







二.2.5 C语言中的有符号数与无符号数
如图2-9和图2-10所示,C语言支持所有整型数据类型的有符号和无符号运算。尽管C语言标准没有指定有符号数要采用某种表示,但是几乎所有的机器都使用补码。通常,大多数数字都默认为有符号的。例如,当声明一个像12345或者0X1A2B这样的常量时,这个值就被认为是有符号的。要创建一个无符号常量,必须加上后缀字母‘U’或者‘u’,例如,12345U或者0X1A2Bu。
C语言允许无符号数和有符号数之间的转换。虽然C标准没有精确规定应如何进行这种转换,但大多数系统遵循的原则是底层的位表示保持不变。因此,在一台采用补码的机器上,当从无符号数转换为有符号数时,效果就是应用函数U2Tw,而从有符号数转换为无符号数时,就是应用函数T2Uw,其中w表示数据类型的位数。
显式的强制类型转换就会导致转换发生,就像下面的代码:
1 int tx, ty;
2 unsigned ux, uy;
3
4 tx = (int) ux;
5 uy = (unsigned) ty;另外,当一种类型的表达式被赋值给另外一种类型的变量时,转换是隐式发生的,就像下面的代码:
1 int tx, ty;
2 unsigned ux, uy;
3
4 tx = ux; /*Cast to signed*/
5 uy = ty; /*Cast to unsigned*/当用printf输出数值时,分别用指示符%d、%u和%x以有符号十进制、无符号十进制和十六进制格式输出一个数字。注意printf没有使用任何类型信息,所以它可以用指示符%u来输出类型为int的数值,也可以用指示符%d输出类型为unsigned的数值。例如,考虑下面的代码:
1 int x = -1;
2 unsigned u = 2147483648; /*2 to the 31st*/
3
4 printf("x = %u = %d\n",x,x);
5 printf("u = %u = %d\n",u,u);当在一个32位机器上运行时,它的输出如下:
x = 4294967295 = -1
u = 2147483648 = -2147483648在这两种情况下,printf首先将这个字当作一个无符号数输出,然后把它当作一个有符号数输出。以下是实际运行中的转换函数:T2U32(-1)= UMax32 = 2^32 - 1和U2T32(2^31)= 2^31-2^32 = -2^31 = TMin32。
由于C语言对同时包含有符号和无符号数表达式的这种处理方式,出现了一些奇特的行为。当执行一个运算时,如果它的运算数是有符号的而另一个是无符号的,那么C语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。就像我们将要看到的,这种方法对于标准的算术运算来说并无多大差异,但是对于像<和>这样的关系运算来说,它会导致非直观的结果。图2-19展示了一些关系表达式的示例以及它们得到的求值结果,这里假设数据类型int表示为32位补码。考虑比较式-1<0U。因为第二个运算数是无符号的,第一个运算数就会被隐式地转换为无符号数,因此表达式就等价于4294967295U<0U(回想T2Uw(-1)= Umaxw),这个答案显然是错的。其他那些示例也可以通过相似地分析来理解。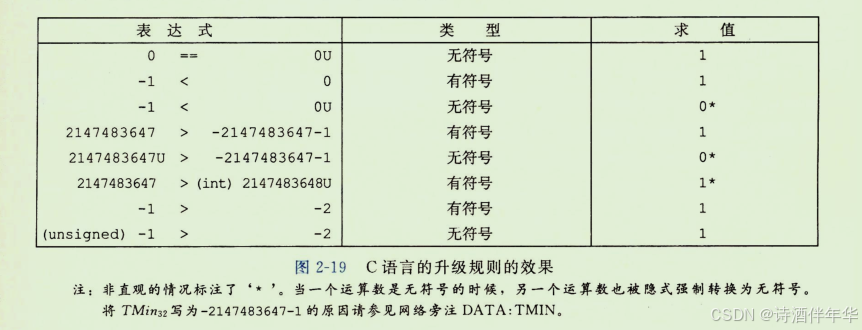
