







ABSTRACT
在以信息素为基础的害虫管理系统中,监测害虫数量是一个至关重要的组成部分。在本文中,我们提出了一种基于深度学习的自动检测管道,用于识别和计数田间诱捕器内拍摄的图像中的害虫。将该方法应用于一个商业毒蛾数据集,在定性和定量上都显示了良好的性能。与以前的害虫检测尝试相比,我们的方法没有使用特定于害虫的工程,这使得它能够以最少的人力适应其他物种和环境。它易于在并行硬件上实现,因此能够在需要实时性能的环境中部署。
1. Introduction
监测是基于信息素的虫害控制系统的关键组成部分(Carde和Minks,1995年;Witzgall等人,2010年)。在广泛使用的基于诱捕器的害虫监测中,捕获的数字图像由人类专家进行分析,以识别和计数害虫。人工计数是劳动密集型的,速度慢,成本高,有时容易出错,这妨碍了实现实时性能和成本目标。我们的目标是将最先进的深度学习技术应用于有害生物检测和计数,有效地将人类从循环中移除,以实现完全自动化的实时有害生物监测系统。
以前的大量工作考虑了昆虫分类。过去的文献可以按照几个维度进行分组,包括图像采集设置、特征和分类算法。就图像来源而言,以前的许多方法都考虑了昆虫标本(Kang等人,2012年、2014年;Arbuckle等人,2001年;Weeks等人,1999年;Tofilski,2004年;Wang等人,2012年)。标本通常保存完好,并在理想的实验室环境中成像。因此,样本图像是一致的,并以高分辨率捕获。在一个不太理想但更实际的场景中,其他一些工作试图对野外采集的昆虫进行分类,但在实验室条件下进行成像(拉里奥斯等人,2008年,2010年;马丁内斯·穆尼奥斯等人,2009年;莱特尔等人,2010年;萨克尔等人,2010年;乔等人,2007年;梅奥和沃森,2007年)。在这种情况下,图像质量通常比标本质量差,但研究人员通常仍有机会调整设置以控制图像质量,例如在标准方向或照明条件下对所有昆虫进行成像。
从算法角度来看,昆虫分类使用了各种类型的特征,包括翅膀结构(Kang等人,2012年、2014年;Arbuckle等人,2001年;Weeks等人,1999年;Tofilski,2004年)、颜色直方图特征(Le Qing和Zhen,2010年;Kaya和Kayci,2014年)、形态测量(Fedor等人,2008年;Yaakob和Jain,2012年;Tofilski,2004年;Wang等人,2012年)、当地图像特征(乐清和甄,2010年;Kaya和Kayci,2014年;Wen等人,2009年;Wen和Guyer,2012年;Lu等人,2012年;Larios等人,2011年)和全球图像特征(小林等人,2009年)在这些不同的特征提取方法之上,还使用了不同的分类器,包括支持向量机(SVM)(Wen等人,2009;Wang等人,2012;Larios等人,2010)、人工神经网络(ANN)(Wang等人,2012;Kaya和Kayci,2014;Fedor等人,2008)、k近邻(KNN)(Xiao Lin等人,2009年;Wen和Guyer,2012年)和集成方法(Larios等人,2008年;Martinez Munoz等人,2009年;Wen和Guyer,2012年)。但是,一般来说,这些建议的方法没有在实际应用场景下进行测试,例如,用于害虫监测的真实捕获器的图像。
