







一、 背景引入
在开发过程中,经常会遇到进入HardFault死循环的问题,主要原因如下:
- 数组越界操作
- 内存溢出,访问越界
- 堆栈溢出,程序跑飞
- 中断处理错误
针对出现HardFault问题,我们需根据内核对异常的响应处理流程分析,同时结合通过keil生成的map文件来查看程序互相依赖,内存大小,程序大小等信息来判断。
二、基础知识
1. CortexM3内核
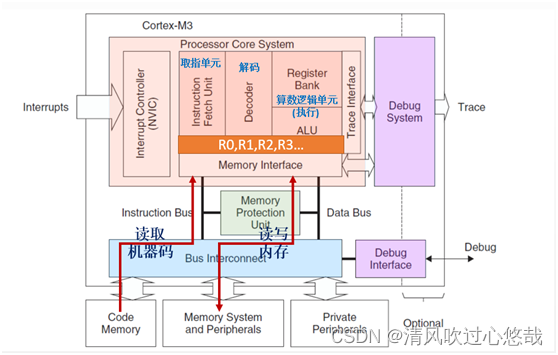
2. 寄存器组
Cortex‐M3 处理器拥有 R0‐R15 的寄存器组。其中 R13 作为堆栈指针 SP。 SP有两个,但在同一时刻只能有一个可以看到,这也就是所谓的“banked”寄存器。
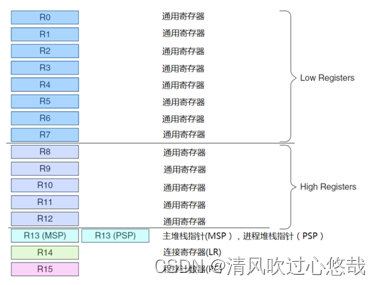
●R0-R12:通用寄存器
R0‐R12 都是 32 位通用寄存器,用于数据操作。但是注意:绝大多数 16 位 Thumb指令只能访问 R0‐R7,而 32 位 Thumb‐2 指令可以访问所有寄存器。
●Banked R13: 两个堆栈指针
Cortex‐M3 拥有两个堆栈指针,然而它们是 banked,因此任一时刻只能使用其中的一个。
主堆栈指针(MSP),或写作 SP_main。这是缺省的堆栈指针,它由 OS 内核、异常服务例程以及所有需要特权访问的应用程序代码来使用。
进程堆栈指针(PSP),或写作 SP_process。用于常规的应用程序代码(不处于异常服务例程中时)。
为了在进行模式转换的时候,减少堆栈的保存工作。同时也可以为不同权限的工作模式设置不同的堆栈。
●R14寄存器是链接寄存器(LR),当呼叫一个子程序时,由R14存储返回地址。
●R15寄存器是程序寄存器(PC),指向程序当前的地址。如果修改它的值,就能改变程序的执行流。
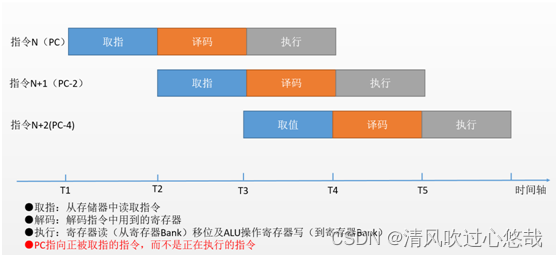
3. 三级流水线
CortexM3架构采用三级流水线的方式实现指令的操作。流水线操作的本质是利用指令运行的不同阶段使用的CPU 硬件互不相同,并发的运行多条指令,从而提高时间效率。
三级流水线操作并行运行指令的方式: 在对第1条指令进行译码的时候,可以同时对第2条指令进行取指操作;在对第1条指令进行执行的时候,可以同时对第2条指令进行译码操作,对第3条指令进行取指操作。显然,这样就可以将该程序的运行总时间从30秒缩减为12秒,提速近3倍。
4. 异常
Cortex‐M3 在内核水平上搭载了一个异常响应系统, 支持为数众多的系统异常和外部中
断。其中,编号为 1-15 的对应系统异常,大于等于 16 的则全是外部中断。除了个别异常的优先级被定死外, 其它异常的优先级都是可编程的(所有能打断正常执行流的事件都称为异常)。
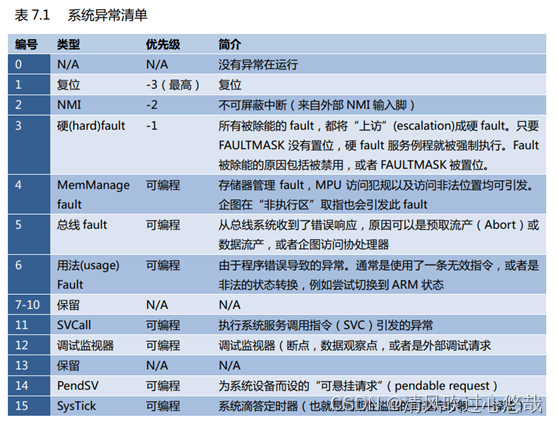
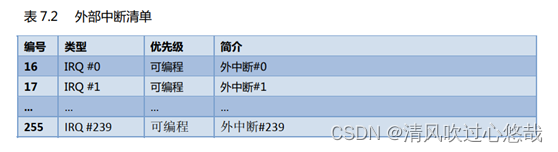
在 CM3 中,优先级的数值越小,则优先级越高。CM3 支持中断嵌套,使得高优先级异常会抢占(preempt)低优先级异常。有 3 个系统异常:复位, NMI 以及硬 fault,它们有固定的优先级,并且它们的优先级号是负数,从而高于所有其它异常。所有其它异常的优先级则都是可编程的(但不能编程为负数)。
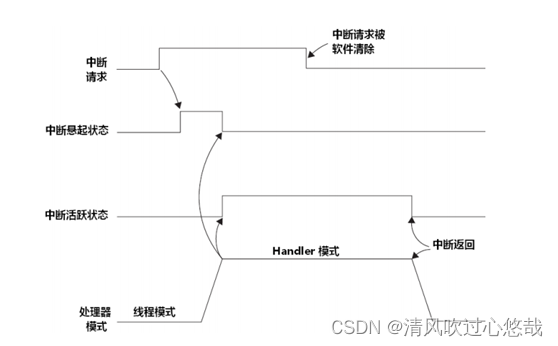
中断的输入及悬起行为
当某中断的服务例程开始执行时,就称此中断进入了“活跃”状态,并且其悬起位会被硬件自动清除,在一个中断活跃后,直到其服务例程执行完毕,并且返回了,才能对该中断的新请求予以响应。
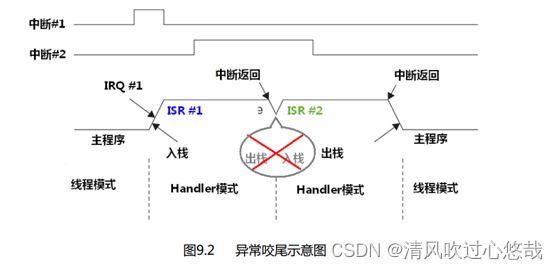
咬尾中断
当前正在执行中断,又有一个中断到来且这个中断优先级比正在执行的中断优先级低,这个中断暂时被挂起,等到当前中断执行完后不再执行堆栈操作,而直接进入挂起的中断,不需要再进行出栈入栈操作。















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









