






1.kafka分布式消息队列
(1).概述
Kafka是由LinkedIn开发的一个分布式的消息系统,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成
设计目标
以时间复杂度为O(1)的方式提供消息持久化能力,对TB级以上数据也能保证常数时间复杂度的访问性能
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输
支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输
同时支持离线数据处理和实时数据处理
Scale out:支持在线水平扩展
(2).为什么使用消息队列
解耦、冗余、扩展性、灵活性 & 峰值处理能力、可恢复性、顺序保证、缓冲、异步通信
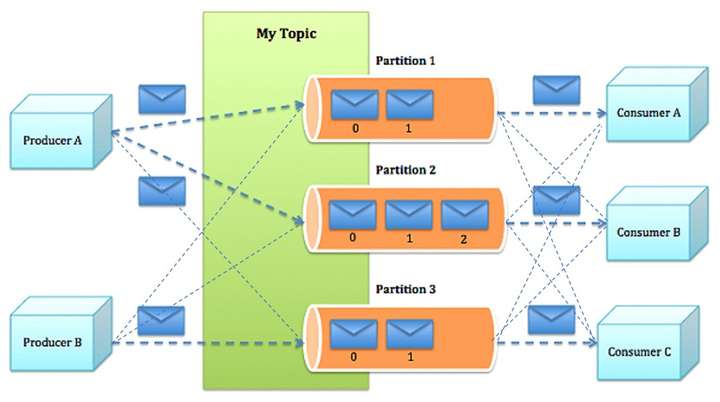
(3).体系结构
(4).基本原理
(4-1).分布式
Commit Log 的 partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。kafka集群支持配置一个partition备份的数量
针对每个partition,都有一个broker起到“leader”的作用,0个多个其他的broker作为“follwers”的作用
leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker都是自己所管理的partition的leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡
(4-2).消息生产
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区
主要两种方式
round-robin做简单的负载均
根据消息中的某一个关键字来进行区分
Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
(4-3).消息消费
消息传递模式
队列(queuing),多个consumer从服务器中读取数据,根据消费者自己定义的队列数据位置来得到数据
发布订阅(publish-subscribe),在 publish-subscribe模型中,消息会被广播给所有的consumer
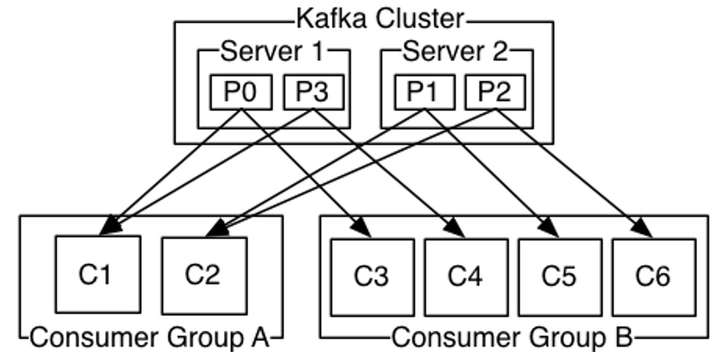
Kafka提供了一种consumer的抽象概念:consumer group
每个consumer都要标记自己属于哪一个consumer group
发布到topic中的message会被传递到consumer group中的一个consumer 实例
consumer实例可以运行在不同的进程上,也可以在不同的物理机器上
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡
(4-4).消费顺序
Kafka通过Topic中partition概念实现并行消费
Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡
实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance
通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性
(5).kafka优化
多磁盘并且不做raid,就是为了充分利用多磁盘并发读写,又保证每个磁盘连续读写 的特性
合理设置topic的partition数量,保证并发度
Jvm参数调优推荐使用 CMS或者G1 垃圾回收器,内存不宜过大4G左右即可
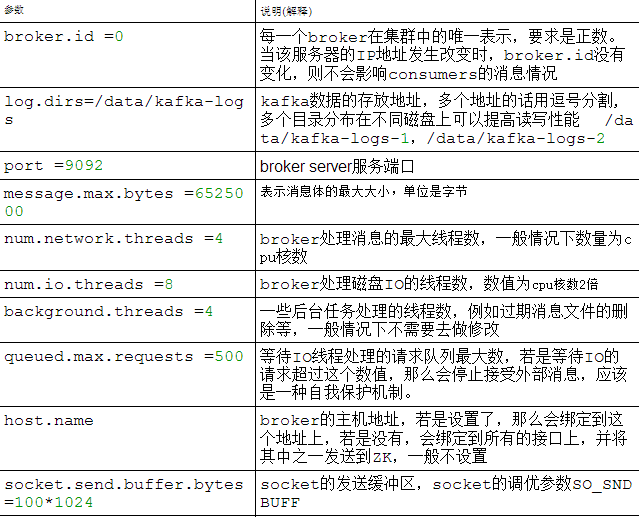