除了分类之外,对象检测还涉及对象的定位。在昆虫检测方面已经做了一些尝试。一种选择是执行“滑动窗口”方法,其中分类器扫描图像不同位置的面片。该技术应用于散装小麦样品的检验(Zayas和Flinn,1998),其中原始图像中的局部补丁由工程特征表示,并通过判别分析进行分类。另一项关于散装谷物检验的工作(Ridgway等人,2002年)分别采用了不同的定制的基于规则的算法来检测不同的物体。执行检测的另一种方法是首先通过执行图像分割来提出初始检测候选。然后,这些候选者由工程特征表示并分类(Qing等人,2012年;Yao等人,2013年)。所有这些昆虫检测方法都经过严格设计,仅在特定环境下对特定物种有效,在害虫监测环境中不可能直接有效。
从诱捕器图像中检测害虫有两个主要挑战。第一个挑战是低图像质量,这是由于成像传感器的成本、功耗和图像传输速度等限制。这使得以前的大多数工作都不切实际,即基于高图像质量和精细结构的工作。第二个挑战来自由许多因素驱动的不一致性,包括照明、诱捕器的移动、飞蛾的移动、相机失焦、其他物体(如树叶)的外观、昆虫的腐烂或损坏、非害虫(良性)昆虫的外观、,这些使得设计基于规则的系统变得非常困难。因此,理想的检测方法应具有足够的能力和灵活性,以适应不同的变化因素,而不需要手动标记日常有害生物监测计划中的数据,只需最少的额外手动工作
长期以来,除了昆虫分类/检测外,一般视觉对象类别识别和检测一直是计算机视觉的主流。在过去几十年中,人们提出了各种方法和数据集(Zhang等人,2013年;Andreopoulos和Tsotsos,2013年),以推动这一领域的发展。最近,卷积神经网络(ConvNet)(LeCun等人,1998;Krizhevsky等人,2012)及其变体已成为目标识别和检测的最有效方法,在许多公认的数据集上实现了最先进的性能(Ciresan等人,2012;Lee等人,2014;Swersky等人,2013),以及赢得不同的物体识别挑战(Russakovsky等人,2015年;Krizhevsky等人,2012年;Szegedy等人,2015年)。
受这一研究的启发,我们采用了流行的带卷积神经网络的滑动窗口检测管道作为图像分类器。首先,对原始图像进行颜色校正预处理。然后,将训练好的神经网络应用于密集采样的图像块,以预测每个块包含害虫的可能性。然后,通过非最大值抑制对斑块进行过滤,然后仅保留概率高于其邻域的斑块。最后,对剩余的面片设置阈值。概率满足阈值的补丁被视为建议的检测。
本文有两个主要贡献。首先,我们开发了一种基于ConvNet的有害生物检测方法,该方法准确、快速、易于扩展到其他有害生物物种,并且只需要最少的数据预处理。第二,借鉴行人检测文献,我们提出了有害生物检测的评估指标
2. Data collection
在本节中,我们将介绍图像的收集、管理和预处理。第3节提供了对处理后的图像执行检测的详细信息。
2.1. Data acquisition
RGB彩色图像由信息素诱捕器捕获,该诱捕器由基于信息素的害虫控制解决方案的商业供应商安装在多个位置,其名称因请求而被保留。诱捕器包括一个信息素诱饵、一个粘性衬垫、一个数码相机和一个无线电发射机。信息素将感兴趣的害虫吸引到诱捕器中,在诱捕器中,害虫粘在粘着的表面上。数字图像以640*480分辨率的JPEG格式存储,并每天在固定时间点传输到远程服务器。虫蛀蛾由经过昆虫学培训的技术人员识别并用包围盒贴上标签。在本研究中,每个时间序列中只有一个图像被标记并使用,因此标记图像之间没有时间相关性。因此,所有标记的蛾子都是独一无二的。图1a显示了一个陷阱图像,所有的鳕鱼蛾都用蓝色边界框标记。图1b所示的图像中没有蛾类,但与其他种类的昆虫混杂在一起。高分辨率单个图像块将在后面的在图11中显示,其特征将在第5.3节中分析。

2.2. Dataset construction
采集的图像集随机分为3组:训练集、验证集和测试集。分割后,每个集合的统计信息与整个数据集大致相同,包括有蛾或无蛾的图像数量与每张图像的蛾数量之间的比率。表1提供了整个数据集和随后构建的三个拆分的具体统计信息。

