






这里记的是我这几次面试遇到的真题,包括一心堂,贝壳和友邦资讯科技.不是真题的其他技术点,我可能会面会补一点上去,让见到此文的朋友都有所收获,适用于面试突击来用,解答的不是很深入,祝大家都可以找到一份满意的工作
MQ
kafka快的原因
- 多分片并行处理
- 顺序写磁盘,末尾append方式(弊端,就是无法删除数据。对应的,kafka也不能删除数据,而是会将所有的数据都保存下来,然后根据配置的删除策略来删除磁盘上对应的文件)
- 充分利用 Page Cache
- 零拷贝
- producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗(它通过一次系统调用(sendfile 方法)合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。另外,拷贝数据都是发生在内核中的,天然就降低了数据拷贝的次数。)
- 批处理
- 数据压缩
- Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
消费积压怎么处理
原文参考: http://bjcp.itcast.cn/news/20230927/11022964321.shtml)
- 增加消费者
- 优化消费者端代码(如优化代码执行逻辑,比如使用多线程处理业务逻辑)
- 增加分区数
- 提高消费者的批次拉取数量
- 设置合理的offset提交策略
- 使用死信队列->如果消费者长时间无法处理消息,可以将无法处理的消息移动到死信队列以便后续处理。
- 限流策略:
如果消费者不能快速处理消息,可以实施流量控制策略,比如降低生产者的发送速率。
kafka怎么防丢失
原文:https://blog.csdn.net/jkwanga/article/details/124091823
producer的成功发送
Producer默认是异步发送消息,确保消息发送成功
-
第一种方法 把异步发送改为同步发送,这样就能实时知道消息发送的结果
-
第二种方法 添加异步或调函数,监听消息发送的结果,如果失败可以在回调中重试
-
第三种方法 Producer本身提供了一个retries的机制,如果因为网络问题,或者broker故障 导致发送失败,就是重试
Broker端 确保发送来的数据不丢失
- 消息持久化
- ack机制
acks=0 表示producer不需要等待broker的响应,就认为消息发送成功了(可能存在数据丢失)
acks=1 表示broker的leader和Partition收到消息之后 不等待其他的follower Partition的同步就给Producer发一个确认,假设leader和Partition
挂了(可能存在数据丢失)
acks=-1 表示broker的leader和Partition收到消息之后 并且等待 ISR列表中的follower同步完成,再给Producer返回一个确认(保证数据不丢失)
Consumer 必须要能够消费这个消息
除非Consumer没有消费完这个消息就提交了offset,这个我们可以重新调整offset的值
offset的提交方式和时机(比如选择自动提交或者手动同步提交,手动异步提交)
多线程
线程池参数和拒绝策略
当有界队列的线程池,队列满了,并且救急线程全部工作的情况下,再进入的请求会触发拒绝策略
- ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
- ThreadPoolExecutor.DiscardPolicy:丢弃任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新提交被拒绝的任务
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程(提交任务的线程)处理该任务
Cas的缺点
- CPU开销大;
- ABA问题;
- 只能保证一个共享变量原子操作。
ABA问题的解决方案
原子引用
AtomicReference<泛型>, 通过cas和volatile实现
什么是ABA?
在cas时, A线程准备修改初始值 A 从A—B,这个时候B线程先执行从A—B,然后C线程执行B–A的修改,这个时候A线程执行的时候,也能实现A-B的修改,因为A线程执行的时候,此时值也是A,也能cas成功,这就是ABA问题,即主线程能比较成功,但是无法感知有误其他线程修改这个值
怎么解决?
-
加版本号,可以知道修改过几次, 如果修改过 cas会失败
AtomicStampedReference
使用是先通过getreference获取当前值,再getStamp获取当前版本号, 比较交换时,需要传入当前版本号和新的版本号

-
通过bool感觉有没修改过,修改过则会cas失败
AtomicMarkbalReference

Synchronized的底层是用什么命令
原文参考: https://blog.csdn.net/sinat_42483341/article/details/108401916
基于moniter对象实现
- 字节码层面体现在
ACC_SYNCHRONIZED检查访问标准是否被设置,如果设置,利用monitorenter monitorexit指令实现线程同步,monitor监视器锁是由objectMonitor实现的,是基于C++来实现的, - OS层面或汇编指令
- 轻量级锁
lock cmpxchg - 重量级锁
Mutex Lock
- 轻量级锁
本质是依赖于底层操作系统的
Mutex Lock实现的
Synchronized实现原理及轻重锁定义
偏向锁:对象头和线程id实现,
轻量级: Cas,锁记录,对象头,底层通过 lock cmpxchg
重量级锁: JVM内部的ObjectMonitor监视器对象,底层 Mutex Lock
markword在32位系统中
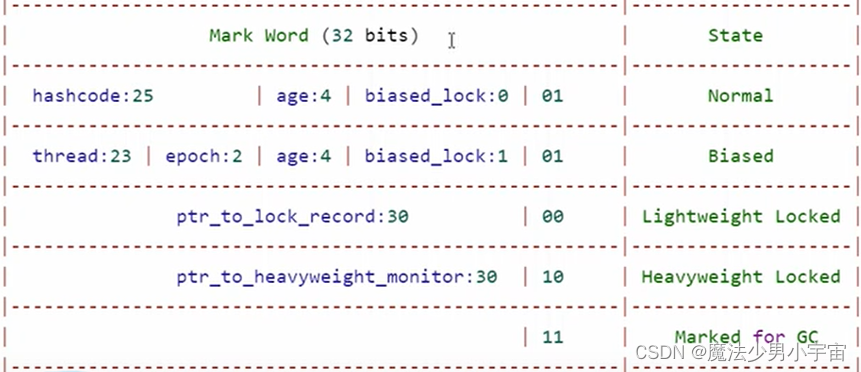
包含hashcode(25位)和分代年龄(1位)及偏向状态(1位)和是否加锁标志位(2位)
- JVM默认开启偏向锁,(偏向锁也不是一上来就是偏向可以通过JVM参数设置禁用延迟),当第一个线程来时,发现线程未上锁,锁标志位为01,通过cas方式来用自己的线程id替换markword,如果替换成功表示获得锁,这种是偏向锁,
- 当存在多个线程竞争时,先尝试使用线程的锁记录替换markword,这种是轻量级锁,
- 如果自旋一定程度获取不到,则申请moniter对象,自己进入等待队列entrylist (entrylist 都是就绪的,waitlist是已经获取过锁的,但是调用了wait之类的方法)这种叫重量级锁
Synchronized锁升级过程,两个线程竞争就升级了?