练习题2.21 假设在采用补码运算的32位机器上对这些表达式求值,按照图2-19的格式填写下标,描述强制类型转换和关系运算的结果。
| 表达式 | 类型 | 求值 |
| -2147483647-1==2147483648U | 无符号 | 1 |
| -2147483647-1 < 2147483647 | 有符号 | 1 |
| -2147483647-1U < 2147483647 | 无符号 | 0 |
| -2147483647-1 < -2147483647 | 有符号 | 1 |
| -2147483647-1U < -2147483647 | 无符号 | 1 |
网络旁注DATA:TMIN C语言中TMin的写法
在图2-19和练习题2.21中,我们很小心地将TMin32写成-2147483647-1。为什么不简单地写成-2147483648或者0x80000000?看一下C头文件limits.h,注意到它们使用了跟我们写TMin32和TMax32类似的方法:
/*Minimum and maximum values a ‘signed int’ can hold.*/ #define INT_MAX 2147483647 #define INT_MIN (-INT_MAX - 1)不幸的是,补码表示的不对称性和C语言转换规则之间奇怪的交互,迫使我们用这种不寻常的方式来写TMin32。虽然理解这个问题需要我们钻研C语言标准的一些比较隐晦的角落,但是它能够帮助我们充分领会整数数据类型和表示的一些细微之处。
二.2.6 扩展一个数字的位表示
一个常见的运算时在不同字长的整数之间转换,同时又保持数值不变。当然,当目标数据类型太小以至于不能表示想要的值时,这根本就是不可能的。然而,从一个较小的数据类型转换到一个较大的类型,应该总是可能得。
要将一个无符号数转换为一个更大的数据类型,我们只要简单地在表示的开头添加0。这种运算被称为零扩展(zero extension),表示原理如下:
原理:无符号数的零扩展
定义宽度为w的位向量u = [u(w-1),u(w-2)···,u0]和宽度为w1的位向量u1=[0,···,u(w-1),u(w-2),···,u0],其中w1>w。则B2Uw(u1)=B2Uw1(u1)。
按照公式(2.1),该原理可以看作是直接遵循了无符号数编码的定义。
要将一个补码数字转换为一个更大的数据类型,可以执行一个符号扩展(sign extension),在表示中添加最高有效位的值,表示为如下原理。我们用蓝色标出符号位x(w-1)来突出它在符号扩展中的角色。
原理:补码数的符号扩展
定义宽度为w的位向量x=[x(w-1),x(w-2),···,x0]和宽度为w的位向量x1=[x(w-1),···,x(w-1),x(w-1),x(w-2),···,x0],其中w1>w。则B2Tw(x) = B2Tw1(x1)。
例如,考虑下面的代码:
1 short sx = -12345; /*-12345*/
2 unsigned short usx = sx; /* 53191*/
3 int x = sx; /*-12345*/
4 unsigned ux = usx; /* 53191*/
5
6 printf("sx = %d:\t",sx);
7 show_bytes((byte_pointer)&sx,sizeof(short));
8 printf("usx = %u:\t",usx);
9 show_bytes((byte_pointer)&usx,sizeof(unsigned short));
