







一级缓存
Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。所以在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。

为什么要使用一级缓存,不用多说也知道个大概。但是还有几个问题我们要注意一下。
1、一级缓存的生命周期有多长?
a、MyBatis在开启一个数据库会话时,会 创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象。Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
b、如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
c、如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
d、SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用
2、怎么判断某两次查询是完全相同的查询?
mybatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询。
2.1 传入的statementId
2.2 查询时要求的结果集中的结果范围
2.3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
2.4 传递给java.sql.Statement要设置的参数值
二级缓存:
MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
MyBatis的缓存机制整体设计以及二级缓存的工作模式

SqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开席需要进行配置,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。 也就是要求实现Serializable接口,配置方法很简单,只需要在映射XML文件配置就可以开启缓存了<cache/>,如果我们配置了二级缓存就意味着:
- 映射语句文件中的所有select语句将会被缓存。
- 映射语句文件中的所欲insert、update和delete语句会刷新缓存。
- 缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
- 根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
- 缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
实践:
创建一个POJO Bean并序列化
由于二级缓存的数据不一定都是存储到内存中,它的存储介质多种多样,所以需要给缓存的对象执行序列化。(如果存储在内存中的话,实测不序列化也可以的。)
在 mybatis-config.xml中开启二级缓存
复制代码
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--这个配置使全局的映射器(二级缓存)启用或禁用缓存-->
<setting name="cacheEnabled" value="true" />
.....
</settings>
....
</configuration>Mapper配置
哪个mapper用在哪个mapper配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "http://mybatis.org/dtd/mybatis-3-mapper.dtd" "mybatis-3-mapper.dtd" >
<mapper namespace="com.baizhi.zcn.dao.BookDao" >
<!--开启本mapper的namespace下的二级缓存-->
<!--
eviction:代表的是缓存回收策略,目前MyBatis提供以下策略。
(1) LRU,最近最少使用的,一处最长时间不用的对象
(2) FIFO,先进先出,按对象进入缓存的顺序来移除他们
(3) SOFT,软引用,移除基于垃圾回收器状态和软引用规则的对象
(4) WEAK,弱引用,更积极的移除基于垃圾收集器状态和弱引用规则的对象。这里采用的是LRU,
移除最长时间不用的对形象
flushInterval:刷新间隔时间,单位为毫秒,这里配置的是100秒刷新,如果你不配置它,那么当
SQL被执行的时候才会去刷新缓存。
size:引用数目,一个正整数,代表缓存最多可以存储多少个对象,不宜设置过大。设置过大会导致内存溢出。
这里配置的是1024个对象
readOnly:只读,意味着缓存数据只能读取而不能修改,这样设置的好处是我们可以快速读取缓存,缺点是我们没有
办法修改缓存,他的默认值是false,不允许我们修改
-->
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024"/>
...
</mapper>注意:实体类要实现序列化接口
implements Serializable
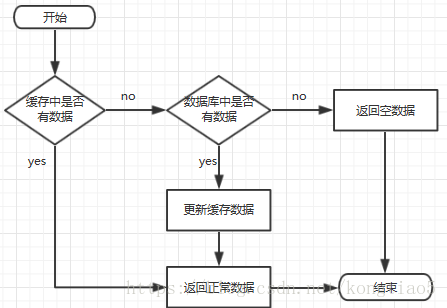
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
二、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
三、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
设置热点数据永远不过期。
加互斥锁,互斥锁
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
四、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。















 576
576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