- 默认是开启偏向锁的,如果只有一个线程去争抢锁,第一次通过cas的方式将线程id设置到markwork中,后面就不会在cas设置,直接判断线程id是不是自己
- 当存在两个及以上线程竞争锁,但是多线程执行是错开的,则会先取消偏向标记,然后通过cas的方式来用线程的锁记录(线程都会有栈针,锁记录也会在栈针中,多次重入轻量级锁也是通过栈针的方式,每次重入栈针+1,栈针中存的是锁记录,第一次的锁记录是有对象的markword的后面存值都是null,释放锁也会将栈针中的锁记录-1,减到不为null,表示是第一次获取到锁,此时才是真正的释放锁)和对象的markword替换,替换成功则是获取到了锁
- 如果CAS超过一定次数,或者耗时超过一定规则,则升级为重量级锁
1.6之前有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半,1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制自旋次数,不需要你设置参数了。所以你在做实验的时候,会发现有时候 syncronized 并不比 AtomicInteger 效率低。1.7之后不能控制自旋
Synchronized可重入原理
如果遇到异常,JVM 会自动释放锁,他的可重入在
重量级锁之前:体现在线程的栈针中,栈针中存放有锁记录,重入一次锁记录+1,释放一次锁记录-1
重量级锁: ObjectMonitor中有一个count字段,同轻量级锁,重入加1,同时有owner字段记录所有者线程id
原文参考: https://blog.csdn.net/Weixiaohuai/article/details/126536742
Reentrantlock实现原理
原文参考: https://blog.csdn.net/fuyuwei2015/article/details/83719444
技术点
- volatile 修饰的state,state==0表示没有人占有锁
- park unpark
- cas
- 基于FIFO的等待队列及双向链表
.lock通过cas判断state是否为0,为0则获取到锁,设置exclusive线程为自己,不为0则执行acquire方法尝试获取锁acquire方法中首先调用tryAcquire方法再次通过cas方法设置state,此时如果state为0或者state不为0但是拥有锁的线程是自己(重入)则获取到锁,state=state+1,否则获取失败- 如果第二步中获取锁失败,则调用
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))方法,先调用addWaiter构建node并尝试进入队列,通过cas的方式append到最后设置tail节点,(初始化时,其中一个线程会成为head节点,后续线程继续自旋设置tail节点)设置成功则入队成功,不成功的继续自旋 cas入队,入队成功之后,调用acquireQueued,获取当前节点的前驱节点,前驱为head节点,则自己是老二,再次通过cas的方式获取锁,获取失败则挂起park住(park的时候需要找一个前驱节点状态为signal的),成功则设置head节点为自己
公平锁和非公平锁不同之处在于,公平锁在获取锁的时候,不会先去检查state状态,而是直接执行aqcuire(1),如果占用锁的线程刚释放锁,state置为0,而排队等待锁的线程还未唤醒时,新来的线程就直接抢占了该锁,那么就“插队”了
- 如果多了条件变量,则会调用调用条件变量的awaiter,入队列流程同上
Reentrantlock可重入原理
- 判断自己是否拥有锁
- 拥有锁则state+1
- 解锁state-1
- state==0时完全释放锁
Reentrantlock与Sychronied比较
- 可中断
- 可设置获取锁的超时时间
- 可设置多个条件变量
- 可选择公平和非公平
- 性能上都差不多
Threadlocal
原文参考: https://blog.csdn.net/weixin_44184990/article/details/122279854
使用时一般使用static修饰
在 Java 编程中,使用 ThreadLocal 时确实无法直接解决共享对象的更新问题。因为每个线程都有自己独立的 ThreadLocal 变量副本,对 ThreadLocal 对象的修改只会影响到当前线程内部的变量副本,并不会影响其他线程。
当需要在多个线程之间共享对象并对其进行更新时,可以考虑将 ThreadLocal 对象使用 static 修饰,使其成为类级别的共享变量。这样,所有线程共享同一个 ThreadLocal 对象,但仍然能够保持线程间的隔离性。
原理
Threadlocal也是一个类,但是真正使用的时候,他是作为线程的一个局部变量,是Thread类下的一个字段,实际存值的是Threadlocal下的ThrealocalMap字段,以Threadlocal为key,value为泛型任意值,ThrealocalMap自身存值依赖entry
该Entry是弱引用的子类,会把key设置成弱引用。也就是可能出现key被删除,但是value还在的情况,从而造成内存泄漏。因此,尽量使用完就通过remove()方法把value移除
public class Thread implements Runnable {
......
