寻优调参后,最大得分划分结果如下,以省份划分之后检测平均准确率为65%:
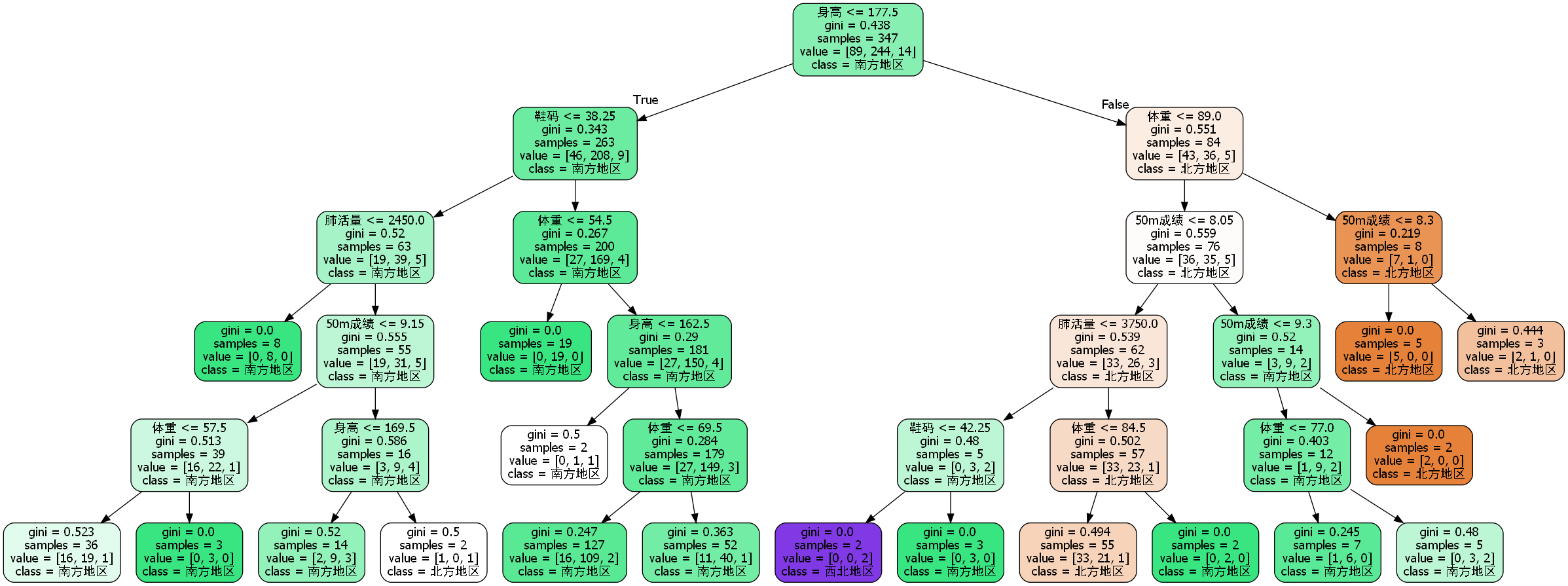
按行政分区划分
寻优调参后,最大得分划分结果如下,以地理分区划分之后检测平均准确率为40%:
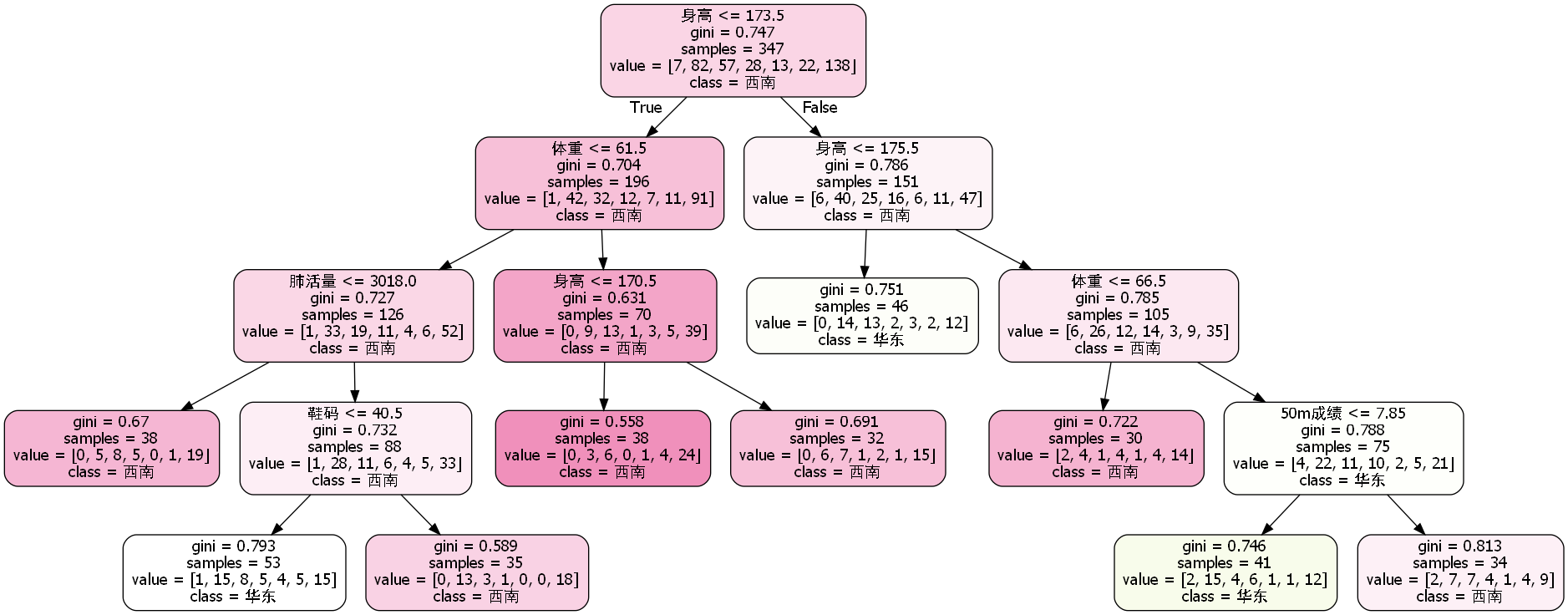
按经济分区划分
寻优调参后,最大得分划分结果如下,以地理分区划分之后检测平均准确率为35%:
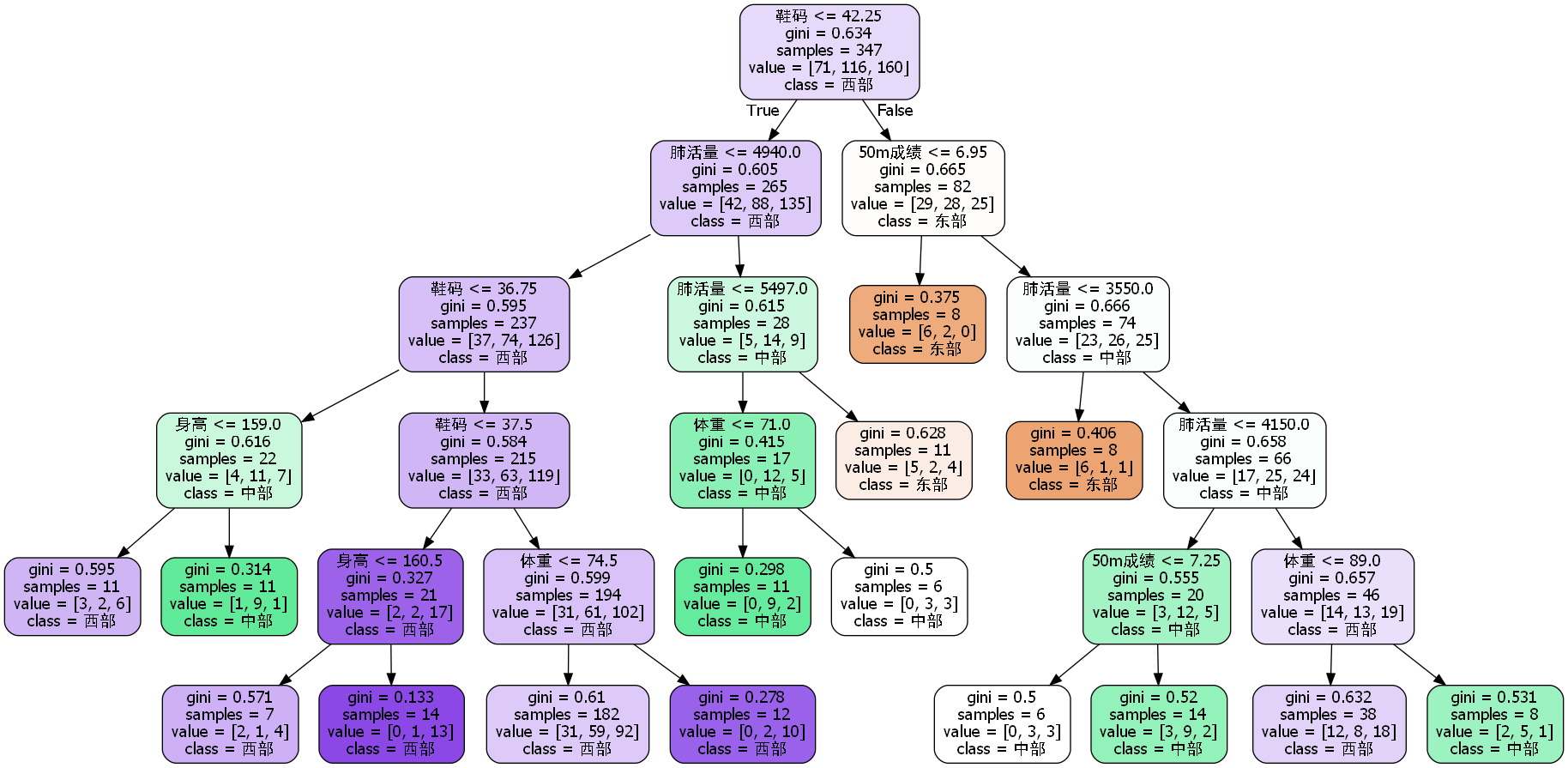
对比分析
经过前面对籍贯进行不同形式的归并,并统计结果统计后,我们发现将省份以地理分区归并对决策树的准确率提升较为明显。一开始,我们考虑到可能是由于分区较少导致对决策树准确率的提升。但在同样较少分区的经济分区划分方式里,决策树的平均准确率却只有地理分区的一半。最终我们猜测,可能是地理分区的籍贯划分方式符合我们数据集的潜藏特征分布,换句话说,也许按照地理分区的划分能够更明显的由数据集里的特征找到对应关联。
改进算法
随机森林
综上,虽然按照地理分区的划分方式我们大大提高了准确率,但还有没有方法提升我们的模型效果呢?
