







第四章、串
4.1串的基本概念
串(string)是由零个或多个字符组成的有限序列。含零个字符的串称为空串,用表示。串中所含字符的个数称为该串的长度(或串长)。一般情况下,英文字母、数字(0,1,.,9)和常用的标点符号以及空格符等都是合法的字符。
两个串相等当且仅当这两个串的长度相等并且各对应位置上的字符都相同。一个串中任意个连续字符组成的序列称为该串的子串(substring),例如串"abcde"的子串有"a"、"ab"、" abc"和"abcd"等。
4.2串的存储结构
4.2.1串的顺序存储结构(顺序串)
顺序串与顺序表的存储实现方式是一样的。
typedef struct
{
char data[MaxSize]; //串中字符
int length; //串长
} SqString; 关于串的操作,主要介绍以下求子串、子串的插入和子串的删除这三个部分,其他串的操作与顺序表的操作相通,很简单,不做过多讲解。
求子串:
SqString SubStr(SqString s,int i,int j) //求子串
{
SqString str;
int k;
str.length=0;
if (i<=0 || i>s.length || j<0 || i+j-1>s.length)
return str; //参数不正确时返回空串
for (k=i-1;k<i+j-1;k++) //s.data[i..i+j]→str
str.data[k-i+1]=s.data[k];
str.length=j;
return str;
} 子串的插入:
SqString InsStr(SqString s1,int i,SqString s2) //插入串
{
int j;
SqString str;
str.length=0;
if (i<=0 || i>s1.length+1) //参数不正确时返回空串
return str;
for (j=0;j<i-1;j++) //s1.data[0..i-2]→str
str.data[j]=s1.data[j];
for (j=0;j<s2.length;j++) //s2.data[0..s2.length-1]→str
str.data[i+j-1]=s2.data[j];
for (j=i-1;j<s1.length;j++) //s1.data[i-1..s1.length-1]→str
str.data[s2.length+j]=s1.data[j];
str.length=s1.length+s2.length;
return str;
}子串的删除:
SqString DelStr(SqString s,int i,int j) //串删去
{
int k;
SqString str;
str.length=0;
if (i<=0 || i>s.length || i+j>s.length+1) //参数不正确时返回空串
return str;
for (k=0;k<i-1;k++) //s.data[0..i-2]→str
str.data[k]=s.data[k];
for (k=i+j-1;k<s.length;k++) //s.data[i+j-1..s.length-1]→str
str.data[k-j]=s.data[k];
str.length=s.length-j;
return str;
}4.2.2串的链式存储结构(链串)
链串的组织形式与一般的单链表类似,主要区别在于链串中的一个结点可以存储多个字符。
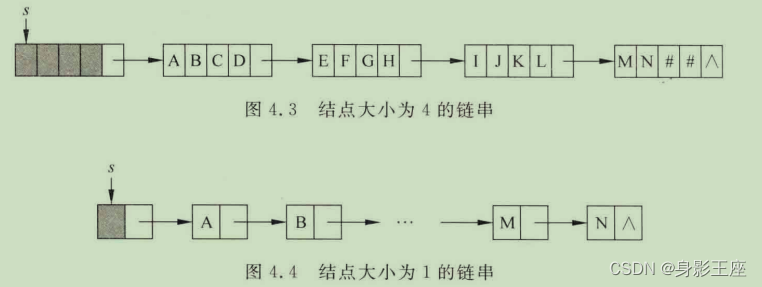
节点大小越大,虽然存储密度更高,但链串的删除、插入会移动大量元素,所以一般情况下节点大小设置为1。
typedef struct snode
{
char data;
struct snode *next;
} LinkStrNode;关于串的操作,主要介绍以下求子串、子串的插入和子串的删除这三个部分,其他串的操作与链表的操作相通,很简单,不做过多讲解。
求子串:
LinkStrNode *SubStr(LinkStrNode *s,int i,int j) //求子串
{
int k;
LinkStrNode *str,*p=s->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾节点
if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s))
return str; //参数不正确时返回空串
for (k=0;k<i-1;k++)
p=p->next;
for (k=1;k<=j;k++) //将s的第i个节点开始的j个节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}子串的插入:
LinkStrNode *InsStr(LinkStrNode *s,int i,LinkStrNode *t) //串插入
{
int k;
LinkStrNode *str,*p=s->next,*p1=t->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾节点
if (i<=0 || i>StrLength(s)+1) //参数不正确时返回空串
return str;
for (k=1;k<i;k++) //将s的前i个节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
while (p1!=NULL) //将t的所有节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p1->data;
r->next=q;r=q;
p1=p1->next;
}
while (p!=NULL) //将节点p及其后的节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}子串的删除:
LinkStrNode *DelStr(LinkStrNode *s,int i,int j) //串删去
{
int k;
LinkStrNode *str,*p=s->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾节点
if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s))
return str; //参数不正确时返回空串
for (k=0;k<i-1;k++) //将s的前i-1个节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
for (k=0;k<j;k++) //让p沿next跳j个节点
p=p->next;
while (p!=NULL) //将节点p及其后的节点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}4.3串的匹配模式
该部分不需要考虑实现,弄懂匹配过程就行,主要考究选择题和填空题。
4.3.1BF(简单匹配)算法