//与此线程有关的ThreadLocal值。该映射由ThreadLocal类维护。
ThreadLocal.ThreadLocalMap threadLocals = null;
//与此线程有关的InheritableThreadLocal值。该Map由InheritableThreadLocal类维护
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
......
}
什么情况下Threadlocal会内存溢出
典型的就是线程池中使用Threadlocal 没有手动remove
线程池的核心线程是一直存在的,则对Threadlocal的引用也一直存在,一直不会被回收,最终造成内存泄漏
ThreadlocalMap的entry key是继承的弱引用,value是强引用,可能出现key被回收后,value仍然存在,ThreadLocalMap的生命周期与Thread一致,如果不手动清除掉Entry对象的话就可能会造成内存泄露问题
怎么解决
- 显式调用remove方法(推荐)
- 将value也搞成弱引用(不建议)
CountDownLatch
参考原文:
https://blog.csdn.net/qq_45871274/article/details/130223673
https://blog.csdn.net/tianzhonghaoqing/article/details/121139257
是什么
是 Java 中的一个并发工具类,用于协调多个线程之间的同步,常见方法有
// 构造一个用给定计数初始化的 CountDownLatch。
CountDownLatch(int count)
// 使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断。
void await()
// 使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断或超出了指定的等待时间。
boolean await(long timeout, TimeUnit unit)
// 递减锁存器的计数,如果计数到达零,则释放所有等待的线程。
void countDown()
// 返回当前计数。
long getCount()
// 返回标识此锁存器及其状态的字符串。
String toString()
有什么用
用来协调多个线程之间的同步,有点类似join的使用
怎么用
一般要配合超时或者countdown操作在finally中,因为countdown之前代码抛出异常了,则countdown操作不会执行,最后state结果不为0,导致所有线程停在AQS中自旋(死循环)。导致程序出现阻塞
- new CountDownLatch(n),设置计数器初始值为n,
- countdownlatch.countDown(),每当一个任务线程执行完毕,计数器减一
- 当计数器的值变为0时,在CountDownLatch上await()的线程就会被唤醒
伪代码展示: 主线程开始执行前等待其他线程执行完
main 方法{
CountDownLatch latch = new CountDownLatch(2);
线程1{
run方法{
...
执行业务逻辑
..
finally{
latch.countDown();
}
}
}.start();
线程2{
run方法{
...
执行业务逻辑
..
finally{
latch.countDown();
}
}
}.start();
latch.wait();
主线程执行业务逻辑...
}
底层原理是怎样的,或者说他的底层是怎么实现的
参考: https://blog.csdn.net/weixin_38361347/article/details/127643789
- 基于AQS队列实现,
- CountDownLatch 构造函数中指定的 count直接赋给AQS的state;
每次countDown()则都是release(1)减1,最后减到0时unpark阻 塞线程----这一步是由最后一个执行countdown方法的线程执行的。 - 而调用await()方法时,当前线程就会判断state属性是否为0,如果为0,则继续往下执 行,如果不为0,则使当前线程进入等待状态,直到某个线程将state属性置为0,其就会唤醒在 await()方法中等待的线程。
Cyclicbarrier
介绍和使用
原文参考: https://blog.csdn.net/qq_21383435/article/details/110276919
CyclicBarrier通常称为循环屏障。它和CountDownLatch很相似,都可以使线程先等待然后再执行。
CountDownLatch是使一批线程等待另一批线程执行完后再执行;而CyclicBarrier只是使等待的线程达到一定数目后再让它们继续执行。故而CyclicBarrier内部也有一个计数器,计数器的初始值在创建对象时通过构造参数指定
每调用一次await()方法都将使阻塞的线程数+1,只有阻塞的线程数达到设定值时屏障才会打开,允许阻塞的所有线程继续执