2.3. Preprocessing
陷阱图像是在真实的生产环境中采集的,这导致在不同的时间点有不同的成像条件。这在照明中最为明显,如图2a所示。为了消除照明变化对检测性能的潜在负面影响,我们使用“灰色世界”方法的一种变体(Nikitenko等人,2008年)进行颜色校正。该算法假设红色(R)、绿色(G)和蓝色(B)通道的平均值应彼此相等。具体而言,对于每个图像,我们将R和B通道的增益设置如下:
![]()
![]() 和
和![]() 以及
以及![]() 分别是红色、绿色和蓝色通道的原始平均强度。
分别是红色、绿色和蓝色通道的原始平均强度。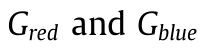 是分别应用于红色通道和蓝色通道的像素强度值的乘法增益。图2b示出了通过灰色世界算法处理的图像。我们看到,图像经过白平衡,具有相似的照明,但仍然保持丰富的颜色信息,这可以作为下游检测的有用线索。在本文中,所有图像在检测前都是白平衡的。
是分别应用于红色通道和蓝色通道的像素强度值的乘法增益。图2b示出了通过灰色世界算法处理的图像。我们看到,图像经过白平衡,具有相似的照明,但仍然保持丰富的颜色信息,这可以作为下游检测的有用线索。在本文中,所有图像在检测前都是白平衡的。

3. Detection pipeline
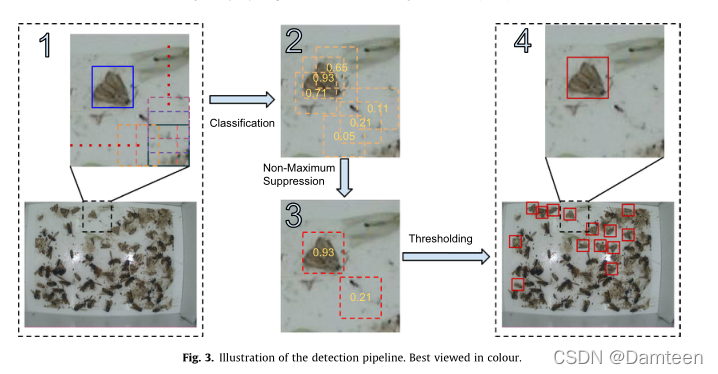
自动检测管道包括几个步骤,如图3所示。我们采用滑动窗口方法,将经过训练的图像分类器应用于整个图像不同位置的局部窗口。分类器的输出为![]() ,表示某一特定斑块中含有一只鳕鱼蛾的概率。这些面片在图像上规则而密集地排列,因此在很大程度上重叠。因此,我们执行非最大抑制(NMS)以仅保留其各自概率为局部最大的窗口。然后对剩余的框设置阈值,以便只保留超过一定概率的面片。这些补丁的位置及其各自的概率(置信度分数)是检测管道的最终输出。现在,我们将更详细地讨论每个阶段
,表示某一特定斑块中含有一只鳕鱼蛾的概率。这些面片在图像上规则而密集地排列,因此在很大程度上重叠。因此,我们执行非最大抑制(NMS)以仅保留其各自概率为局部最大的窗口。然后对剩余的框设置阈值,以便只保留超过一定概率的面片。这些补丁的位置及其各自的概率(置信度分数)是检测管道的最终输出。现在,我们将更详细地讨论每个阶段
3.1. Convolutional neural networks
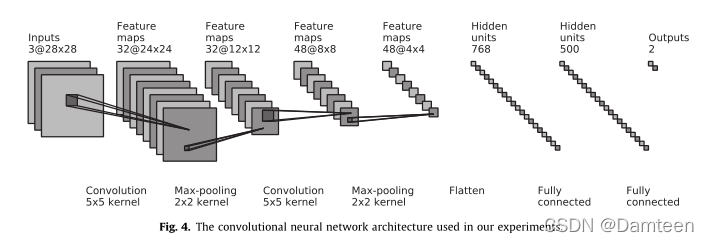
在滑动窗口方法中,检测问题分解为对每个局部面片进行分类,由图像分类器C执行,从图像到概率p:C:I#p的映射。我们采用卷积神经网络(LeCun et al.,1998)(ConvNet)作为我们的图像分类器,因为它是大规模(Krizhevsky et al.,2012;Szegedy et al.,2015)和小规模(Lin et al.,2013;Krizhevsky and Hinton,2009)问题中最流行和性能最好的图像识别分类器。它的部署速度也非常快,并且易于并行硬件。具体而言,我们使用了类似于Lenet5的网络结构(LeCun等人,1998年)。如图4所示。我们的网络包含2个卷积层、2个最大池层和2个完全连接的层(如下所述)。在应用ConvNet之前,输入的每个维度都被标准化为零均值和单位方差
3.1.1. Convolutional layers