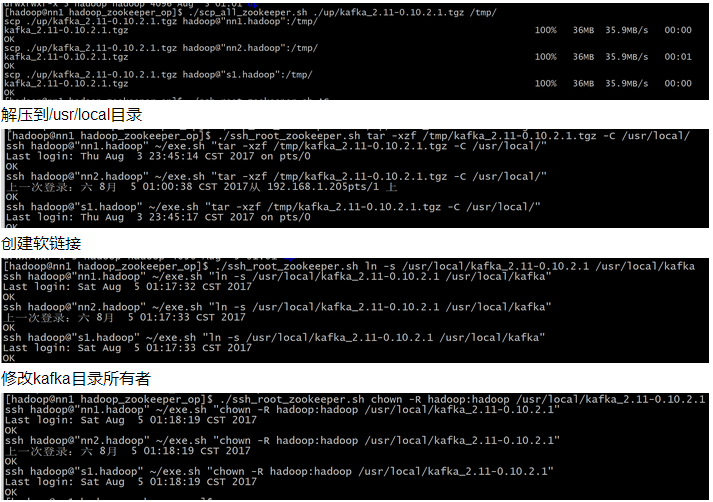
2.kafka安装
复制到每台机器
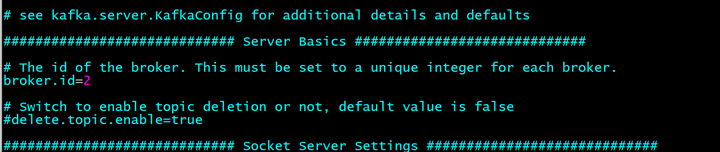
修改/usr/local/kafka/config/server.properties文件
定义端口

设置zookeeper地址和超时时间

配置producer服务地址 producer.properties

配置consumer地址 consumer.properties

配置log存储目录,设成多硬盘方式

设置日志数据是否自动删除

拷贝配置文件到每台机器
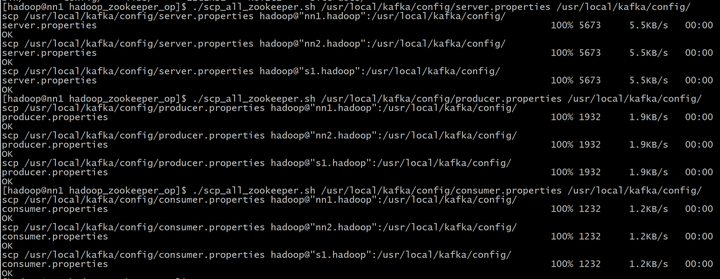
这个设置要每台机器不一样,和zookeepery的myid一个意思 server.properties
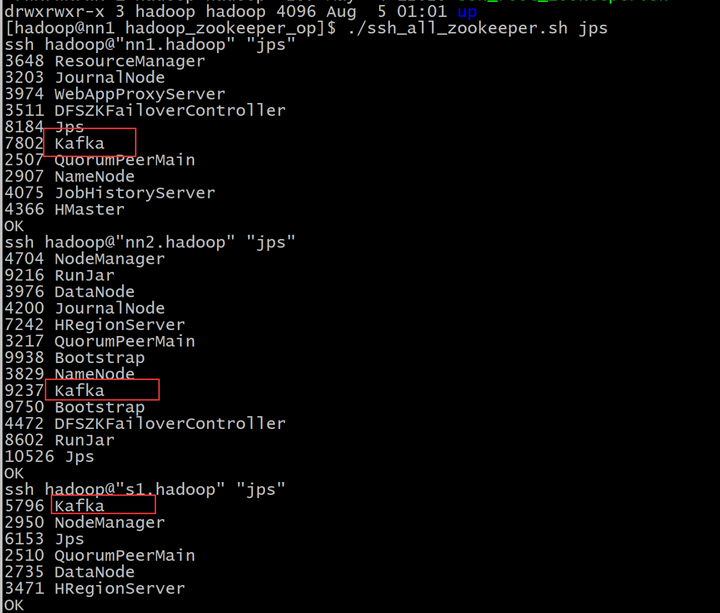
./ssh_all_zookeeper.sh "nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties > /tmp/kafka_logs 2>&1 &"
创建topic
/usr/local/kafka/bin/kafka-topics.sh --create --replication-factor 2 --partitions 2 --topic hainiu_test --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
这里指定了2个副本,2个分区,topic名为hainiu_test,并且指定zookeeper分布
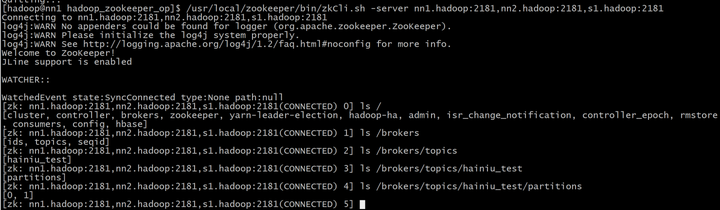
查看zk中的信息
/usr/local/zookeeper/bin/zkCli.sh -server nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
查看topic的详情
/usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_test

