







一、实验目标
熟悉 Linux 操作系统,在 Linux 中使用 C 语言进行文本处理。完成下面两个问题:
(1)使用 C 语言编写一个词频(限英文文章)统计程序,使之能够给出各个单 词在输入文件中的出现次数。
(2)使用 C 语言编写一个反向打印程序,使之能够按与输入文件中文本行相反 的次序来打印(即后出现的文本行先打印)。
二、实验准备
由于Linux操作系统此前从未使用过,根本不熟悉它的使用方法,加上实验过程中还要用到C语言这门不熟悉的语言,所以这次实验的准备时间很长。
首先,我去Ubuntu的官网上下载了最新发布的Ubuntu18.04.4,对于装虚拟机还是双系统,我一开始还不太确定,因为虚拟机只能分配2G的内存,使用的时候可能会卡顿,但是装双系统的话对于我这种新手来说也不太方便,也不太需要,最终决定装虚拟机,因为我觉得虚拟机足够满足实验的需要了。
于是,我去VMware Workstation的官网下载了pro版的,又从网上找了注册码,顺利的安装好了VMware。接着我在VMware里创建了一个Ubuntu的虚拟机,安装完成后发现整个界面很小,缩在中间,于是我去上网查了一下,原来是没有安装VMware tools的缘故,这个工具有很大的用处,不仅可以让界面缩放自如,还可以实现宿主机和客户机之间文件的移动,这对后面做实验有很大的帮助,因为Ubuntu上装不了QQ、微信等聊天工具,如果要接收群文件,可能比较麻烦。这样一来,一举两得。
对于Linux操作系统,之前只是略有耳闻,是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的类Unix操作系统,它与Windows相比的一大区别是,需要大量的使用命令行来管理文件或进行其他操作。而对于我这样一个新手来说短时间内熟练掌握各种操作命令是不太可能的,于是我去网上查看了一些Linux系统的新手操作教程,菜鸟教程里的Linux教程我觉得很好,它的内容深入浅出,新手看也不吃力。
三、实验预习
根据本次实验的内容,我主要学习了Linux的系统目录结构、文件与目录管理、用户与用户组管理以及文本编辑器vim的使用等几块知识。 粗略了解了Linux系统的树状目录结构,以及对每个目录的解释,知道了一些处理目录的常用的命令,如ls、cd、pwd等。
由于这次实验与用户和用户组的知识有关,而且以前用Windows系统时对于用户的概念不是很明确,所以我重点学习了一下这一块的知识。学完之后我大致了解了,Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。而每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。