- CyclicBarrier的计数器可以重置而CountDownLatch不行,这意味着CyclicBarrier实例可以被重复使用而CountDownLatch只能被使用一次。而这也是循环屏障循环二字的语义所在
- CyclicBarrier允许用户自定义barrierAction操作,这是个可选操作,可以在创建CyclicBarrier对象时指定,一旦用户在创建CyclicBarrier对象时设置了barrierAction参数,则在阻塞线程数达到设定值屏障打开前,会调用barrierAction的run()方法完成用户自定义的操作
底层实现原理
Semaphore和CountDownLatch两个并发工具类,都是通过CLH等待队列实现的,CyclicBarrier ,该类与前二者不同,除了使用CLH同步等待队列 外(应用reentrantlock加锁,reentrantlock也靠CLH队列),还用了条件等待队列来实现
- 一个count字段一个parties字段
- parties用来记录线程个数,这里表示多少线程调用await后,所有线程才会冲破屏障继续往下运行。
- count一开始等于parties,每当有线程调用await方法就递减1,当count为0时就表示所有线程都到了屏障点。
- 当count计数器值变为0后,会将parties的值赋给count,从而进行复用
- 使用lock首先保证了更新计数器count的原子性
- 另外使用lock的条件变量trip支持线程间使用await和signal操作进行同步
- 在变量generation内部有一个变量broken,其用来记录当前屏障是否被打破
参考: https://blog.csdn.net/m0_68933188/article/details/137192861
Semaphore
特点及使用
参考原文: https://blog.csdn.net/admans/article/details/125957120
Semaphore在构造的时候, 可以传入一个int. 表示有多少许可(permit). 线程获取锁的时候, 要告诉信号量使用多少许可,当线程要使用的许可不足时, 则调用的线程则会被阻塞
伪代码展示:
Semaphore sem = new Semaphore(2);
线程1 sem.acquire()
finally{sem.release}
线程1 sem.acquire()
finally{sem.release}
底层原理
参考原文: https://blog.csdn.net/admans/article/details/125957120
基于AQS队列实现,类似于停车场的原理,车位有限,车位不够加入阻塞队列park,停车离场 车位+1
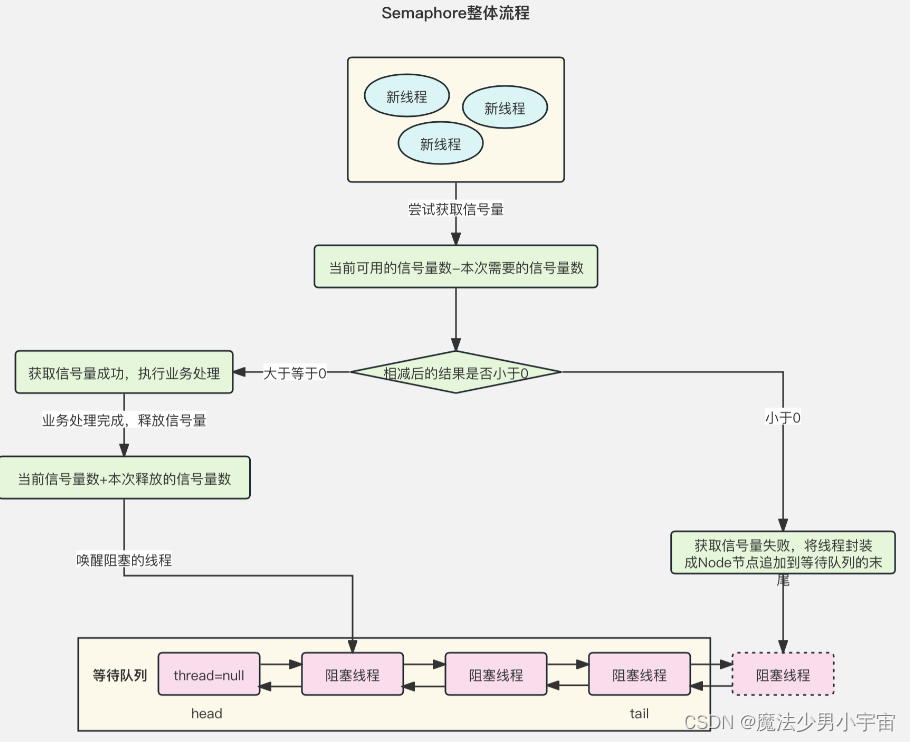
参考: https://blog.csdn.net/weixin_43759352/article/details/136282113
Redis
数据结构
参考: https://blog.csdn.net/weixin_40918067/article/details/116572462
- String
- String类型是二进制安全的,意思是redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
- String是redis最基本的类型,一个key对应一个value。
- 一个redis中字符串value最多可以是512M
- 适用于常见的key v(比如json)存储和计数功能
- List (string列表,有序,类型linkedlist)
- 双向链表实现
- 储多个数据,并对数据进入存储空间的顺序进行区分
- 可以用作队列使用
- Set( String 类型的无序集合)
- 是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)
- 成员是不可重复的
- 常用作去重
- Zset(有序集合)
- 有序集合的成员是唯一的
- 每个元素都会关联一个 double 类型的权重参数(score),使得集合中的元素能够按score进行有序排列
- 分数(score)却可以重复。
- 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 例如热门歌曲榜单列表,value值是歌曲ID,score是播放次数,这样就可以对歌曲列表按播放次数进行排序
- Hash
- 一个 string 类型的 field(字段) 和 value(属性) 的映射表,hash 特别适合用于存储对象。
- hash字典类型也是比较适合保存结构体信息的,不同于字符串一次序列化整个对象,hash可以对用户结构中的每个字段单独存储。这样当我们需要获取结构体信息时可以进行部分获取,而不用序列化所有字段,而将整个字符串保存的结构体信息只能一次性全部读取。
新增数据结构
- bitmap
- hyperloglog
- GEO
redis跳表
参考: https://blog.csdn.net/weixin_46935110/article/details/127816987