卷积层将线性滤波器组和元素非线性应用于其输入“特征映射”,将其转换为不同的特征映射集。通过多次应用卷积层,我们可以提取输入的越来越高级的特征表示,同时保持它们的空间关系。在第一层,输入特征映射只是输入的通道。在随后的层中,这些表示图像的更抽象的变换。卷积层是完全连接层的特例,在第3.1.3小节中介绍。其中只有局部连接具有非零值,并且重量系在所有位置。通过应用卷积有效地实现本地连接:

3.1.2. Max-pooling layers
每个卷积层后面都有一个最大池层。该层将本地池操作应用于其输入特征映射,只保留本地感受野中的最大值,并丢弃所有其他值。它类似于卷积层,因为两者都是局部操作的。应用最大池层有两个主要好处:(1)减少自由参数的数量,(2)在网络中引入少量平移不变性
3.1.3. Fully connected layers
ConvNet中的最后两层是完全连接的。这些是在标准前馈神经网络中发现的层。第一个完全连接的层将最后一个最大池层之后的所有特征贴图展平(矢量化),将此一维向量视为整个图像的特征表示。第二个完全连接的层像线性分类器一样被参数化。从数学上讲,完全连接的层可以写成
![]()
3.2. Non-maximum suppression
在以滑动窗口方式应用ConvNet后,我们获得与每个密集采样面片相关的概率。如果我们在这一点上简单地应用阈值,我们将得到许多重叠检测。该问题通常使用非最大抑制(NMS)来解决,NMS的目的是仅保留局部概率最大的面片。我们采用了类似于Elzenszwalb等人(2010年)的策略。具体来说,我们首先根据概率对所有检测进行排序。然后,从高概率到低概率,我们查看每个检测并移除与当前检测重叠至少10%的其他边界框。在这个贪婪的过程之后,我们生成最终的检测输出,如下图所示。3以及随后的第5.1节。
4. Experiments and evaluation
接下来,我们将介绍我们如何进行实验和评估协议
4.1. Classifier training
分类器在生成的不同大小的补丁上进行训练,详见第 4.2 节。 使用动量的小批量随机梯度下降 (SGD) (LeCun et al., 2012) 来训练 ConvNet。 梯度是用众所周知的反向传播算法估计的(Rumelhart 等,1985)。 我们使用了 0.002 的固定学习率、256 的固定小批量大小和 0.9 的固定动量系数。 验证集用于监控训练过程和选择超参数。 我们使用分类器报告性能,该分类器的参数是根据观察到的最佳验证集精度选择的。 ConvNets 的过滤器和完全连接的权重矩阵使用从一个区间上的均匀随机分布中选择的值进行初始化,该区间是突触前和突触后单元数量的函数(更多细节参见 Glorot 和 Bengio,2010)
4.2. Training data extraction
在滑动窗口分类管道中,分类器采用局部窗口作为输入。因此,我们需要从原始的高分辨率图像中提取局部小块来训练分类器。这是以节省内存的方式执行的,使用指针算法创建数据的“视图”,而不是将所有补丁存储在内存中。
4.2.1. Positive patches
在这里,“正面片”指的是从手动标记的边界框中衍生出来的面片,其中每一个都代表一个codling蛾。当ConvNet处理方形输入时,我们忽略了手动标记的边界框的原始纵横比,并采用与原始矩形边界框具有相同中心的方形区域。图5a示出了从训练集提取的正补丁
4.2.2. Negative patches
通过简单地对标签边界框未覆盖的区域进行采样,很难覆盖可能出现的所有类型的误报。这是因为不包含蛾的区域的面积比边界框覆盖的面积大得多。在不太杂乱的图像上,大多数“负片”区域都是无趣的(例如陷阱衬层)。