此外,我还通过菜鸟教程、C Primer Plus电子书等途径简单的学习了一下C语言。由于很多操作系统的底层代码都是用C语言来写的,所以熟练掌握C语言对理解操作系统是如何运行的有很大的帮助。在学习的过程中我发现C语言与我曾经学过的C++还是有很多的不同之处的。比如在C语言中,输入输出是使用语句scanf()和printf()来实现的,而C++中是使用类来实现的。关于函数重载,在C++中,允许有相同的函数名,不过它们的参数类型不能完全相同,这样这些函数就可以相互区别开来。而这在C语言中是不允许的。诸如此类还有很多不一样,所以在今后写C语言的时候,需要额外注意与C++的区别。
四、实验思路
1、根据实验步骤1,熟悉Linux用户和用户组的相关操作。
2、在/usr目录下创建自己的目录,利用文本编辑器,编辑、编译、运行示例C代码。
3、实验目标一:使用 C 语言编写一个词频(限英文文章)统计程序,使之能够给出各个单词在输入文件中的出现次数。
(1)由于不确定文章中单词的数量,所以考虑用链表形式来存储单词,为了统计每个单词的频率,于是设计一个结构体来存储每个单词,结构体中包含每个单词的值,频率以及指向下一个元素的指针。
(2)用读文件操作每读入一个单词,搜索链表看是否存在,若存在则频率+1,否则在链表尾部新增一个元素,记录这个单词。
(3)对统计完的链表从头到尾扫描,格式化输出相应的单词及词频。
4、实验目标二:使用 C 语言编写一个反向打印程序,使之能够按与输入文件中文本行相反 的次序来打印(即后出现的文本行先打印)
(1)此题与上题异曲同工。结构体中存储的是一行字符串而非单词,而且不需要统计频率。
(2)用读文件操作读每一个句子,但存放的顺序是反向的,每次都加在链表的开头。
(3)对链表从头到尾扫描,输出相应的每一行。
五、操作方法和实验步骤
Ⅰ 完成Linux操作系统用户组、用户注册号的创建,删除和修改操作
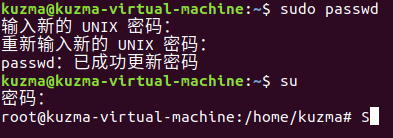
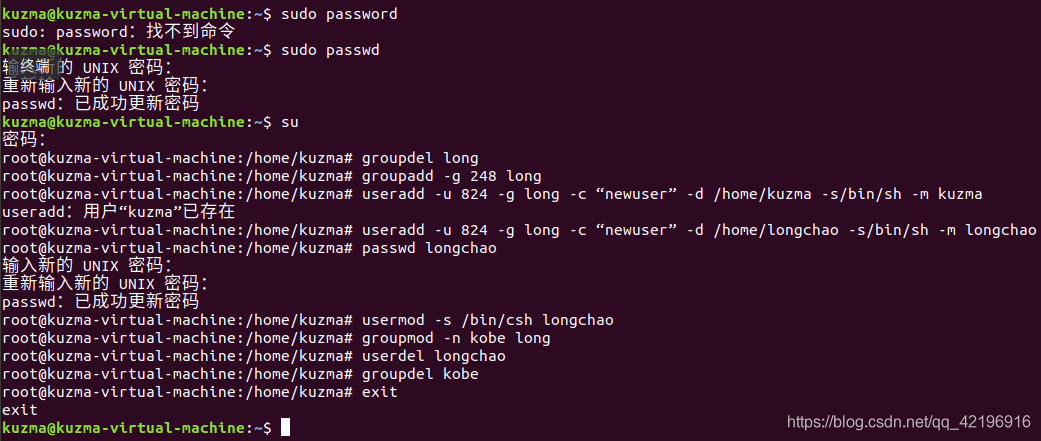
由于root有超级管理员的权限,所以进入root模式操作更为方便,但首先要设置一下root的密码。在Ubuntu终端输入sudo passwd指令来修改root密码:
1、通过 shell 命令创建用户组,创建用户组的 shell 命令格式如下:groupadd -g 248 long
![]()
2、为用户分配注册号,shell命令格式如下:
