







目录
一、简介
使用crc16作为hash函数;
使用拉链法解决hash冲突;
简单的hash表;
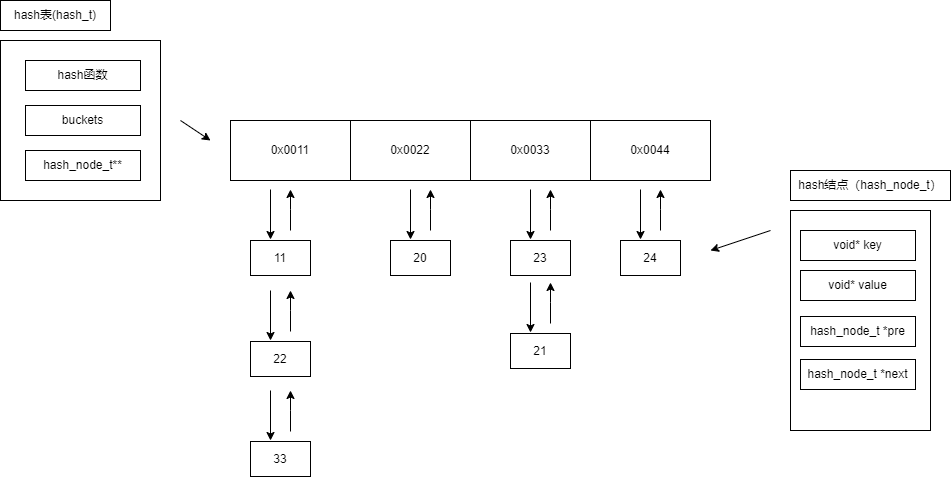
二、hash表结构图
三、结构定义
1.hash函数:定义hash函数类型为接收void*类型和内存长度为参数的函数,返回整数。这里具体使用crc16作为hash函数的实现。
typedef uint16_t (*hash_func_t)(void *, int);
uint16_t myhash(void *key, int len)
{
return crc16((const char *)key, len);
}
2.hash结点结构:结点内自然要保留key,value。因为可以存任意类型的内存数据,所以使用void*。又因为使用的拉链法解决冲突,使用双向链表。使用双向链表的另外一个好处是方便删除。
typedef struct hash_node
{
void *key;
void *value;
struct hash_node *pre;
struct hash_node *next;
} hash_node_t;
3.hash表结构:buckets是桶的大小;hash_func 为hash函数;nodes 为桶数组,是一个指针数组。
typedef struct hash
{
int buckets;
hash_func_t hash_func;
hash_node_t **nodes;
} hash_t;四、成员函数
初始化
可以看出,hash表的桶子树是固定的。当元素越多,hash表的负载因子越高,性能就越低 :(。
hash_t *hash_init(int buckets)
{
if (buckets < 1)
{
printf("buckets must greater than 0");
return NULL;
}
hash_t *hash = (hash_t *)malloc(sizeof(hash_t));
hash->buckets = buckets;
hash->hash_func = myhash;
hash->nodes = (hash_node_t **)malloc(sizeof(hash_node_t *) * buckets);
return hash;
}销毁
void hash_destory(hash_t **hash)
{
if (*hash == NULL)
{
return;
}
free((*hash)->nodes);
free((*hash));
*hash = NULL;
}辅助函数
根据key找桶,该函数为基础函数,所有地方都用得着。
//辅助函数,根据key找桶
hash_node_t **key_to_bucket(const hash_t *hash, void *key, int len)
{
uint16_t tmp = hash->hash_func(key, len);
return &(hash->nodes[tmp % hash->buckets]);
}辅助函数
根据key找结点,该函数在hash表的添加、删除、查找等操作都会被使用。
//辅助函数,找结点
hash_node_t *key_to_node(const hash_t *hash, void *key, int key_len)
{
hash_node_t **bucket = key_to_bucket(hash, key, key_len);
hash_node_t *node = *bucket;
while (node != NULL && memcmp(node->key, key, key_len) != 0)
{
node = node->next;
}
return node;
}添加
- 首先查找key是否存在,如果存在,则覆盖value。
- 如果key不存在,需要判断key所属桶是否为空,然后特殊处理。
void hash_add(hash_t *hash, void *key, int key_len, void *value, int value_len)
{
hash_node_t *node = key_to_node(hash, key, key_len);
if (node != NULL)
{
if (node->value != NULL)
{
free(node->value);
}
node->value = malloc(value_len);
memcpy(node->value, value, value_len);
return;
}
node = (hash_node_t *)malloc(sizeof(hash_node_t));
node->key = malloc(key_len);
memcpy(node->key, key, key_len);
node->value = malloc(value_len);
memcpy(node->value, value, value_len);
node->next = NULL;
node->pre = NULL;
hash_node_t **bucket = key_to_bucket(hash, key, key_len);
if (*bucket == NULL)
{
*bucket = node;
}
else
{
hash_node_t *p = *bucket;
(*bucket) = node;
node->next = p;
p->pre = node;
}
}删除结点
- 如果结点不在hash表中,则直接返回。
- 如果结点在hash表中,需要判断结点是不是hash表的第一个结点,然后特殊处理。
bool hash_del(hash_t *hash, void *key, int key_len)
{
hash_node_t *node = key_to_node(hash, key, key_len);
if (node == NULL)
{
return false;
}
hash_node_t **bucket = key_to_bucket(hash, key, key_len);
if (*bucket == node)
{
*bucket = node->next;
if (node->next != NULL)
{
node->next->pre = NULL;
}
free(node);
}
else
{
node->pre->next = node->next;
if (node->next != NULL)
{
node->next->pre = node->pre;
}
free(node);
}
return true;
}查找
bool hash_exist(const hash_t *hash, void *key, int key_len)
{
hash_node_t *node = key_to_node(hash, key, key_len);
return node == NULL;
}
void *hash_find(const hash_t *hash, void *key, int key_len)
{
hash_node_t *node = key_to_node(hash, key, key_len);
return node == NULL ? NULL : node->value;
}打印函数
void hash_print(const hash_t *hash)
{
printf("------------hash start-------------------\n");
for (int i = 0; i < hash->buckets; i++)
{
printf("bucket %d:", i);
hash_node_t *node = hash->nodes[i];
while (node)
{
printf(" %s", (char *)node->key);
node = node->next;
}
printf("\n");
}
printf("------------hash end-------------------\n");
}测试
void test06()
{
hash_t *hash = hash_init(2);
if (hash == NULL)
{
printf("hash init faied!\n");
}
for (int i = 1; i <= 1000; i++)
{
char buf[1024] = {0};
sprintf(buf, "k%d", i);
hash_add(hash, buf, strlen(buf), "v", 2);
}
hash_print(hash);
hash_destory(&hash);
}














 7260
7260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