因此,为了获得负面的训练示例,我们故意使用“硬”面片,即包含纹理的面片。具体地说,我们使用Canny边缘检测器(Canny,1986)在“负片图像”中查找补片,即。E不含任何蛾子的。我们设置阈值,使负斑的数量与标记的蛾类数量大致匹配。图5b示出了负片的随机样本。
4.2.3. Bootstrapping
在提取出初始的负面片集后,我们使用自举方法来寻找有用的负训练面片,从而使分类器更具区分性。在第一轮训练中,最初生成的面片用于训练分类器。在测试时,从训练集中收集假阳性斑块,并以分类器指定的最高概率分离出6000个阴性斑块。这些将与最初生成的补丁合并,形成用于第二阶段训练的新数据集。我们可能会使用更多轮的引导来收集更多信息量的负面补丁,但我们发现,包含两个以上的培训阶段并不能提高性能。图5c显示了在一个训练阶段后在测试阶段收集的随机抽样补丁。对于验证集,我们收集的面片数量与验证集中的图像数量成正比
4.3. Data augmentation
对于基于机器学习的方法,通常情况下,数据集越大,泛化性能越好。在我们的案例中,由训练补丁数量表示的训练数据量远小于深度学习社区经常使用的标准小规模图像分类数据集(Krizhevsky和Hinton,2009;LeCun和Cortes,1998),后者大约有50000个训练示例。因此,我们进行了数据扩充以增加训练图像的数量,并将基本几何变换的不变性纳入分类器。基于陷阱图像的“俯视”特性,当某个补丁稍微平移、翻转或旋转时,它不会更改其类标签。因此,我们将这些简单的几何变换应用于原始面片,以增加训练示例的数量
对于每个补丁,我们通过水平、垂直和对角移动±3个像素来创建8个翻译副本。我们还创建在水平轴和垂直轴上翻转的版本。最后,我们通过将原始文件旋转0、90、180和270度来创建4个旋转副本。这将从一个原始补丁生成72个增强补丁。图6示出了从单个示例生成的增强版本。
4.4. Detection
在检测阶段,我们需要设置步幅,即相邻滑动窗口之间的距离。较小的步幅意味着更密集的斑块覆盖,这导致蛾类更好的定位,但也需要更多的计算。作为一种折衷,我们将步幅设置为一块补丁的大小
4.5. Evaluation protocol
有害生物检测仍然是计算机视觉的一个相对“小生境”领域,因此没有定义标准的评估协议。我们决定采用受行人检测社区标准化启发的协议。Indolar等人(2012年)提供了一个完整的概述,我们总结如下
4.5.1. Matching detections with ground truth
我们根据错误检测、正确检测和误报的统计数据来评估检测性能。这里,误检测指的是算法遗漏的手动标记区域,假阳性指的是算法提出的不对应于任何手动标记区域的边界框。为了确定检测器提出的边界框是正确检测还是错误检测,我们通过计算最小交点(IOMin)启发式来确定其与手动标记边界框的对应关系:
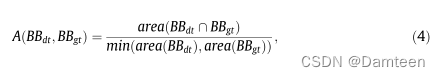
我们的评估指标不同于行人检测所使用的指标,因为我们使用IOMin代替更流行的Jaccard指数,也称为联合交叉口(IOU)。这是因为地面真相和探测之间可能存在形状不匹配。地面真值边界框都是矩形,但我们的分类器输出方形面片上的概率。在基本真相矩形接近正方形的情况下,IOU工作良好。然而,在地面真值矩形为高或宽的情况下,无论检测效果如何,IOU往往都很小。相反,IOMin启发式在这两种情况下都表现良好。
4.5.2. Object level evaluation
基于正确检测(也称为真阳性)、错误检测(也称为假阴性)和假阳性的统计数据,我们可以在两个级别上评估性能:(1)对象级别,重点是检测单个蛾的性能;和(2)图像级,其中焦点在于确定图像是否包含任何蛾。