由于第一趟匹配后,S串第六位是b,必然知道向后移动一位肯定匹配不上。所以第二趟匹配就是多余的,那有没有一种方法避免这些无效的移位呢?
4.3.2KMP算法
消除了主串指针的回溯(无效的移位),在BF里面,每次只让子串向后移动一位,但是KMP算法可以让子串向后一次有效地移动多位,从而使算法效率有了某种程度的提高。
如何让子串(模式串)一次有效移动多位,首先计算next数组:
比如计算模式串t=“ababc”的next数组。
- 规定next[0] = -1(固定),规定next[1] = 0(固定)。
- 对于第三个字符a,前面是ab,ab的右子串只有b。b与ab左匹配没有一位可以匹配,所以next[2] = 0。
- 对于第四个字符b,前面是aba,aba的右子串有a和ba。a、ba与aba左匹配位数为1、0,取最大值,所以next[2] = 1。
- 对于第五个字符c,前面是abab,abab的右子串有b、ab和bab。a、ab、bab与abab左匹配位数为1、2、0,取最大值,所以next[2] = 2。

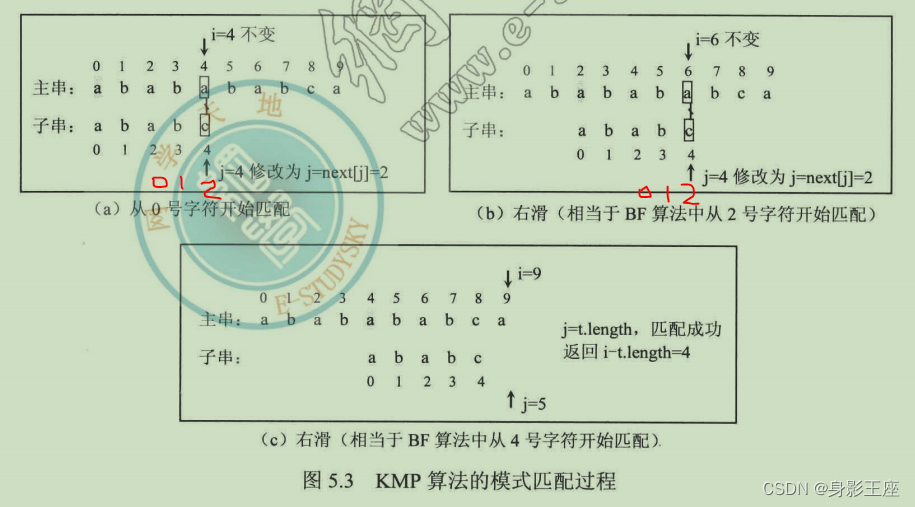
c从j=4的位置变成了之前j=2的位置上了。
当有了next数组之后,前面的例子采用KMP算法的模式匹配过程如图5.3所示。从中看到,由于利用了next数组中的信息,只从主串的0、2和4号字符开始比较,从而明显提高了匹配效率。
当模式串中有大量连续的字符,上述KMP算法并不能提高匹配效率。先看next[j]:
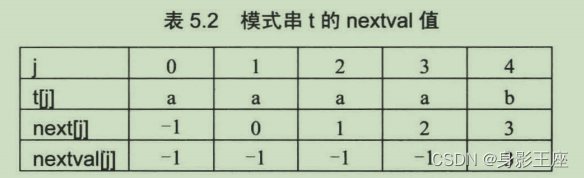