10 printf("x = %d:\t",x);
11 show_bytes((byte_pointer)&x,sizeof(int));
12 printf("ux = %u:\t",ux);
13 show_bytes((byte_pointer)&ux,sizeof(unsigned));在采用补码表示的32位大端法机器上运行这段代码时,打印出如下输出:
sx = -12345:cf c7
usx = 53191:cf c7
x = -12345:ff ff cf c7
ux = 53191:00 00 cf c7
我们看到,尽管-12345的补码表示和53191的无符号表示在16位字长时是相同的,但是在32位字长时却是不同的。特别地,-12345的十六进制表示为0XFFFFCFC7,而53191的十六进制表示为0X0000CFC7。前者使用的是符号扩展——最开头加上了16位,都是最高有效位1,表示为十六进制就是0XFFFF。后者开头使用16个0扩展,表示为十六进制就是0X0000。
图2-20给出了从字长w=3到w=4的符号扩展的结果。位向量[101]表示值-4+1=-3。对它应用符号扩展,得到位向量[1101],表示的值-8+4+1 = -3。我们可以看到,对于w=4,最高两位的组合值是-8+4=-4,与w=3时符号位的值相同。类似地,位向量[111]和[1111]都表示值-1。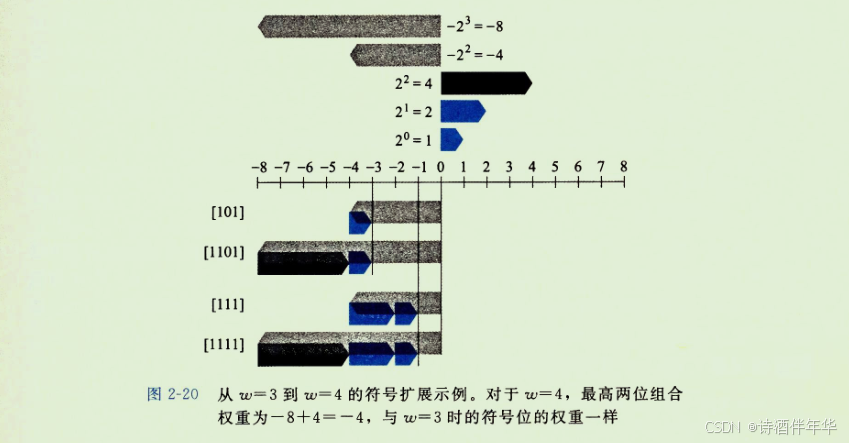
有了这个直觉,我们现在可以展示保持补码值的符号扩展。
推导:补码数值的符号扩展
令w1=w+k,我们想要证明的是 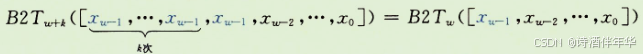
下面的证明是对k进行归纳。也就是说,如果我们能够证明符号扩展一位保持了数值不变,那么符号扩展任意位都能保持这种属性。因此,证明的任务就变为了: ![]()
用等式(2.3)展开左边的表达式,得到: 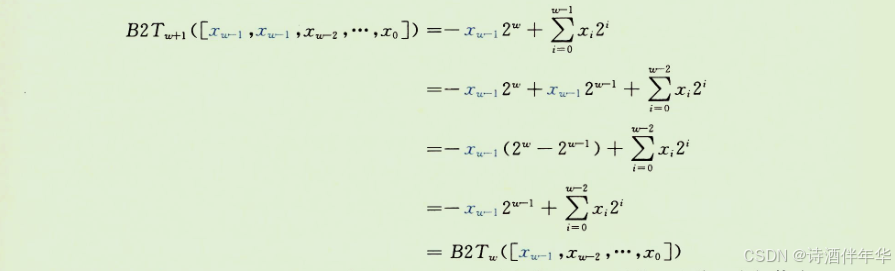
我们使用的关键属性是2^w-2^(w-1)。因此,加上一个权值为-2^w的位,和将一个权值为-2^(w-1)的位转换为一个权值为2^(w-1)的位,这两项运算的总和效果就会保持原始的数值。
练习题2.22 通过应用等式(2.3),表明下面每个向量都是-5的补码表示。可以看到第二个和第三个位向量可以通过对第一个位向量做符号扩展得到。
A. [1011] B.[11011] C.[111011]
值得一提的是,从一个数据大小到另一个数据大小的转换,以及无符号和有符号数字之间的转换的相对顺序能够影响一个程序的行为。考虑下面的代码:
1 short sx = -12345; /*-12345 */
2 unsigned uy = sx; /*Mystery!*/
3
4 printf("uy = %u:\t",uy);
5 show_bytes((byte_pointer)&uy,sizeof(unsigned)); 在一台大端法机器上,这部分代码产生如下输出:
uy = 4294954951: ff ff cf c7
这表明把short转换成unsigned时,我们先要改变大小,之后再完成从有符号到无符号的转换。也就是说(unsigned)sx等价于(unsigned)(int)sx,求值得到4294954951,而不等价于(unsigned)(unsigned short)sx,后者求值得到53191。事实上,这个规则是C语言要求的。
