









问题
logstash消费速率远低于日志数量,消息堆积
部署背景
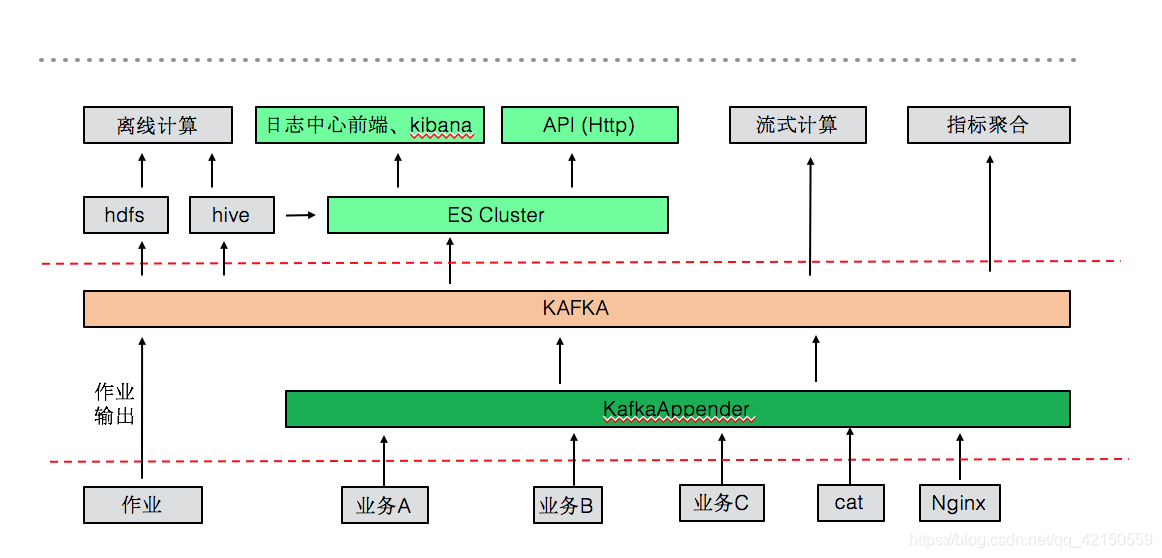
架构优点:
1、采用kafka作为日志缓冲,在高并发情况下可以通过队列就能起到削峰填谷的作用,防止 es 集群丢失数据。
2、实现动态schema,业务可以自定义schema,方便日志检索和查询
3、每一个业务有独立的索引
2.1 elk+kafka
发现问题
部署后发现日志量很大,一天有几个亿,kafka中堆积了很多消息,logstash消费不掉,增加logstash实例也收效甚微
1.怀疑是logstash的配置问题,导致消费太慢
2.es的效率是瓶颈
logstash配置
pipeline:
workers: 30
output.workers: 32
batch.size: 3000
batch.delay: 5
一下是input配置
inputs:
main: |-
input {
kafka {
type => "lx_service"
codec => "plain"