这个时候就需要计算nextval[j]数组了,其方法就是:nextval[0] = -1(固定),设k = next[j](k<j),若tj = tk ,则nextval[j] = nextval[k],若tj不等于tk,则nextval[j] = next[j]。

KMP算法考选择题和填空题,弄懂流程就行,不用代码实现。
第五章、递归
递归不是一个单独的考点,所以不着重讲解,后面讲树的时候还会讲到,这里主要就是通过一个例子形象地了解一下递归的思想。




第六章、数组和广义表
6.1数组
6.1.1数组的存储结构
数组由相同数据类型的数据组成的有限序列。
一维数组:
每个数组元素占据k个字节。
数组的地址:
如果下标从0开始:
二维数组:
按行优先存储:

注意:这里的下标都是从1开始的,如果下标从0(一般数组下标表示都是从0开始)开始,那就是:
按列优先存储:
如果下标从0(一般数组下标表示都是从0开始)开始,那就是:
6.1.2特殊矩阵的压缩存储
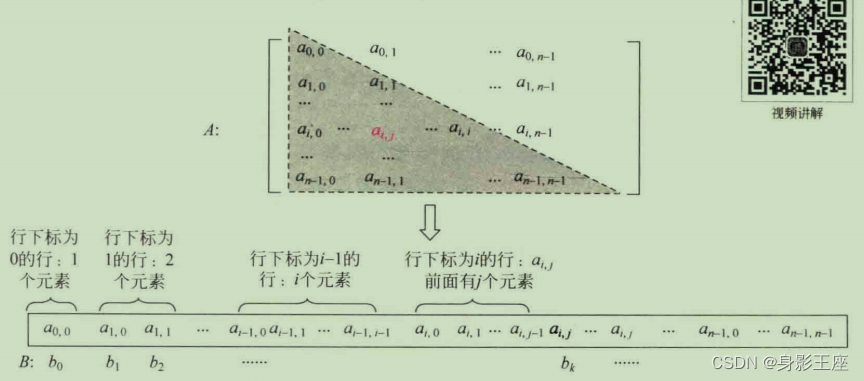
对称矩阵的压缩存储:
对称矩阵中的元素是按主对角线对称的,即上三角部分和下三角部分中的对应元素相等,因此在存储时可以只存储主对角线加上三角部分的元素,或者主对角线加下三角部分的元素,让对称的两个元素共享一个存储空间。
上下三角矩阵的压缩存储:
所谓上三角矩阵(upper triangular matrix),是指矩阵的下三角部分中的元素均为常数c的n阶方阵。同样,下三角矩阵(lower triangular matrix)是指矩阵的上三角部分中的元素均为常数c的n阶方阵。
上三角矩阵:

同理下三角矩阵为:
对角矩阵的压缩存储:
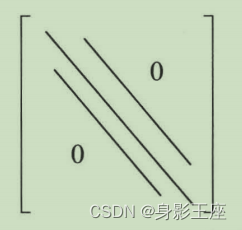
特别地,当m=3时称为三对角矩阵,上述对应关系为:k=2i+j。