练习题2.23 考虑下面的C函数:
int fun1(unsigned word){
return (int) ((word<<24)>>24);
}
int fun2(unsigned word){
return ((int) word<<24)>>24;
}假设在一个采用补码运算的机器上以32位程序来执行这些函数。还假设有符号数值的右移是算数右移,而无符号数值的右移是逻辑右移。
A. 填写下标,说明这些函数对几个示例参数的结果。你会发现用十六进制表示来做会更方便,只要记住十六进制数字8到F的最高有效位等于1。
| w | fun1(w) | fun2(w) |
| 0x00000076 | 0X00000076 | 0X00000076 |
| 0x87654321 | 0X00000021 | 0X00000021 |
| 0x000000C9 | 0X000000C9 | 0xFFFFFFC9 |
| 0xEDCBA987 | 0X00000087 | 0XFFFFFF87 |
B. 用语言来描述这些函数执行的有用的计算。
二.2.7 截断数字
假设我们不用额外的位来扩展一个数值,而是减少表示一个数字的位数。例如下面代码中这种情况:
1 int x = 53191;
2 short sx = (short)x; /*-12345*/
3 int y = sx; /*-12345*/当我们把x强制类型转换为short时,我们就将32位的int截断为16位的short int。就像前面所看到的,这个16位的位模式就是-12345的补码表示。当我们把它强制类型转换回int时,符号扩展把高16位设置为1,从而生成-12345的32位补码表示。
当将一个w位的数x=[x(w-1),x(w-2),···,x0]。截断为一个k位数字时,我们会丢弃高w-k位,得到一个位向量x1=[x(k-1),x(k-2),···,x0]。截断一个数字可能会改变它的值——溢出的一种形式。对于一个无符号数,我们可以很容易得出其数值结果。
原理:截断无符号数
令x等于位向量[x(w-1),x(w-2),···,x0],而x1是将其截断为k位的结果:x1=[x(k-1),x(k-2),···,x0]。令x=B2Uw(x),x1=B2Uk(x1)。则x1=x mod 2^k。
该原理背后的直觉就是所有被截去的位其权重形式都为2^i,其中i≥k,因此,每一个权在取模操作下结果都为零。可用如下推导表示:
推导:截断无符号数
通过对等式(2.1)应用取模运算就可以看到: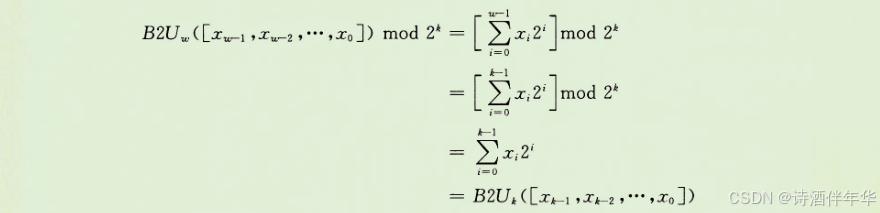
在这段推导中,我们利用了属性:对于任何i≥k,2^i mod 2^k = 0。
补码截断也具有相似的属性,只不过要将最高位转换为符号位:
原理:截断补码数值
令x等于位向量[x(w-1),x(w-2),···,x0],而x1是将其截断为k位的结果:x1=[x(k-1),x(k-2),···,x0]。 令x=B2Uw(x),x1=B2Tk(x1)。则x1 = U2Tk(x mod 2^k)。
在这个公式中,x mod 2^k将是0到2^k-1之间的一个数。对其应用函数U2Tk产生的效果是把最高有效位x^(k-1)的权重从2^(k-1)转变为-2^(k-1)。举例来看,将数值x = 53191从int转换为short。由于2^16 = 65536≥x,我们有x mod 2^16 = x。但是,当我们把这个数转换为16位的补码时,我们得到x1 = 53191 - 65536 = -123456。