auto_offset_reset => "latest"
client_id => "logstash2es-consumer"
group_id => "logstash2es-consumer"
topics_pattern => ".*"
bootstrap_servers => "kafka.logcenter-cluster.svc:9092"
decorate_events => true
consumer_threads => 4
max_poll_records => "5000"
}
}
关键参数
pipeline.workers:64
总工作线程数,filter的速率主要取决于这个参数
pipeline.output.workers:32
output的线程数,不能高于worker线程数
pipeline.batch.size:1000
batch的总大小
pipeline.batch.delay:10
batch延迟的时间
consumer_threads => 4
消费者线程数,所有pod加起来的总数要尽量跟kafka的partition保持一致max_poll_records => “5000”
每次拉取的最大记录数queue.max_bytes: 4gblogstash队列最大保存大小。注:一定要比存储盘小
kafkaManager
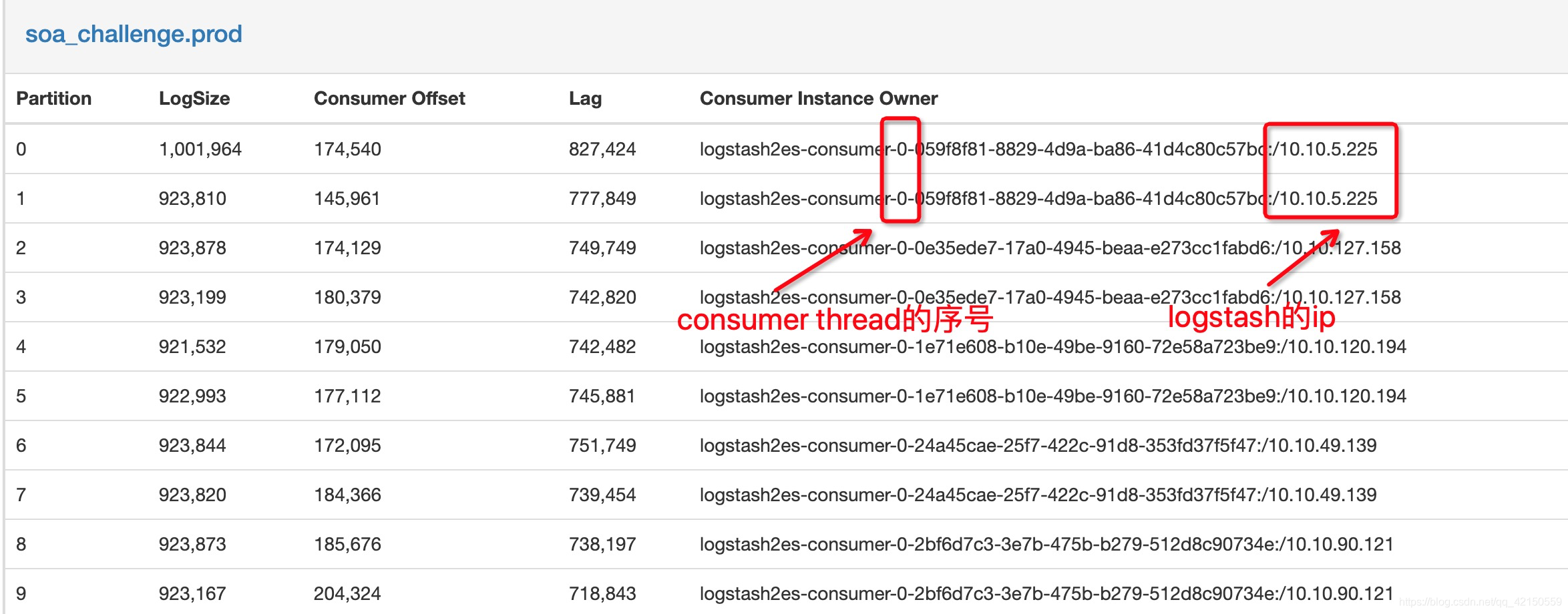
事例:
假设logstash配置30个pod,每个pod配置4个consumer thread,那么共计我们就有4*30=120个consumer。假设有200个partition,那么就有80个partition会和其他partition持有相同的consumer,这样就没有分配到最合理。
优化方案:
发布4*50个=consumer线程,每个partition对应一个consumer线程。
问题排查
1.查看pod状态
进入pod
exec -it xxx /bin/bash
使用top命令,观察cpuload
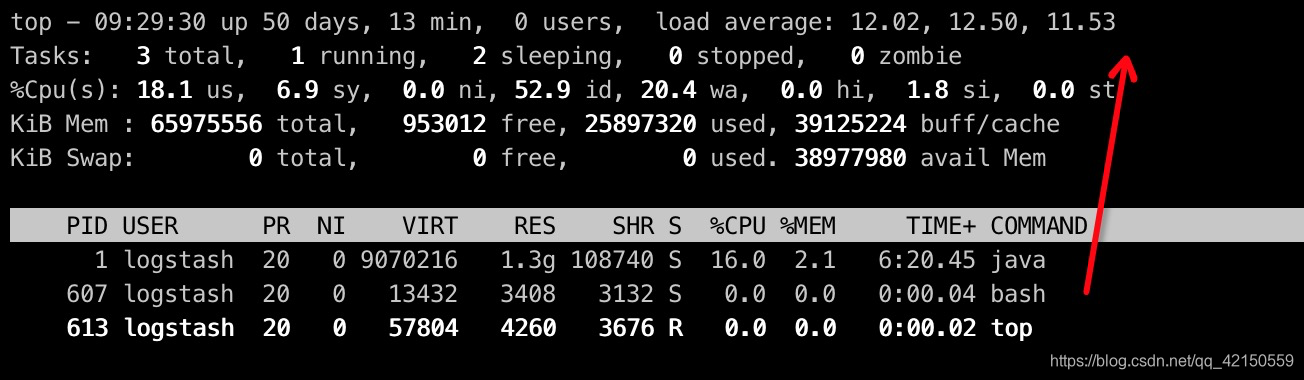
cpuload保持在核数左右,还是比较可行的,高了则可以减少worker数量
2.查看集群pod内存及cpu使用