6.2稀疏矩阵
当一个阶数较大的矩阵中的非零元素个数s相对于矩阵元素的总个数t非常小时,即s<<t时,称该矩阵为稀疏矩阵(sparse matrix)。例如一个100×100 的矩阵,若其中只有100个非零元素,就可称其为稀疏矩阵。
稀疏矩阵的三元组表示法:
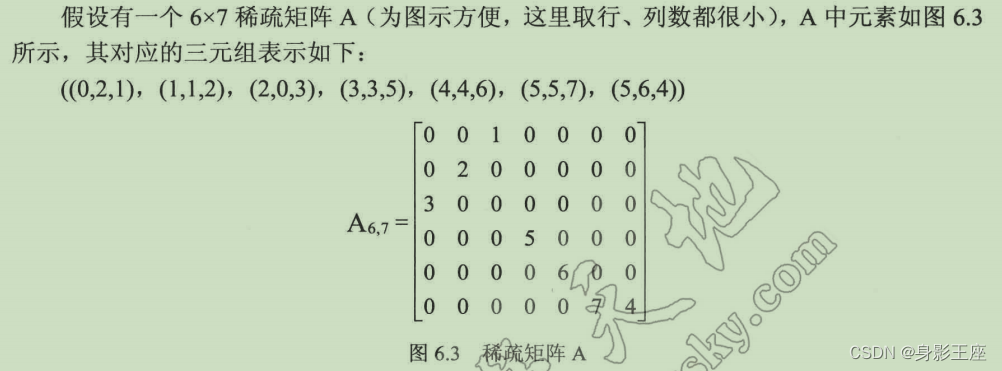
typedef int ElemType;
#define MaxSize 100 //矩阵中非零元素最多个数
typedef struct
{ int r; //行号
int c; //列号
ElemType d; //元素值
} TupNode; //三元组定义
typedef struct
{ int rows; //行数值
int cols; //列数值
int nums; //非零元素个数
TupNode data[MaxSize];
} TSMatrix; //三元组顺序表定义稀疏矩阵的十字链表表示法(了解一下就行):

#define M 3 //矩阵行
#define N 4 //矩阵列
#define Max ((M)>(N)?(M):(N)) //矩阵行列较大者
typedef struct mtxn
{
int row; //行号
int col; //列号
struct mtxn *right,*down; //向右和向下的指针
union
{
int value;
struct mtxn *link;
} tag;
} MatNode; //声明十字链表节点类型

6.3广义表
6.3.1广义表的定义
广义表(generalized table)是线性表的推广,是有限个元素的序列,其逻辑结构采用括号表示法表示如下:
其中n表示广义表的长度,若n=0,称为空表。ai为广义表的第i个元素,如果ai属于原子类型,称为广义表GL的原子(atom);如果a又是一个广义表,称为广义表GL的子表(subgeneralized table)。规定用小写字母表示原子,用大写字母表示广义表的表名。


广义表GL的表头为第一个元素a,其余部分(a2 ,…,ai,…,an)为GL 的表尾,分别记作head(GL)=a和 tail(GL)=(a2 ,…,ai,…,an)。显然,一个广义表的表尾始终是一个广义表。空表无表头、表尾。这里仍取上面的示例:

广义表的深度定义为所含括弧的重数,其中原子的深度为0,空表的深度为1。广义表C、D、E的深度分别为2、3和4。
6.3.2广义表的存储结构
广义表是一种递归的数据结构,因此很难为每个广义表分配固定大小的存储空间,所以其存储结构只好采用链式存储结构。
广义表有两类结点,一类为圆圈结点,在这里对应子表;另一类为方形结点,在这里对应原子。

前面的广义表C的链式存储结构:

typedef char ElemType;
typedef struct lnode
{
int tag; //节点类型标识
union
{
ElemType data;
struct lnode *sublist;
} val;
struct lnode *link; //指向下一个元素
} GLNode; //声明广义表节点类型

对应的广义表为:g=((((a),b)),(((#),(c)),d,e))。
这几章基本考的是填空、选择和应用题,基本不考算法题。所以基本不考虑相关操作的实现,但是基本的结构体类型表示相关的表要会写。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