推导:截断补码数值
使用与无符号数截断相同的参数,则有
B2Uw([x(w-1),x(w-2),···,x0])mod 2^k=B2Uk[x(k-1),x(k-2),···,x0]
也就是,x mod 2^k能够被一个位级表示为[x(k-1),x(k-2),···,x0]的无符号数表示。将其转换为补码数则有x1 = U2Tk(x mod 2^k)。
总而言之,无符号数的截断结果是:
B2Uk[x(k-1),x(k-2),···,x0] = B2Uw([x(w-1),x(w-2),···,x0]) mod 2^k (2.9)
而补码数字的截断结果是:
B2Tk[x(k-1),x(k-2),···,x0] = U2Tk(B2Uw([x(w-1),x(w-2),···x0]) mod 2^k) (2.10)
练习题2.24 假设将一个4位数值(用十六进制数字0~F表示)截断到一个3位数值(用十六进制数字0~7表示)。填写下表,根据那些位模式的无符号和补码解释,说明这种截断对某些情况的结果。
| 十六进制 | 无符号 | 补码 | |||
| 原始值 | 截断值 | 原始值 | 截断值 | 原始值 | 截断值 |
| 0 2 9 B F | 0 2 1 3 7 | 0 2 9 11 15 | 0 2 1 3 7 | 0 2 -7 -5 -1 | 0 2 1 3 -1 |
解释如何将等式(2.9)和等式(2.10)应用到这些示例上。
二.2.8 关于有符号数与无符号数的建议
就像我们看到的那样,有符号数到无符号数的隐式强制类型转换导致了某些非直观的行为。而这些非直观的特性经常导致程序错误,并且这种包含隐式强制类型转换的细微差别的错误很难被发现。因为这种强制类型转换是在代码中没有明确指示的情况下发生的,程序员经常忽视了它的影响。
下面两个练习题说明了某些由于隐式强制类型转换和无符号数据类型造成的细微的错误。
练习题2.25 考虑下列代码,这段代码试图计算数组a中所有元素的和,其中元素的数量由参数length给出。
/*WARNING:This is buggy code*/
float sum_elements(float a[],unsigned length){
int i;
float result = 0;
for(i = 0;i <= length-1; i++)
result += a[i];
return result;
}当参数length等于0时,运行这段代码应该返回0.0。但实际上,运行时会遇到一个内存错误。请解释为什么会发生这样的情况,并且说明如何修改代码。
练习题2.26 现在给你一个任务,写一个函数来判定一个字符串是否比另一个更长。前提是你要用字符串库函数strlen,它的声明如下:
/*Prototype for library function strlen*/
size_t strlen(const char *s);最开始你写的函数是这样的:
/*Determine whether string s is longer than string t*/
/*WARNING:This function is buggy*/
int strlonger(char *s,char *t){
return strlen(s) - strlen(t) > 0;