useradd -u 824 -g long -c “newuser” -d /home/longchao -s/bin/sh -m longchao

3、为用户设置口令,shell命令格式如下:passwd longchao

4、修改用户属性,shell命令格式如下:usermod -s/bin/csh longchao
![]()
5、修改用户组属性,shell命令格式如下:groupmod -n kobe long
![]()
6、只删除用户注册号,shell命令格式如下:userdel longchao
![]()
7、删除用户组,shell命令格式如下:groupdel kobe
![]()
8、退出root

Ⅱ 编辑c程序,并编译和执行它
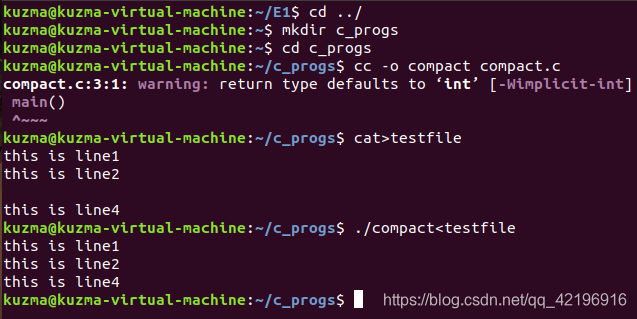
1、使用 mkdir 命令创建新的子目录 c_progs:$ mkdir c_progs
![]()
2、使用 cd 命令进入到新创建的子目录中: $cd c_progs
![]()
3、输入C程序compact.c,保存到当前用户的用户目录下,即home/kuzma
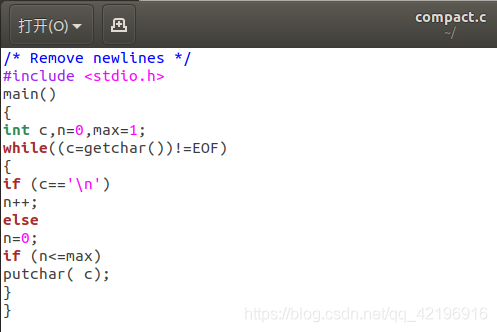
4、编译C程序

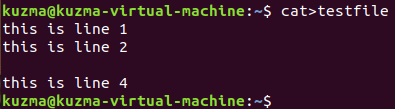
5、创建测试文件testfile
6、执行C程序,对testfile文件使用compact
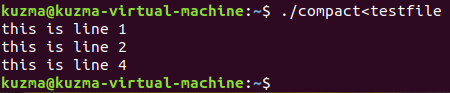
这样就从输入文件中删除了多余的空行。
III 使用 C 语言编写一个词频(限英文文章)统计程序,使之能够给出各个单词在输入文件中的出现次数。
1、使用mkdir命令创建新的子目录:E1
2、使用cd命令进入到新创建的子目录中

3、编辑输入c程序WordFrequency.c,程序主要设计思路如下:
- 由于本程序的目的是统计词频,而我事先并不知道到底有多少词,所以如果用数组来实现的话不太方便,因为一般来说数组必须要分配指定的大小,因此考虑使用链表的结构来实现,链表的每个元素是一个结构体,存放单词本身及其频率。
- 所以我定义了一个WordFrequency的结构体,成员包含单词名字name、词频frequency以及指向下一个结构体的指针。
- 因为我是用fscanf来读取文本,遇到空格或\n就会停止,所以读出来的单词经常会带有跟在后面的标点符号,所以我定义了一个函数normalize来处理使其去掉标点符号。
