









操作dataFrame一般有二种操作的方式, 一种为SQL方式, 另一种为DSL方式
SQL方式: 通过编写SQL语句完成统计分析操作
DSL方式: 领域特定语言 指的通过DF的特有API完成计算操作(通过代码形式)
从使用角度来说: SQL可能更加的方便一些, 当适应了DSL写法后, 你会发现DSL要比SQL更加好用(类似于面向过程编程)
Spark的官方角度: 推荐采用DSL方案
关于DSL相关的API:
-
show(参数1,参数2): 用于展示DF中的数据, 默认仅展示前20行
-
参数1: 设置默认展示多少行, 默认值为20
-
参数2: 是否为阶段列, 默认只输出20个字符的长度, 过长不显示, 要现实的话, 请填入: truncate=True
-
一般这两个参数很少会设置
-
-
printSchema(): 用于打印当前这个DF的表结构信息
-
select(): 类似于SQL语句中select, SQL中select后面可以写啥, 这里也同样可以实现
-
filter/where: 用于对数据进行过滤操作, 一般在Spark SQL中主要使用where
-
groupBy() 用于执行分组
-
orderBy() 用于执行排序
-
…….
注意:
Spark SQL的DSL API 都是非常简单的, 基本都与SQL的关键词保持一致, 一般大家认为DSL比较难的地方: 不知道如何传递参数,因为DSL API的参数变化多样, 每个函数支持的参数方式也不一样
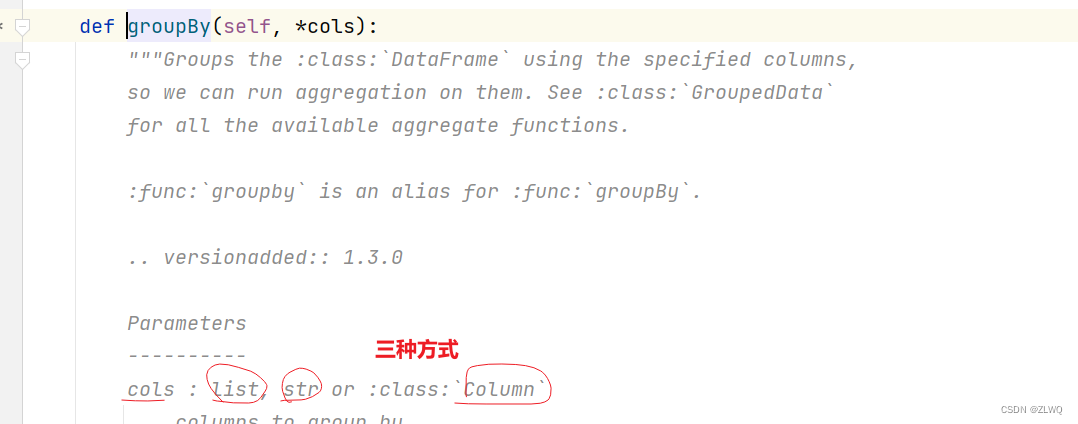
DSL主要支持以下几种传递的方式: 列表 | str | column
str格式: '字段'
column:
df对象中包含的字段: df['字段']
执行过程新产生字段: F.col('字段')
列表:
['字段1','字段2','字段3'...]
[column1,column2,column3...]
如何识别函数支持哪几种传递方式呢?


为了能够支持在编写DSL方案的时候, 支持在DSL中使用SQL函数, 专门提供了一个SQL函数库,直接加载使用即可
导入这个SQL函数库:
import pyspark.sql.functions as F
后续, 通过F 调用对应的函数即可, 而且Spark SQL所支持的函数, 都可以通过以下地址查询到:
https://spark.apache.org/docs/3.1.2/api/sql/index.html
关于SQL的操作方式:
- 如何创建一个表(视图):
df.createTempView('视图名称') # 创建一个临时的视图(表名) 常用
df.createOrReplaceTempView('视图名称') # 创建一个临时视图, 如果视图存在, 直接替换
df.createGlobalTempView('视图名称') # 注册一个全局视图, 运行在一个Spark应用中多个spark会话都是可以使用的, 在使用全局的视频的时候, 必须添加: global_temp.视图名称 才可以加载到
临时会话, 仅在当前这个spark session会话中使用
上述的创建视图的方式也可以通过SQL形式来创建:
create [template] view 视图名称 .....
create or replace [template] view 视图名称 ....
- 如何书写SQL语句:
spark.sql('sql语句')
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