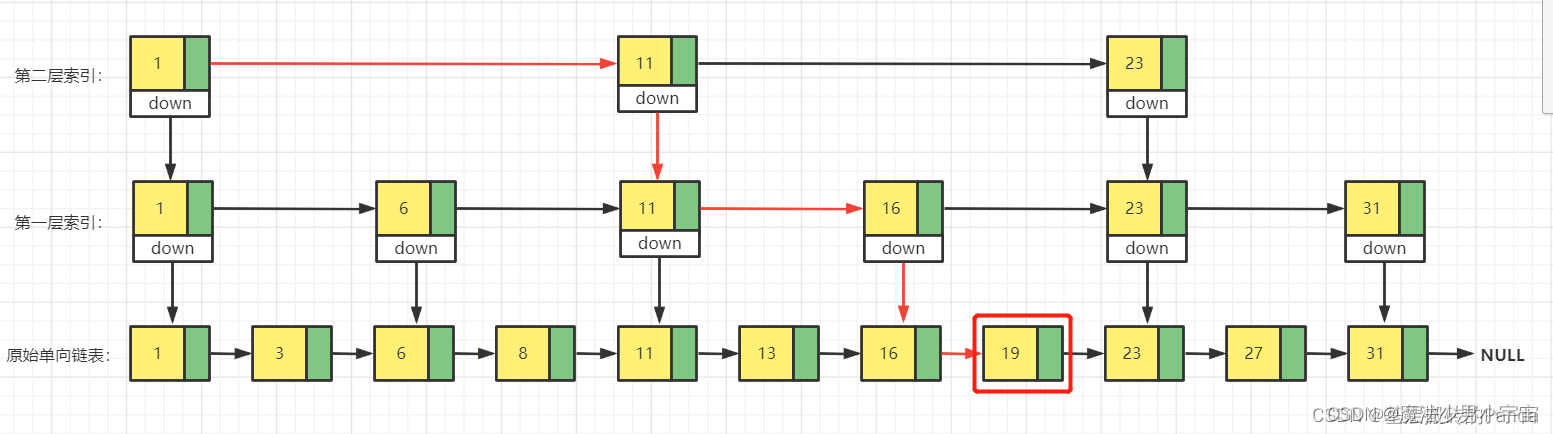
一言难尽,主要用于redis中的zset底层存储结构,可以理解为,多层索引,增加查询效率,以空间换时间
统计某月某天的电影是否点击用哪种数据类型
bitmap
001110011
统计日 周 月排行榜
参考: https://blog.csdn.net/qq_30285985/article/details/112382087
Zset是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分( score) ,这个评分( score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。
大key处理
原文参考: https://blog.csdn.net/qq_34827674/article/details/126225192
大key是value比较大
比如
- String 类型值大于10KB
- Hash、List、Set、Zset类型元素个数超过5000个
影响:- 客户端超时阻塞。由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 引发网络阻塞。每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 阻塞工作线程。如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
内存分布不均。- 集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大
-
如何定位
redis-cli --bigkeys 查找大key最好选择在从节点上执行该命令。因为主节点上执行时,会阻塞主节点;
如果没有从节点,那么可以选择在 Redis 实例业务压力的低峰阶段进行扫描查询,以免影响到实例的正常运行;或者可以使用 -i 参数控制扫描间隔,避免长时间扫描降低 Redis 实例的性能。使用 SCAN 命令查找大 key使用 RdbTools 工具查找大 key
-
怎么删除
分批次删除异步删除(Redis 4.0版本以上)
-
如何避免
- 比如value压缩
- 数据优化,存储有效字段
- 将大key分解为小key存储,可以通过mget的方式返回
- 清理大key(对Redis中的大Key进行清理,从Redis中删除此类数据。Redis自4.0起提供了UNLINK命令,该命令能够以非阻塞的方式缓慢逐步的清理传入的Key,通过UNLINK,你可以安全的删除大Key甚至特大Key)
redis快的原因(分片?)
-
操作都是基于内存的
-
高效的数据结构
-
处理网络请求模块单线程操作(数据量不是很大时,上下文切换会耗费大量时间)
-
I/O多路复用(也叫事件驱动IO-Reactor设计模式) 视频
原文参考:https://blog.csdn.net/v123411739/article/details/124699602
例子:你是一个老师,让学生做作业,学生做完作业后收作业。
- 同步阻塞:逐个收作业,先收A,再收B,接着是C、D,如果有一个学生还未做完,则你会等到他写完,然后才继续收下一个。
- 同步非阻塞:逐个收作业,先收A,再收B,接着是C、D,如果有一个学生还未做完则你会跳过该学生,继续去收下一个。
- select/poll:学生写完了作业会举手,但是你不知道是谁举手,需要一个个的去询问。
- epoll:学生写完了作业会举手,你知道是谁举手,你直接去收作业。
select
将socket是否就绪检查逻辑下沉到操作系统层面,避免大量系统调用。告诉你有事件就绪,但是没告诉你具体是哪个FD。
优点:不需要每个FD都进行一次系统调用,解决了频繁的用户态内核态切换问题
缺点:
- 单进程监听的FD存在限制,默认1024
- 每次调用需要将FD从用户态拷贝到内核态
- 不知道具体是哪个文件描述符就绪,需要遍历全部文件描述符入参的
- 3个fd_set集合每次调用都需要重置
poll
在select的基础上优化了
- 拷贝到内核态是一个链表而不是数组了没有了1024的限制
单进程监听的FD存在限制,默认1024 3个fd_set集合每次调用都需要重置
epoll
解决了select和poll的缺陷
但是自身还是有缺陷- 跨平台性不够好,只支持 linux,macOS 等操作系统不支持
- 相较于 epoll,select 更轻量可移植性更强
- 在监听连接数和事件较少的场景下,select 可能更优
缓存雪崩,缓存击穿,缓存穿透
缓存穿透
现象:
是用户访问的数据既不在缓存当中,也不在数据库中,高并发或有人利用不存在的Key频繁攻击时,数据库的压力骤增,甚至崩溃,这就是缓存穿透问题
解决
- 缓存空值(null)或默认值 [ 效时间不宜过长,一般设置为5分钟之内。当数据库被写入或更新该key的新数据时,缓存必须同时被刷新,避免数据不一致]
- 业务逻辑前置校验[前端校验]
- 使用布隆过滤器请求白名单[没用过]
- 用户黑名单限制
缓存雪崩
现象