- 程序整体思路如下:每次读入一个单词,然后去掉标点符号,存在buff里,然后从链表头部向后搜索,如果单词出现过了,则相对应的词频加一,若搜到结尾仍然没出现过,则新建一个wf结构体存当前单词,词频置1,并且next指向head,再把head重新指向当前头部。最后从头部开始向后扫描依次输出相应信息。
【程序代码见源代码文件】
#include <stdio.h>
#include <cerrno>
#include <string.h>
#include <corecrt_malloc.h>
typedef struct WordFrequency
{
char name[26];
int frequency;
struct WordFrequency* next;
}wf;
void normalize(char ch[])
{
char symbol[] = ",.;:'?!><+=|*&^%$#@\"-";
for (int i = 0; i < strlen(ch); i++)
{
if (ch[i] >= 'A' && ch[i] <= 'Z')
{
ch[i] += 32;
}
if (ch[i] == ',' || ch[i] == '.' || ch[i] == ':' || ch[i] == '-' || ch[i] == ';')
{
ch[i] = ch[i + 1];
}
}
}
wf* search(wf* head, FILE* fp)
{
char buff[255];
while (fscanf(fp, "%s", buff) != EOF)
{
normalize(buff);
if (head == NULL)
{
head = (wf*)malloc(sizeof(wf));
strcpy(head->name, buff);
head->frequency = 1;
head->next = NULL;
}
else
{
wf* now = head;
while (now != NULL)
{
if (strcmp(now->name, buff) == 0)
{
now->frequency += 1;
break;
}
now = now->next;
}
if (now == NULL)
{
now = (wf*)malloc(sizeof(wf));
strcpy(now->name, buff);
now->frequency = 1;
now->next = head;
head = now;
}
}
memset(buff, 0, 255);
}
return head;
}
int main()
{
wf* head = NULL;
FILE* fp = NULL;
int errnum;
