







在各种优化问题中,有一类特殊的优化问题与其他问题有显著不同,它就是整数规划问题,现在我们来看线性的整数规划如何在matlab中得到求解,我们需要的是intlinprog函数(intlinprog可分解为int lin prog,即integer +linear+ programming,‘整数’ ‘线性’ ‘规划’)。
在整数规划的问题上更进一步,增加约束条件,约定整数自变量的下限为0,上限为1,即将问题进一步约束成为了0-1规划问题。
-
intlinprog()函数的使用方法
1.我们先看这类问题的标准形式:

除了需要参数x中的一些值为整数外,与之前的线性规划完全相同,可以参考之前的文章
2.再来看函数的调用格式

与线性规划函数linprog函数的调用基本相同,不同之处在于多了一个intcon参数
这个参数,限定了在自变量矩阵x中哪些量是整数,例如:比如x1和x3是整数变量,那么intcon=[1,3];
-
整数规划例子
各个矩阵的含义参考专栏之前的“matlab解决有约束的线性规划”一文
【例】
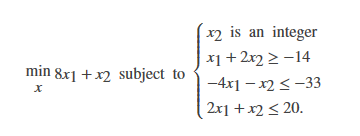
【求解】
f=[8 1];
A=[-1 -2;-4 -1;2 1];
b=[14 -33 20];
lb=zeros(2,1);
intcon=[2];
[x,fval,exitflag,output]=intlinprog(f,intcon,A,b,[],[],lb,[])运行结果
x =
6.5000
7.0000
fval =
59.0000-
0-1规划例子
【例】
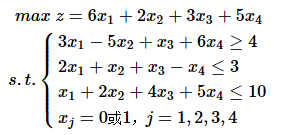
【求解】
f=[-6 -2 -3 -5]; %求解最大值,需要在目标函数前面加个符号,转化为求极小值问题
A=[-3 5 -1 -6;2 1 1 -1;1 2 4 5];
b=[-4 3 10]';
intcon=[1 2 3 4];
lb=zeros(4,1); %限定下限
ub=ones(4,1); %限定上限
[x,fval,exitflag,output]=intlinprog(f,intcon,A,b,[],[],lb,ub);
x,-fval %因为目标函数加了负号,因此显示结果时也要加负号
【结果】
x =
1.0000
0
1.0000
1.0000
ans =
14.0000
















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