大量热点key同时过期或者 缓存服务故障导致请求全部转发到数据库,从而导致数据库压力骤增,甚至宕机。从而形成一系列的连锁反应,造成系统崩溃等情况,这就是缓存雪崩
解决
- 过期时间后面加上一个随机数(比如随机1-5分钟),让key均匀的失效
- 多级缓存如redis,nginx等
- 高可用集群
- 服务熔断、限流、降级等措施保障。
缓存击穿
现象
单个热点key,在不停的扛着大并发,在这个key失效的瞬间,持续的大并发请求就会击破缓存,直接请求到数据库
解决
- 热点数据不设置过期时间,后台异步更新缓存,适用于不严格要求缓存一致性的场景
- 二级缓存,设置不同的失效时间,保证不会同时过期就行
- 定时任务刷新数据
- 锁(不建议,失去了redis的快,有效也无意义)
持久化方案和数据恢复方案
持久化方案
RDB(数据快照)
优点
与AOF相比,恢复大数据集的时候会更快,它适合大规模的数据恢复场景,如备份,全量复制等
缺点
没办法做到实时持久化/秒级持久化。
AOF(AOF是执行完命令后记录的操作记录日志)
采用日志的形式来记录每个写操作,追加到AOF文件的末尾,
AOF机制的三种写回策略 appendfsync:
always,同步写回,每个子命令执行完,都立即将日志写回磁盘。
everysec,每个命令执行完,只是先把日志写到AOF内存缓冲区,每隔一秒同步到磁盘。
no:只是先把日志写到AOF内存缓冲区,有操作系统去决定何时写入磁盘。
优点
数据的一致性和完整性更高,秒级数据丢失
缺点
相同的数据集,AOF文件体积大于RDB文件。数据恢复也比较慢
恢复方案
-
如果数据不能丢失,RDB和AOF混用
-
如果只作为缓存使用,可以承受几分钟的数据丢失的话,可以只使用RDB。
-
如果只使用AOF,优先使用everysec的写回策略。
基于redis的分布式锁和其他实现的分布式锁原理及选型分析
原文参考: https://blog.csdn.net/jiandanokok/article/details/114296755
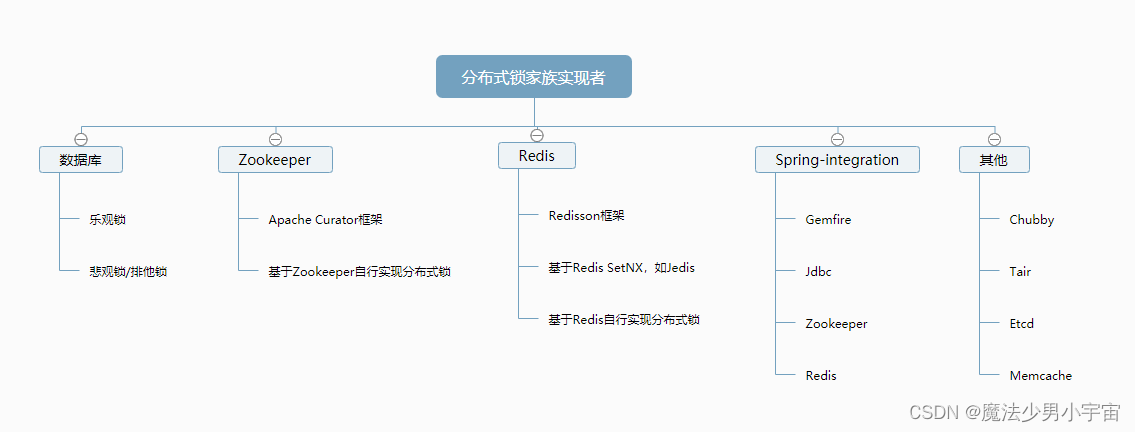
基于mysql
悲观锁(除了简单,全是缺点)
利用select … where xx=yy for update排他锁
注意:这里需要注意的是where xx=yy,xx字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
乐观锁(不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。)
update xx set version=new_version where xx=yy and version=Old_version
Resrouce resource = exeSql("select * from resource where resource_name = xxx");
boolean succ = exeSql("update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion'");
if (!succ) {
// 发起重试
}
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功。
- 性能低,并且有锁表的风险
- 可靠性差
- 非阻塞操作失败后,需要轮询,占用CPU资源
- 长时间不commit或者是长时间轮询,可能会占用较多的连接资源
基于zookeeper(推荐直接使用Apache的开源库Curator)
利用临时有序的节点的特性,当一个线程来竞争锁时,先创建一个临时的有序节点,判断自己是不是序列最大的,如果是则获取到锁,不是则监听上个节点并且进入等待队列
使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点
优点
- 性能较好
- 可靠性非常高
- CAP模型属于CP,基于ZAB一致性算法实现(选举恢复特性)
缺点
- 性能并不如Redis(主要原因是在写操作,即获取锁释放锁都需要在Leader上执行,然后同步到follower)
基于Redis(一致性要求非常高的情况下,一般是不会使用Redis,而推荐使用Zookeeper)
优点
- 性能非常高
- 可靠性较高
- CAP模型属于AP
缺点
- 无一致性算法,可靠性并不如Zookeeper
- 锁删除失败 过期时间不好控制
- 非阻塞,获取失败后,需要轮询不断尝试获取锁,比较消耗性能,占用cpu资源
实现(推荐redisson)
- 获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁(防死锁),
- 锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。(防误删,删的时候先获取再删除不是原子操作要用lua脚本)
- 获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。(设置超时)
Redis 实现分布式锁中,获取锁、释放锁为什么要使用 Lua 脚本?