fp = fopen("article.txt", "r");
if (fp == NULL)
{
errnum = errno;
fprintf(stderr, "错误号:%d\n", errnum);
fprintf(stderr, "打开文件错误:%s\n", strerror(errnum));
}
else
{
wf* start = search(head, fp);
while (start != NULL)
{
printf("word:%s\t\tfrequency:%d\n", start->name, start->frequency);
start = start->next;
}
}
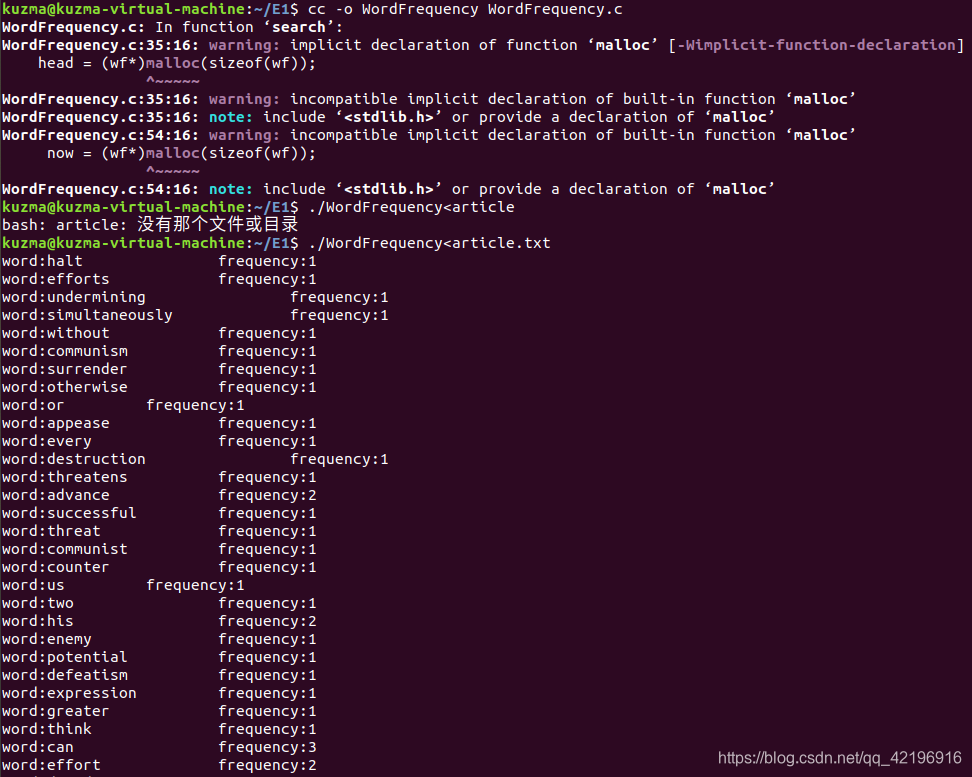
}4、使用命令 cc -o WordFrequency WordFrequency.c 编译c程序
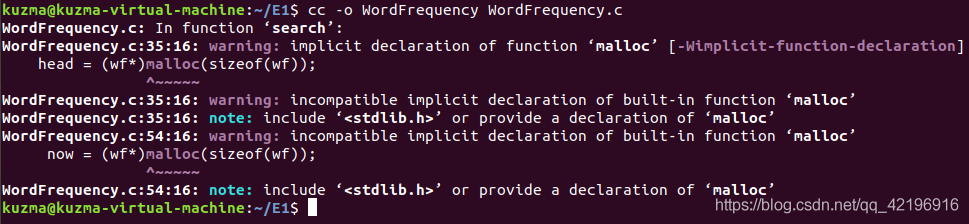
5、创建测试文件article
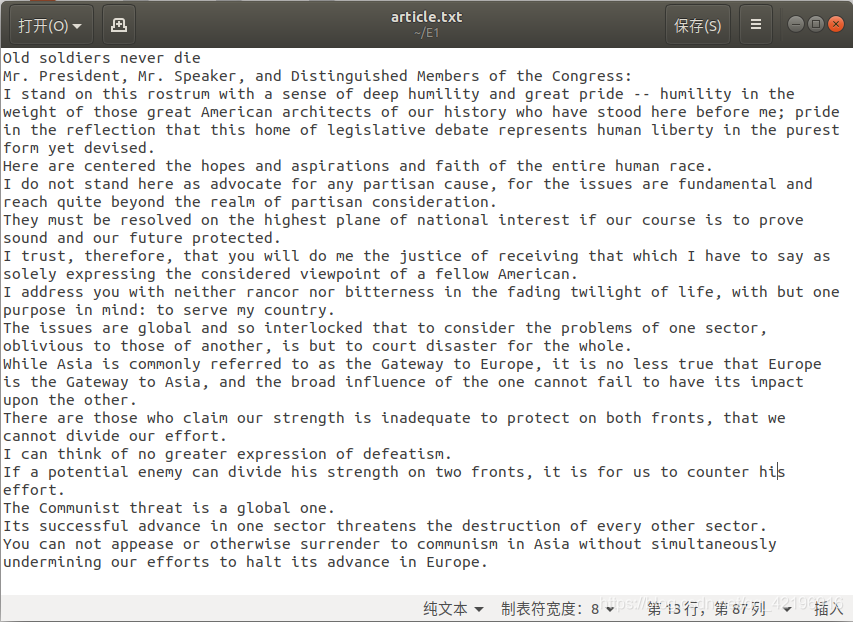
article 文件中的内容为:
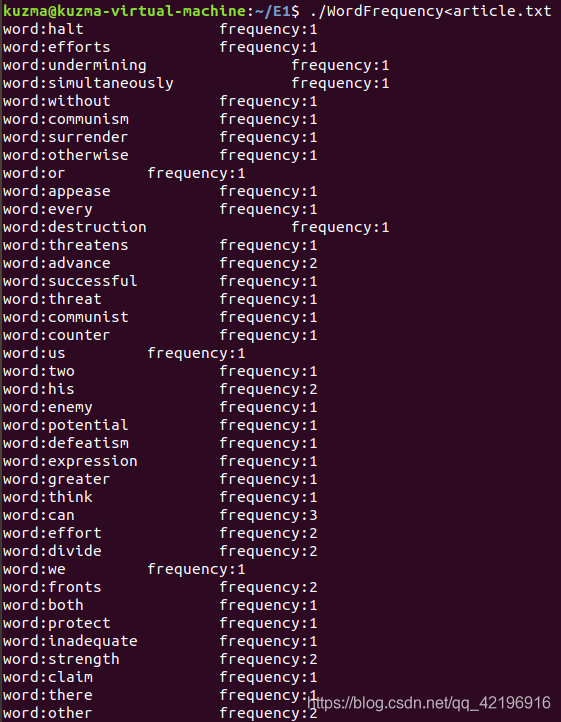
6、执行C程序运行结果(部分)
IV 使用 C 语言编写一个反向打印程序,使之能够按与输入文件中文本行相反的次序来打印(即后出现的文本行先打印。
1、使用cd命令进入到子目录 E1 中。
2、编辑输入c程序ReversePrint.c,程序主要设计思路如下:
- 由于不知道文本中有多少文本行,所以考虑用链表来实现,链表里的每个元素存放当前文本行,以及指向下一节点的next指针。
- 用fgets函数从文件中每次读取一行,存到结构体中,每次读到新的一行,都将其连接在链表的头部。
- 从链表头开始依次向后扫描并输出对应的文本行,即可实现反向打印。
【程序代码见源代码文件】
#include <stdio.h>
#include <cerrno>
#include <string.h>
#include <corecrt_malloc.h>
typedef struct line
{
char sentence[1255];
struct line* next;
}ln;
ln* search(ln* head, FILE* fp)
{
char buff[1255];
while (fgets(buff, 1255, fp) != NULL)
{
if (head == NULL)
{
ln* node = (ln*)malloc(sizeof(ln));
