点击跳转到总目录
本篇只记录程序点击跳转项目
直接上代码
from selenium import webdriver
import time
import logging
import random
import openpyxl
wb = openpyxl.Workbook()
sheet = wb.active
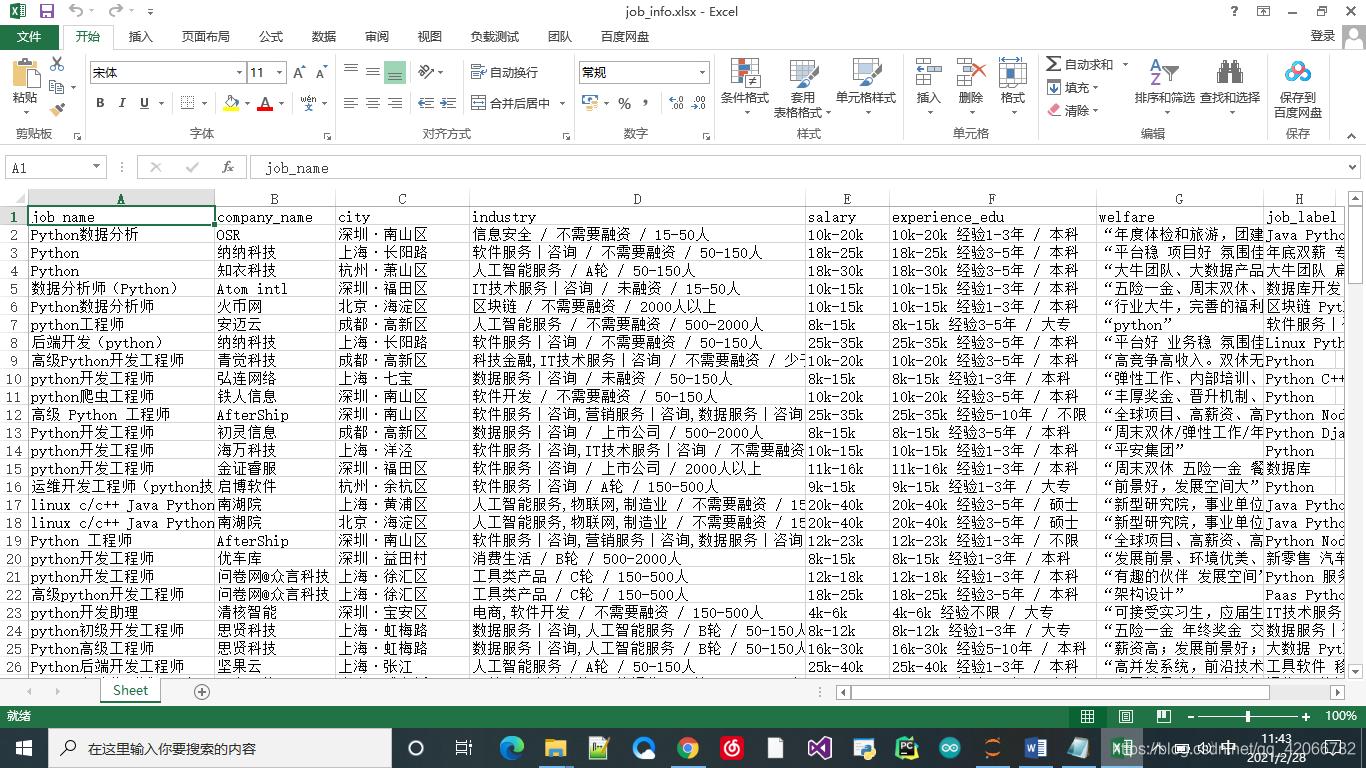
sheet.append(['job_name', 'company_name', 'city','industry', 'salary', 'experience_edu','welfare','job_label'])
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
def search_product(key_word):
browser.find_element_by_id('cboxClose').click()
time.sleep(2)
browser.find_element_by_id('search_input').send_keys(key_word)
browser.find_element_by_class_name('search_button').click()
browser.maximize_window()
time.sleep(2)
browser.find_element_by_class_name('body-btn').click()
time.sleep(random.randint(1, 3))
browser.execute_script("scroll(0,3000)")
get_data()
for i in range(10):
browser.find_element_by_class_name('pager_next ').click()
time.sleep(1)
browser.execute_script("scroll(0,3000)")
get_data()
time.sleep(random.randint(3, 5))
def get_data():
items = browser.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li')
for item in items:
job_name = item.find_element_by_xpath('.//div[@class="p_top"]/a/h3').text
company_name = item.find_element_by_xpath('.//div[@class="company_name"]').text
city = item.find_element_by_xpath('.//div[@class="p_top"]/a/span[@class="add"]/em').text
industry = item.find_element_by_xpath('.//div[@class="industry"]').text
salary = item.find_element_by_xpath('.//span[@class="money"]').text
experience_edu = item.find_element_by_xpath('.//div[@class="p_bot"]/div[@class="li_b_l"]').text
welfare = item.find_element_by_xpath('.//div[@class="li_b_r"]').text
job_label = item.find_element_by_xpath('.//div[@class="list_item_bot"]/div[@class="li_b_l"]').text
data = f'{job_name},{company_name},{city},{industry},{salary},{experience_edu},{welfare},{job_label}'
logging.info(data)
sheet.append([job_name, company_name, city,industry, salary, experience_edu, welfare, job_label])
def main():
browser.get('https://www.lagou.com/')
time.sleep(random.randint(1, 3))
search_product(keyword)
wb.save('job_info.xlsx')
if __name__ == '__main__':
keyword = 'Python 数据分析'
options = webdriver.ChromeOptions()
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option("excludeSwitches", ['enable-automation'])
browser = webdriver.Chrome(options=options, executable_path="E:\Google\Chrome\Application\chromedriver.exe")
main()
browser.quit()


























 2982
2982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