经过研究,我们决定再尝试Bagging里最典型的随机森林算法,用随即森林对决策树进行改进并与原始决策树进行评估,最终10次交叉验证后的准确率对比如下图:
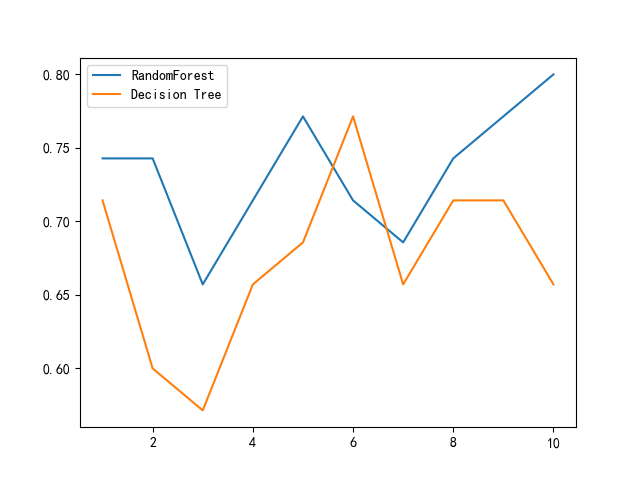
可以看出,使用随机森林算法对分类效果进一步产生了提升。经过比较,平均准确率相比决策树提高了约5%,这说明我们的改进是有意义的。
参考文献
https://scikit-learn.org/stable/modules/tree.html
https://blog.csdn.net/fuqiuai/article/details/79496005
https://zhuanlan.zhihu.com/p/123003914
https://stats.stackexchange.com/questions/105760/how-we-can-draw-an-roc-curve-for-decision-trees
https://www.cnblogs.com/ycycn/p/14063840.html
https://scikit-learn.org/stable/auto_examples/tree/plot_cost_complexity_pruning.html#sphx-glr-auto-examples-tree-plot-cost-complexity-pruning-py
https://www.cnblogs.com/genyuan/p/9828457.html
https://blog.csdn.net/luteresa/article/details/104927276
https://blog.csdn.net/R18830287035/article/details/89257857
https://www.cnblogs.com/genyuan/p/9828457.html
https://blog.csdn.net/luteresa/article/details/104927276
https://blog.csdn.net/R18830287035/article/details/89257857



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