在对象级别,我们使用五种依赖于阈值的度量:未命中率、每幅图像的误报率(FPPI)、精确度、召回率和FB分数:

除了FPPI之外,所有数量都是通过包含整个数据集的对应关系来计算的,并不代表单个图像的平均值
有两对衡量减少误报和减少误报之间权衡的指标:漏检率与FPPI,以及精度与召回率。未命中率与FPPI是行人检测社区中常见的性能指标(Dollar等人,2012年)。它给出了在误报数指定的某些公差下的系统精度估计。同样,精确与召回图显示了提高检测准确度和减少误检测之间的权衡
Fb分数只是一个衡量标准,其目的是在沿着精度-召回曲线的单个操作点上衡量精度和召回的重要性。它越大,性能越好。参数B调整精确性和召回率之间的重要性。在本文中,我们认为检测所有蛾比减少假阳性2更重要,因此我们重重回忆,设置B 2的所有报告结果。
当然,系统的每个操作点(阈值)都有一个FB分数。为了通过单个值总结未命中率与FPPI以及精度与召回率图所传达的信息,我们采用了两个标量性能度量:(1)FPPI在范围内时的对数平均未命中率(Carde和Minks,1995;Martinez-Munoz等人,2009),以及(2)精度-召回曲线下的面积(AUC)
4.5.3. Image level evaluation
在半自动检测的场景下,考虑了图像级别的性能评估,算法提出图像供技术人员检查,并安全地忽略不包含任何蛾子的图像。在这种设置下,算法只需要为每张图像提出一个“飞蛾”或“没有飞蛾”的建议,不管它认为有多少个飞蛾。在这里,我们将把包含至少一个蛾子的图像称为“真蛾子”图像,而把不包含蛾子的图像称为“无蛾子”图像。与对象水平评估类似,有五种依赖阈值的度量:敏感性(召回的同义词)、特异性、精确性和fbscore:

5. Results
在本节中,我们首先给出一些可视化的(定性的)结果,然后描述在第4节中引入的性能评估的结果。
5.1. Qualitative
图7显示了我们的检测器运行的例子。在两个面板中,左边的图像用绿色显示了手动标注的边框,用洋红色显示了检测器的建议。右边的图像显示了将注释与建议匹配的结果。错误检测、误报和正确检测分别用蓝色、红色和黄色框表示。InFig。7a和b,分别设置阈值,使物体水平和图像水平的f2-Score最大化。图9和10在全尺寸图像上显示了更多的检测结果示例

5.2. Quantitative
我们选择logistic回归作为基线,与ConvNet进行比较。我们在五种不同的输入量下测试了logistic回归和convnet:21-21、28-28、35-35、42-42和49-49。结果如表2所示。输入大小为21*21的ConvNet在对象级别上的性能最好,输入大小为35*35的ConvNet在图像级别上的性能最好。因此,图8示出了在对象和图像级别上比较最佳性能ConvNet和logistic回归的不同性能曲线。明显来自无花果。8(d)和(e),ConvNet在图像级取得了近乎完美的结果。对于查全率-查全率曲线,人们通常认为查全率会随着查全率的增加而降低。给你,英菲格。8(b)和(e),准确度有时会随着召回的增加而增加。这是因为当阈值降低时,新包含的检测可能都是真实检测,这导致精度和召回率都提高
为了了解数据增强(第4.3节)对探测器性能的影响,我们在输入尺寸为21*21同时使用(1)旋转和平动增强;(2)仅旋转增强;(3)仅平移增强;(4)无增宽。结果如表3所示。我们观察到,与完全不进行增强相比,平移和旋转增强都提高了性能。同时使用平移和旋转增强可以改善物体层面的性能,但不能改善图像层面的性能,因为单一类型的增强就足够了。
我们还在有限的训练数据下评估了所提方法的性能,如表4所示。我们可以看到,即使去掉80%的训练数据,算法仍然保持了合理的性能。这也表明了数据增强策略的有效性。