删除topic
/usr/local/kafka/bin/kafka-topics.sh --delete --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_test

手动永久删除topic:
删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录
删除zookeeper "/brokers/topics/"目录下相关topic节点
启动一个消费者
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_test

启动一个生产者
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092 --topic hainiu_test

停止kafka服务
./ssh_all_zookeeper.sh /usr/local/kafka/bin/kafka-server-stop.sh
3.kafka开发 java api
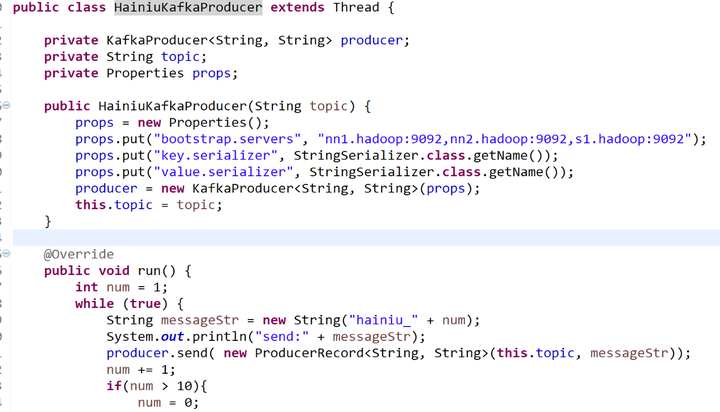
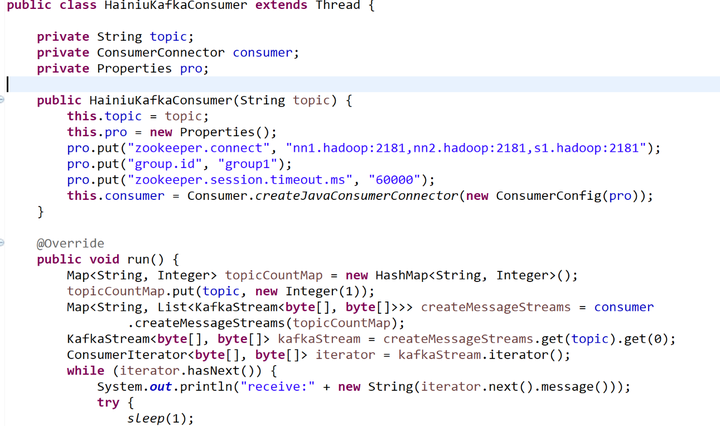
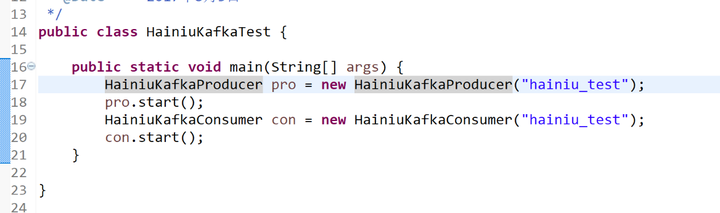
producer