注:logstash在发布时cpu会快速增长,启动后恢复正常
3.通过ES索引速率查看当前消费效果
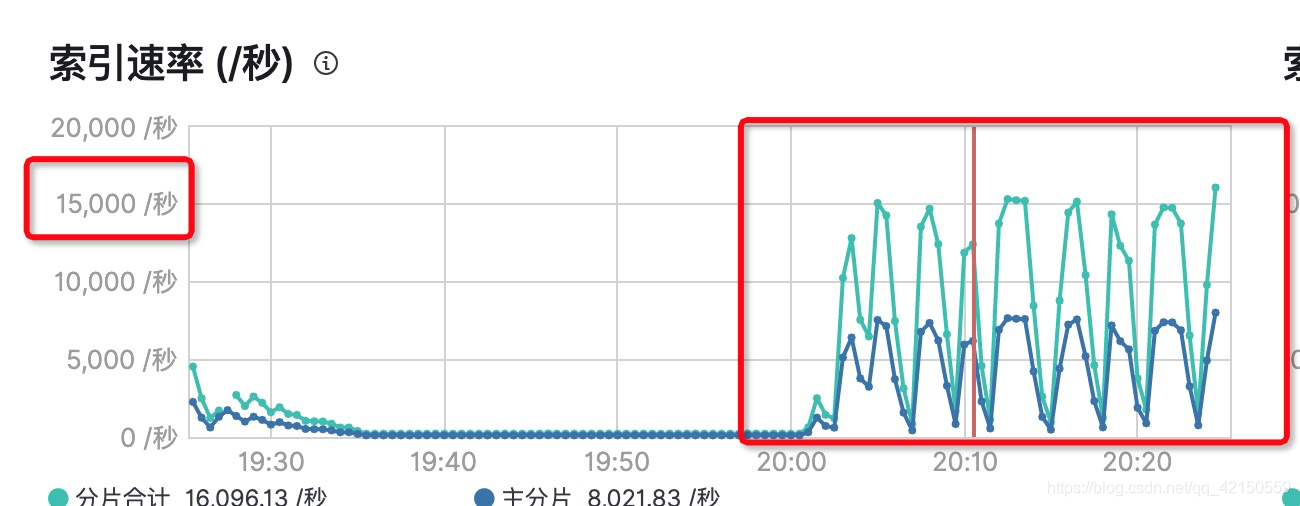
一万以下一定是有问题的
4.ES集群一直处于runing,没有可用
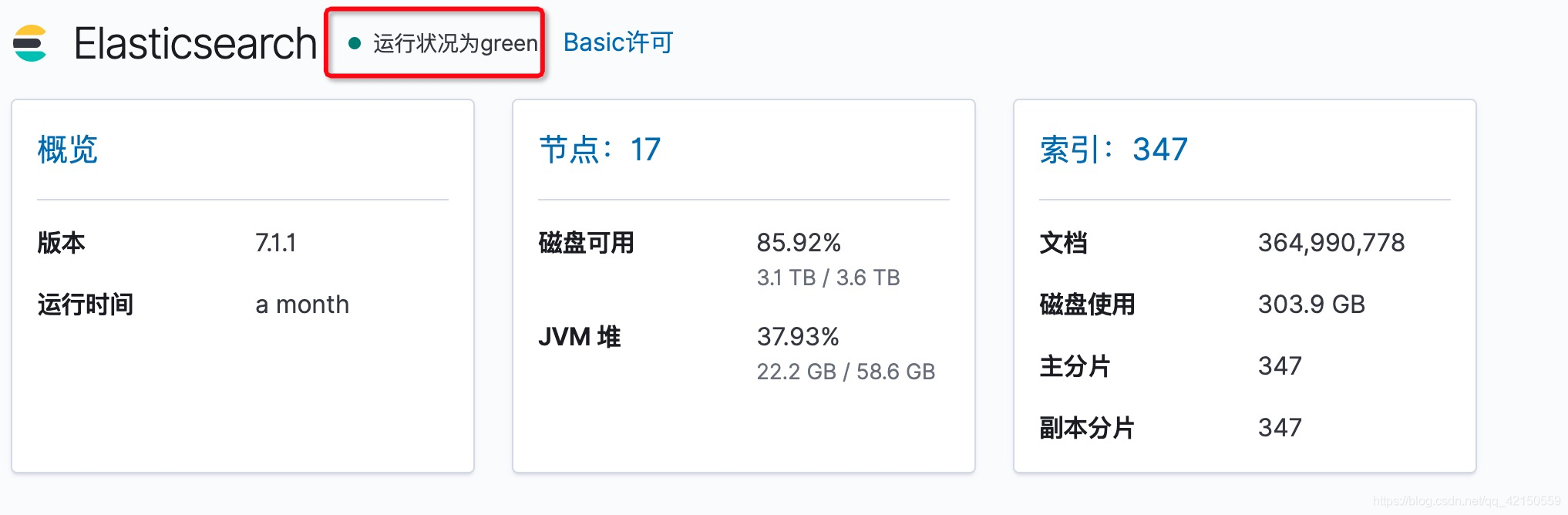 一般是状态没有达到green
一般是状态没有达到green
查看实际workers
top -H -p [pid进程号]
查看实际workers,一般等于核数
cpu load最好差不多等于核数

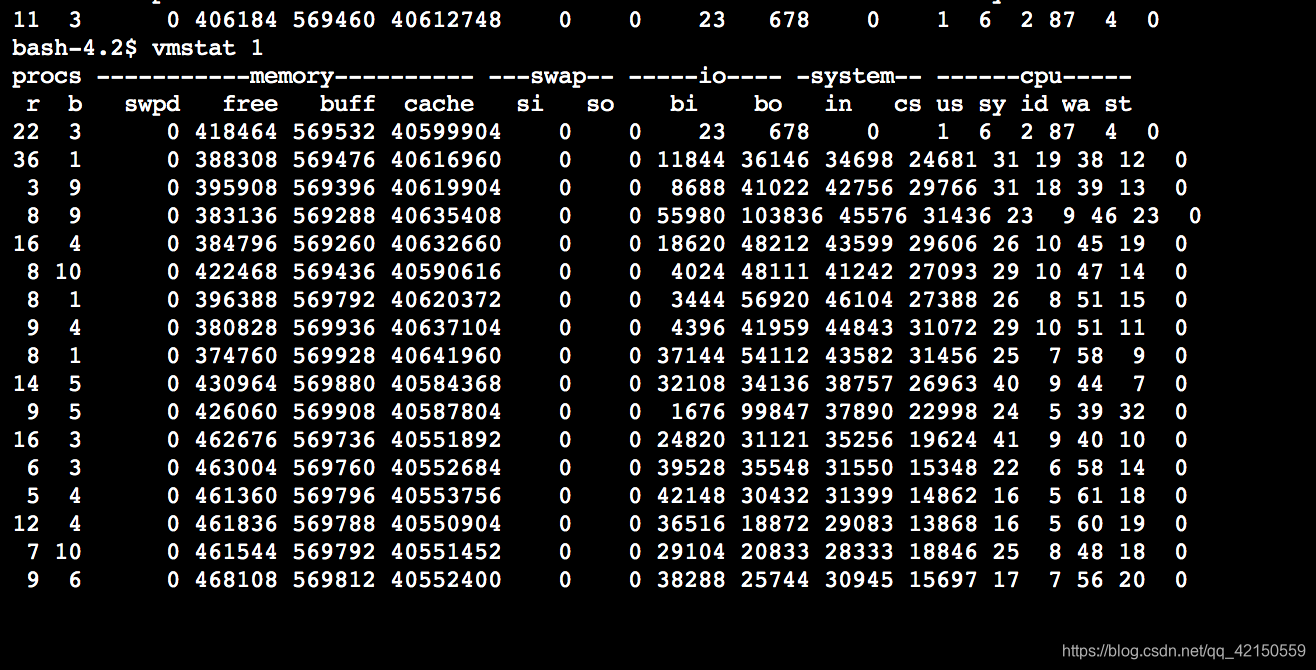
vmstat命令
查看bi和bo
看进入的io和输出io的量是否差不多
优化前
优化后
千万不要加的配置
queue.checkpoint.writes: 1
logstash的持久化策略,为1时随时持久化到磁盘,非常影响效率















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