- 使用 Lua 脚本的主要原因是为了保证操作的原子性,避免出现并发问题或误解锁的情况。
- 使用 setnx 命令获取锁,然后使用 expire 命令设置过期时间,这两个命令之间可能会发生网络延迟或者其他异常,导致锁没有正确设置过期时间,从而造成死锁
- 使用 del 命令释放锁,需要先判断锁是否属于当前客户端,否则可能会误解其他客户端的锁。
总结
- 追求数据可靠性/强一致性:使用Zookeeper
- 追求性能:选择Redis,推荐Redisson
- Redis分布式锁目前最大问题在于:主从模式下/集群模式下,master节点宕机,异步同步数据导致锁丢失问题
- Redis的RedLock算法具有很大争议性,一般不推荐使用
redis的垃圾回收算法
原文参考: https://blog.csdn.net/weixin_37974649/article/details/106926825
- noeviction:但内存达到限制无法再执行命令时,直接返回错误
- allkeys-lru: 按照lru算法来回收数据(lru,least recently used 最近最少使用,意思为选择出最少被使用的数据.原理:一个栈,每次访问数据的时候都往栈顶加数据,当栈满了时,就会删除栈尾的数据,当访问到的数据已经在栈中存在时,就会把数据重新放会栈顶。这样就可以实现不停的淘汰最少访问的数据)
- volatile-lru:按照lru算法来回收过期的数据
- allkeys-random: 随机回收数据
- allkeys-random: 随机回收过期了的数据
- volatile-ttl:回收过期的数据,按照过期的时间顺序
注意,redis采用的lru算法只是使用了一种近似的lru算法,真正的lru算法需要消耗大量的内存所以不被采用
redis的集群部署
原文参考: https://blog.csdn.net/miss1181248983/article/details/90056960
- 主从:
这种模式比较简单,主库可以读写,并且会和从库进行数据同步,这种模式下,客户端直添加链接描述接连主库或某个从库,但是当主库或者从库宕机后,客户端需要手动修改IP,另外,这种模式也比较难进行扩容,整个集群所能存储的数据收到某台机器的内存容量,所以不可能支持特大数据量。 - 哨兵:
这种模式在主从的基础上新增了哨兵节点,当主库节点宕机后,哨兵会发现主库节点宕机,然后从库中选择一个库作为进的主库,另外哨兵也可以做集群,从而可以保证当某一个是哨兵节点宕机后,还有其他哨兵节点可以继续操作,这种模式比较好的保证了Redis的高可用,但是仍然不能很好的解决Redis的容量上限问题 - Cluster 集群
Cluster模式是用的比较多的模式,它支持多主多从,这种模式会按照key进行槽位的分配,可以使得不同的key分散到不同的主节点上,利用这种模式可以使得整个集群支持更大的数据容量,同时每个主节点可以拥有自己的多个从节点,如果该主节点宕机,会从它的从节点中选举一个新的主节点。
对于这三种模式,如果Redis要存的数据量不大,可以选择哨兵模式。如果Redis要存的数据量大,并且需要持续的扩容,那么选择Cluster模式
rediscluster集群原理
推荐 :
https://blog.csdn.net/weixin_40205234/article/details/124614720
https://blog.csdn.net/a745233700/article/details/112691126
普通hash取模做集群(未采用)
- 提前预估系统的分片节点数,比如有三个节点
- 用固定字段hash算法后再%总节点数,得到该从哪个节点存取(对象.字段.hash() % / 3)
- 如果用户激增需要扩容,此时增加一个节点,一共四个节点
- 对象.字段.hash() % / 4得到存取节点,此时算法出来的存取节点可能发生变化,会导致存在数据但是查询不到的情况,要解决的话只有对所有存在的数据重新hash,数据迁移.代价很大,
redis cluster集群没有采用
一致性hash(未采用)
普通hash是对节点数量取模,一致性Hash算法是对 2^32 取模,将整个哈希值空间组织成一个虚拟的圆环
- 对节点,按照一定的规则,比如按照 ip 地址的哈希值,得到在hash环上的位置
- 通过数据 key 哈希,落在哈希环上的节点,然后顺时针找到第一个大于等于该哈希值
- 优点是在加入和删除节点时只影响相邻的两个节点,缺点是加减节点会造成部分数据无法命中,扩容一般增加一倍节点保障数据负载均衡
- 还有数据倾斜的问题,比如节点太少,两个节点在hash环上的位置太近,将导致一个节点拥有多数数据,造成数据倾斜
- 也会有数据迁移,只是数据量没有普通hash那么大
- 针对数据倾斜的问题,引入了虚拟节点的概念,将真实节点计算多个哈希形成多个虚拟节点并放置到哈希环上,定位算法不变,只是多了一步虚拟节点到真实节点映射的过程
哈希槽算法(官方推荐使用)
原文链接:https://blog.csdn.net/a745233700/article/details/112691126
集群节点间采用Gossip协议通讯
slot = CRC16(key)%16383
redis cluster的新增和删除节点都需要手动来分配槽区
Redis集群采用的算法是哈希槽分区算法。Redis集群中有16384个哈希槽(槽的范围是 0 -16383,哈希槽),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点只负责一部分的哈希槽。在对数据进行操作的时候,集群会对使用CRC16算法对key进行计算并对16384取模(slot = CRC16(key)%16383),得到的结果就是 Key-Value 所放入的槽,通过这个值,去找到对应的槽所对应的Redis节点,然后直接到这个对应的节点上进行存取操作。
使用哈希槽的好处就在于可以方便的添加或者移除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了
默认情况下,redis集群的读和写都是到master上去执行的,不支持slave节点读和写,跟Redis主从复制下读写分离不一样,因为redis集群的核心的理念,主要是使用slave做数据的热备,以及master故障时的主备切换,实现高可用的。Redis的读写分离,是为了横向任意扩展slave节点去支撑更大的读吞吐量。而redis集群架构下,本身master就是可以任意扩展的,如果想要支撑更大的读或写的吞吐量,都可以直接对master进行横向扩展。
redis的集群模式如何保证高可用和动态扩容的