}当你在一些示例数据上测试这个函数时,一切似乎都是正确的。进一步研究发现在头文件stdio.h中数据类型size_t是定义成unsigned int的。
A. 在什么情况下,这个函数会产生不正确的结果?
答:当字符串s比字符串t短,该函数会返回一个正值。
B. 解释为什么会出现这样不正确的结果。
答:size_t 的本质是无符号数,当一个小的无符号数减去一个大的无符号数结果还是无符号数,无符号数表示范围大于等于0,返回正值。
C. 说明如何修改这段代码好让它能可靠地工作。
答:
return strlen(s)>strlen(t)旁注 函数getpeername的安全漏洞
2002年,从事FreeBSD开源操作系统项目的程序员意识到,他们对getpeername函数的实现存在安全漏洞。代码的简化版本如下:
/* * Illustration of code vulnerability similar to that found in * FreeBSD's implementation of getpeername() */ /* Declaration of library function memcpy */ void *memcpy(void *dest, void *src, size_t n); /* Kernel memory region holding user-accessible data */ #define KSIZE 1024 char kbuf[KSIZE]; /* Copy at most maxlen bytes from kernel region to user buffer*/ int copy_from_kernel(void *user_dest,int maxlen){ /*Byte count len is minimum of buffer size and maxlen*/ int len = KSIZE < maxlen ? KSIZE : maxlen; memcpy(user_dest,kbuf,len); return len; }在这段代码里,第7行给出的是库函数memcpy的原型,这个函数是要将一段指定长度为n的字节从内存的一个区域复制到另一个区域。
从第14行开始的函数copy_from_kernel是要将一些操作系统内核维护的数据复制到指定用户可以访问的内存区域。对用户来说,大多数内核维护的数据结构应该是不可读的,因为这些数据结构可能包含其他用户和系统上运行的其他作业的敏感信息,但是显示未kbuf的区域是用户可以读的。参数maxlen给出的是分配给用户的缓冲区的长度,这个缓冲区是用参数user_dest指示的。然后,第16行的计算确保复制的字节数据不会超出源或者目标缓冲区可用的范围。
不过,假设有些怀有恶意的程序员在调用copy_from_kernel的代码中对maxlen使用了负数值,那么,第16行的最小值计算会把这个值赋给len,然后len会作为参数n被传递给memcpy。不过,请注意参数n是被声明为数据类型size_t的。 这个数据类型是在库文件stdio.h中(通过typedef)被声明的。典型地,对32位程序它被定义为unsigned int,对64位程序定义为unsigned long。既然参数n是无符号的,那么memcpy会把它当作一个非常大的正整数,并且试图将这样多字节的数据从内核区域复制到用户的缓冲区。虽然复制这么多字节(至少2^31个)实际上不会完成,因为程序会遇到进程中非法地址的错误,但是程序还是会读到它没有被授权的内核内存区域。
我们可以看到,这个问题是由于数据类型的不匹配造成的:在一个地方,长度参数是有符号数;而另一个地方,它又是无符号数。正如这个例子表明的那样,这样的不匹配会成为缺陷的原因,甚至会导致安全漏洞。幸运的是,还没有案例报告有程序员在FreeBSD上利用了这漏洞。他们发布了一个安全建议,“FreeBSD-SA-02:32.signed-error”,建议系统管理员如何应用补丁消除这个漏洞。要修正这个缺陷,只要将copy_from_kernel的参数maxlen声明为类型size_t,也就是与memcpy的参数n一致。同时,我们也应该将本地变量len和返回值声明为size_t。
我们已经看到了许多无符号运算的细微特性,尤其是有符号数到无符号数的隐式转换,会导致错误或者漏洞的方式。避免这类错误的一种方式就是绝不使用无符号数。实际上,除了C语言以外很少有语言支持无符号整数。很明显,这些语言的设计者认为它们带来的麻烦要比益处多得多。比如,Java只支持有符号整数,并且要求以补码运算来实现。正常的右移运算符>>被定义为执行算术右移。特殊的运算符>>>被指定为执行逻辑右移。
当我们想要把字仅仅看做是位的集合而没有任何数字意义时,无符号数值是非常有用的。例如,往一个字中放入描述各种布尔条件的标记(flag)时,就是这样。地址自然地就是无符号的,所以系统程序员发现无符号类型是很有帮助的。当实现模运算和多精度运算的数学包时,数字是由字的数组来表示的,无符号值也会非常有用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