strcpy(node->sentence, buff);
head = node;
head->next = NULL;
}
else
{
ln* now = (ln*)malloc(sizeof(ln));
strcpy(now->sentence, buff);
now->next = head;
head = now;
}
memset(buff, 0, 1255);
}
return head;
}
int main()
{
ln* head = NULL;
FILE* fp = NULL;
int errnum;
fp = fopen("article.txt", "r");
if (fp == NULL)
{
errnum = errno;
fprintf(stderr, "错误号:%d\n", errnum);
fprintf(stderr, "打开文件错误:%s\n", strerror(errnum));
}
else
{
ln* start = search(head, fp);
while (start != NULL)
{
printf("%s", start->sentence);
start = start->next;
}
}
}
3、使用命令 cc -o ReversePrint ReversePrint.c 编译c程序
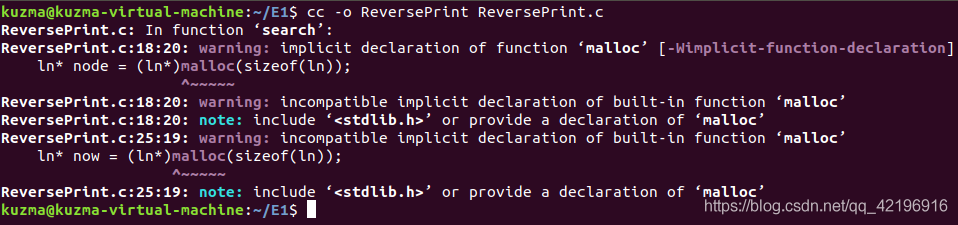
4、执行C程序(用前面已经创建的article.txt)
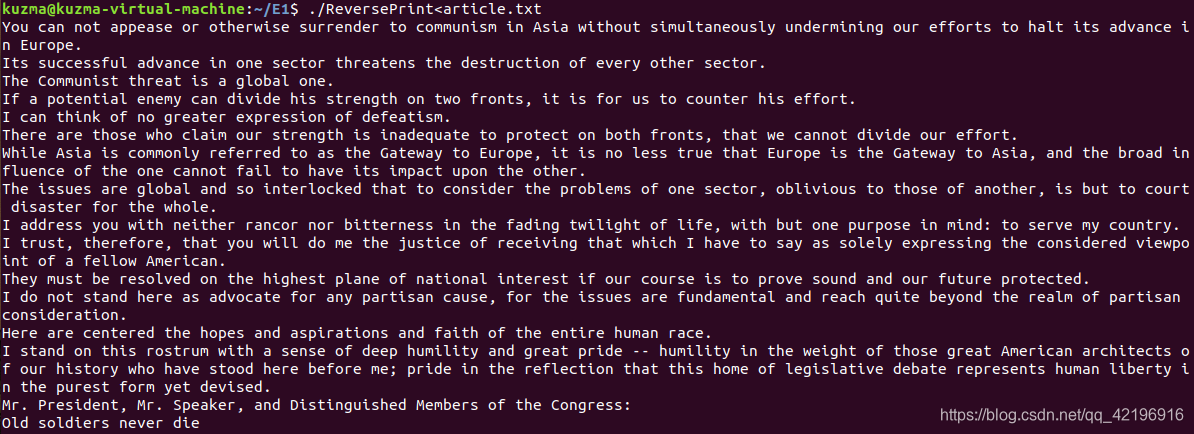
- 实验结果和分析
Ⅰ 完成Linux操作系统用户组、用户注册号的创建,删除和修改操作
实验所有命令如下:
Ⅱ编辑compact.c程序,并编译和执行它
实验所有命令如下:
III 使用 C 语言编写一个词频(限英文文章)统计程序,使之能够给出各个单词在输入文件中的出现次数。
实验所有命令结果如下:(词频统计结果由于较长,不便贴出,仅贴出部分以供参考)
程序流程图如图所示:
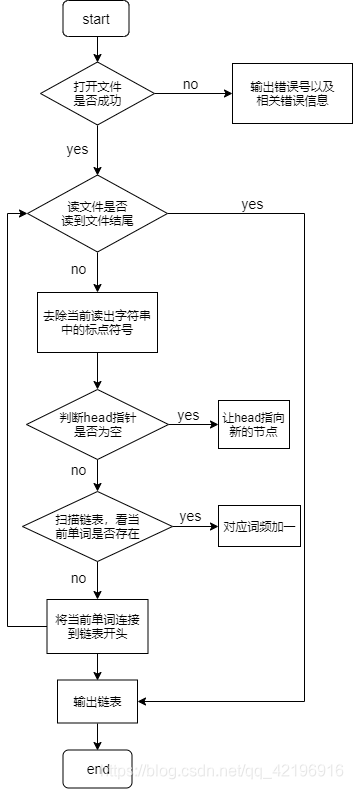
IV 使用 C 语言编写一个反向打印程序,使之能够按与输入文件中文本行相反的次序来打印(即后出现的文本行先打印。
实验所有命令过程及结果如下:

程序流程图如图所示:
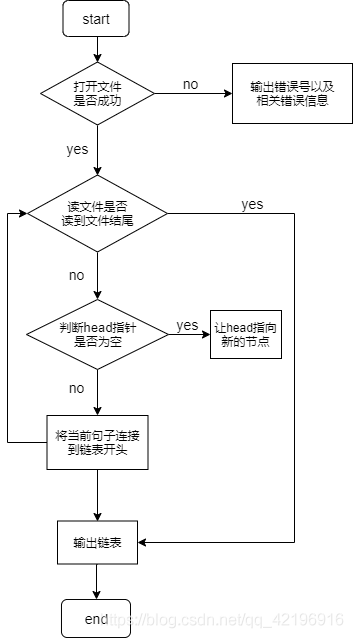














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