数据集中的部分飞蛾被其他飞蛾遮挡,增加了检测的难度。如果我们完全从数据集中移除遮挡,通过在评估过程中去除遮挡地面真相和与任何遮挡地面真相重叠超过50%的检测,我们在对象级别实现了轻微的性能改进。这里,precision-recall AUC从0.931增加到0.934,logaverage miss率从0.099下降到0.0916。这表明,我们的算法将在管理良好的站点执行得更好,在trap衬垫经常改变,从而减少遮挡。
5.3. Individual detection results
图11为具有不同检测结果的各种图像补丁,包括图。11a表示正确检测,11b表示错误检测,11c表示假阳性。这些补丁都是100*100的分辨率。它们是根据使用21*21的输入大小的检测结果提取的。我们可以看到,由于多种因素,包括不同的翅膀姿态,被其他物体遮挡,不同的衰减条件,不同的照明条件,不同的背景纹理,和不同的模糊条件,蛾子图像显示了高度的可变性。在这些畸变因素的作用下,有些飞蛾被成功探测到,有些被探测器忽略。从图11c中,我们也可以看到在21?根据分类器的考虑,有些错误的肯定在某种程度上在视觉上与21*21个图像补丁实际上是飞蛾。尽管对人类读者来说,通过查看整个100*100个的补丁(即考虑上下文)。这表明整合外围区域的信息可以帮助提高检测性能。
6. Discussion
与之前的大多数工作相比,本文提出的方法更多地依赖于数据,而较少地依赖于人类的知识。在设计我们的方法时,没有考虑到有关冰毒蛾的知识。该网络学会了仅基于积极和消极的训练例子来识别飞蛾。这一特性使系统更容易适应新的害虫种类和新的环境,无需太多的人工努力,只要提供相关数据
第5.3节分析了不同因素引起的误差。其中很多都与时间有关。随着时间的推移,同一只蛾子可能有不同的翅膀姿势、遮挡程度、光照和腐烂条件。视觉质感也与时间有关。例如,腐烂的昆虫会使原本白色的捕蚊线变得肮脏,并减少了蛾子和背景之间的反差。在实际生产系统中,如果时间图像序列具有合理的频率,可以在很大程度上避免由时间因素引起的误差。这导致了一个可能的未来研究方向,即,推理图像序列,同时检测单个图像上的蛾子,利用时间对应。由模糊图像引起的错误可以通过在预处理管道中添加去模糊过滤器来解决。非蛾类对象会造成一定数量的误报。解决这个问题的一种方法是训练常见的非蛾类物体的探测器,并将其与蛾类探测器结合起来。这里常见的物品包括信息素诱饵、苍蝇和树叶。这还需要具有更丰富的标签信息的数据集。
作为从诱捕图像中进行害虫自动检测的初步尝试,本文所介绍的方法除了已经提到的基于误差分析的方法外,还有许多可能的扩展。更深层次的卷积网络(Szegedy et al., 2015)可以提供更准确的图像patch分类。检测和分类多种类型的昆虫将是一个自然的延伸,这与细粒度图像分类问题密切相关(Wang et al., 2014;Razavian等人,2014)。检测的位置信息可以通过提出矩形边框、多边形或代表昆虫形状的参数化曲线来改进
7. Conclusions
本文介绍了一种利用诱捕器图像自动监测害虫的方法。我们提出了一种基于滑动窗口的检测管道,其中卷积神经网络应用于不同位置的图像补丁,以确定包含特定害虫类型的概率。然后,根据图像的位置和相关的置信度,对图像块进行非最大抑制和阈值滤波,产生最终的检测结果。定性和定量实验证明了该方法在一个飞蛾数据集上的有效性。我们还分析了检测误差,以及对实际生产系统的影响和未来可能的改进方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