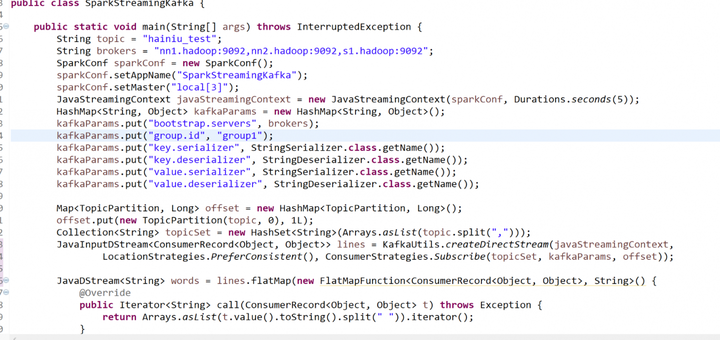
4.spark-streaming-kafka

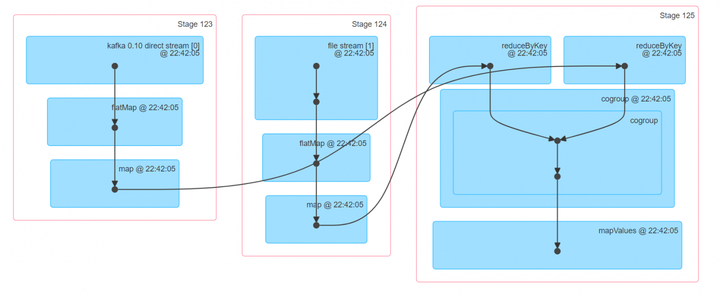
5.spark-streaming-kafka cogroup spark-streaming-file
import java.util.Arrays;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction2;
import org.apache.spark.serializer.KryoSerializer;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import scala.Tuple2;
/**
*/
public class SparkStreamingKafkaFileCogroup {
public static void main(String[] args) throws InterruptedException {
String topic = "hainiu_test";
String brokers = "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092";
final Class[] classes = new Class[] { LongWritable.class, Text.class };
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("SparkStreamingKafka");
sparkConf.setMaster("local[3]");
sparkConf.set("spark.streaming.fileStream.minRememberDuration", "2592000s");
sparkConf.set("spark.serialize", KryoSerializer.class.getName());
sparkConf.registerKryoClasses(classes);
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(5));
HashMap<String, Object> kafkaParams = new HashMap<String, Object>();
kafkaParams.put("bootstrap.servers", brokers);
kafkaParams.put("group.id", "group1");
kafkaParams.put("key.serializer", StringSerializer.class.getName());
kafkaParams.put("key.deserializer", StringDeserializer.class.getName());
kafkaParams.put("value.serializer", StringSerializer.class.getName());
kafkaParams.put("value.deserializer", StringDeserializer.class.getName());
Map<TopicPartition, Long> offset = new HashMap<TopicPartition, Long>();
offset.put(new TopicPartition(topic, 0), 1L);
Collection topicSet = new HashSet(Arrays.asList(topic.split(",")));
JavaInputDStream<ConsumerRecord<Object, Object>> lines = KafkaUtils.createDirectStream(javaStreamingContext,
LocationStrategies.PreferConsistent(), ConsumerStrategies.Subscribe(topicSet, kafkaParams, offset));
JavaDStream words = lines.flatMap(new FlatMapFunction<ConsumerRecord<Object, Object>, String>() {
@Override
public Iterator call(ConsumerRecord<Object, Object> t) throws Exception {
return Arrays.asList(t.value().toString().split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> mapToPair = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String, Integer>(t, 1);
}
});
JavaPairDStream<String, Integer> reduceByKey = mapToPair
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
String localPath = "C:/tmp/sparkstreamingfile1";
JavaPairInputDStream<LongWritable, Text> fileStream = javaStreamingContext.fileStream(localPath,
LongWritable.class, Text.class, TextInputFormat.class, new Function<Path, Boolean>() {
@Override
public Boolean call(Path v1) throws Exception {
return v1.getName().endsWith(".txt");
}
}, false);
JavaDStream flatMap = fileStream.flatMap(new FlatMapFunction<Tuple2<LongWritable, Text>, String>() {
@Override
public Iterator call(Tuple2<LongWritable, Text> t) throws Exception {
return Arrays.asList(t._2.toString().split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> mapToPairF = flatMap.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String, Integer>(t, 1);
}
});
JavaPairDStream<String, Integer> reduceByKeyF = mapToPairF
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
reduceByKeyF.cogroup(reduceByKey).foreachRDD(
new VoidFunction2<JavaPairRDD<String, Tuple2<Iterable, Iterable>>, Time>() {
@Override
public void call(JavaPairRDD<String, Tuple2<Iterable, Iterable>> v1, Time v2)
throws Exception {
System.out.println("time:" + v2 + "," + v1.collect());
}
});
javaStreamingContext.start();
javaStreamingContext.awaitTermination();
}
}
大家学习的怎么样,到这里给大家推荐大数据学习群:774--666--256欢迎大家加入学习,里面有学习路线,入门教程














 1198
1198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