原文 https://blog.csdn.net/keehom/article/details/131523834
- 数据分片
- 故障转移
- 节点复制(主从复制)
- 节点监控
- cluster分片负载均衡
Redis的集群为什么是16384个槽
在握手成功后,两个节点之间会定期发送ping/pong消息,交换数据信息,在redis节点发送心跳包时需要把所有的槽信息放到这个心跳包里,以便让节点知道当前集群信息,在发送心跳包时使用char进行bitmap压缩后是2k(16384÷8÷1024=2kb),也就是说使用2k的空间创建了16k的槽数。
虽然使用CRC16算法最多可以分配65535(2^16-1)个槽位,65535=65k,压缩后就是8k(8 * 8 (8 bit) * 1024(1k) = 8K),也就是说需要需要8k的心跳包,作者认为这样做不太值得;并且一般情况下一个redis集群不会有超过1000个master节点,所以16k的槽位是个比较合适的选择。
原文链接 https://blog.csdn.net/weixin_43001336/article/details/122834046
redis和memcache的区别
- 数据结构:Memcache仅能支持简单的K-V形式,Redis支持的数据更多
- 多线程:Memcache支持多线程,Redis支持单线程,CPU利用Memcache利用率更高
- 持久化:Redis支持持久化,Memcache不支持持久化
- 分布式:Redis做主从结构,而Memcache服务器需要通过hash一致化来支撑主从结构
- 虚拟内存:Redis当物理内存使用完时,会将一些很久没有用的内存交换到磁盘,而Memcache采取的LUR策略,将一部分数据刷新
对两者进行对比,是因为都是内存数据管理系统,而实际上两者之间区别还是很大,Redis更多的象一个键值对数据,包括数据的持久化,主从架构,数据备份等策略都是为了保证数据安全以及高可用,而Memcache更多的是一个数据缓存系统是为了提升数据的读取效率,所以两者的应用也有所不同,Memcache适合于适合于缓存SQL语句Q、数据集、用户临时性数据、延迟查询数据和session等工作场合,Redis除去做Nosq数据库使用外,还能用做消息队列,数据堆栈和数据缓存等。
HashMap的数据丢失问题和扩容死链
扩容死链
原文参考: https://blog.csdn.net/m0_45364328/article/details/125048333
HashMap的死循环只发生在JDK1.7版本中
主要原因:头插法+链表+多线程并发+扩容,累加到一起就会形成死循环
数据丢失
Hash的putvalue方法,当计算的桶下标一致,假如上一个线程计算出桶下标还没填充数据,下一个又来了 就可能出现数据的覆盖,导致数据丢失
ConcurrentHashMap锁粒度分析
JDK1.7给Segment添加ReentrantLock锁来实现线程安全
JDK1.8通过CAS或者synchronized来实现线程安全
1、ConcurrentHashMap在JDK1.7中使用的是数组加链表的结构,其中数组分两大类,大数组segment,小数组HashEntry,而加锁是通过给Segment加ReentrantLock重入锁来保证线程安全
2、ConcurrentHashMap在JDK1.8中使用的是数组加链表加红黑树的结构,它通过CAS或synchronized来保证线程安全的,并且缩小了锁的粒度,查询性能也更高
Mysql
vachar 和char
char(4)
- 如果存入字符不满4个时用自动用空格补齐4个字符
- 如果存入字符数等于4则原样存入,占用空间取决于实际存入的字符以及使用的字符集,比如存入’abcd’是4个字节,但是存入’张三李四’就是8个字节。
- 如果存入超过4个字符会自动截断,比如存入’abcdefg’,会被MySQL截断为’abcd’存入数据库,高版本MySQL会直接报错(ERROR 1406 (22001) Data too long for column)
varchar(100)
指的是100字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放100个
VARCHAR类型不会自动补齐空格,但是存入的不仅包含我们需要存入字符串数据,还包含描述我们所要存入数据的元数据。所以VARCHAR类型字段值占用空间包含两部分:1、我们存入字符串的占用空间。2、元数据的占用空间。
UTF8编码中一个汉字(包括数字)占用3个字节
GBK编码中一个汉字(包括数字)占用2个字节(byte)
如果存入超出范围的字符串处理方式同CHAR一样。
binlog日志文件的格式
原文链接:https://blog.csdn.net/yxg520s/article/details/122242793
bin log的三种日志格式
binlog 有三种记录格式,分别是ROW、STATEMENT、MIXED。
1、ROW: 基于变更的数据行进行记录,如果一个update语句修改一百行数据,那么这种模式下就会记录100行对应的记录日志。
2、STATEMENT(mysql默认的日志格式):基于SQL语句级别的记录日志,相对于ROW模式,STATEMENT模式下只会记录这个update 的语句。所以此模式下会非常节省日志空间,也避免着大量的IO操作。
3、MIXED: 混合模式,此模式是ROW模式和STATEMENT模式的混合体,一般的语句修改使用statment格式保存binlog,如一些函数的日志;对于statement无法完成主从复制的操作,则采用row格式保存binlog。
这三种模式需要注意的是:使用 row 格式的 binlog 时,在进行数据同步或恢复的时候不一致的问题更容易被发现,因为它是基于数据行记录的。而使用 mixed 或者 statement 格式的 binlog 时,很多事务操作都是基于SQL逻辑记录,我们都知道一个SQL在不同的时间点执行它们产生的数据变化和影响是不一样的,所以这种情况下,数据同步或恢复的时候就容易出现不一致的情况。
大数据量分页查询
参考: https://blog.csdn.net/qq_33589510/article/details/118198525
优化
- 使用延迟关联
- 前端缓存或者瀑布流式查看(滚动页面)
- 使用书签方式 ,记录上次查询最新/大的id值,向后追溯 M行记录
mysql死锁发生条件及解决方案
参考: https://blog.csdn.net/qq_26664043/article/details/136253409
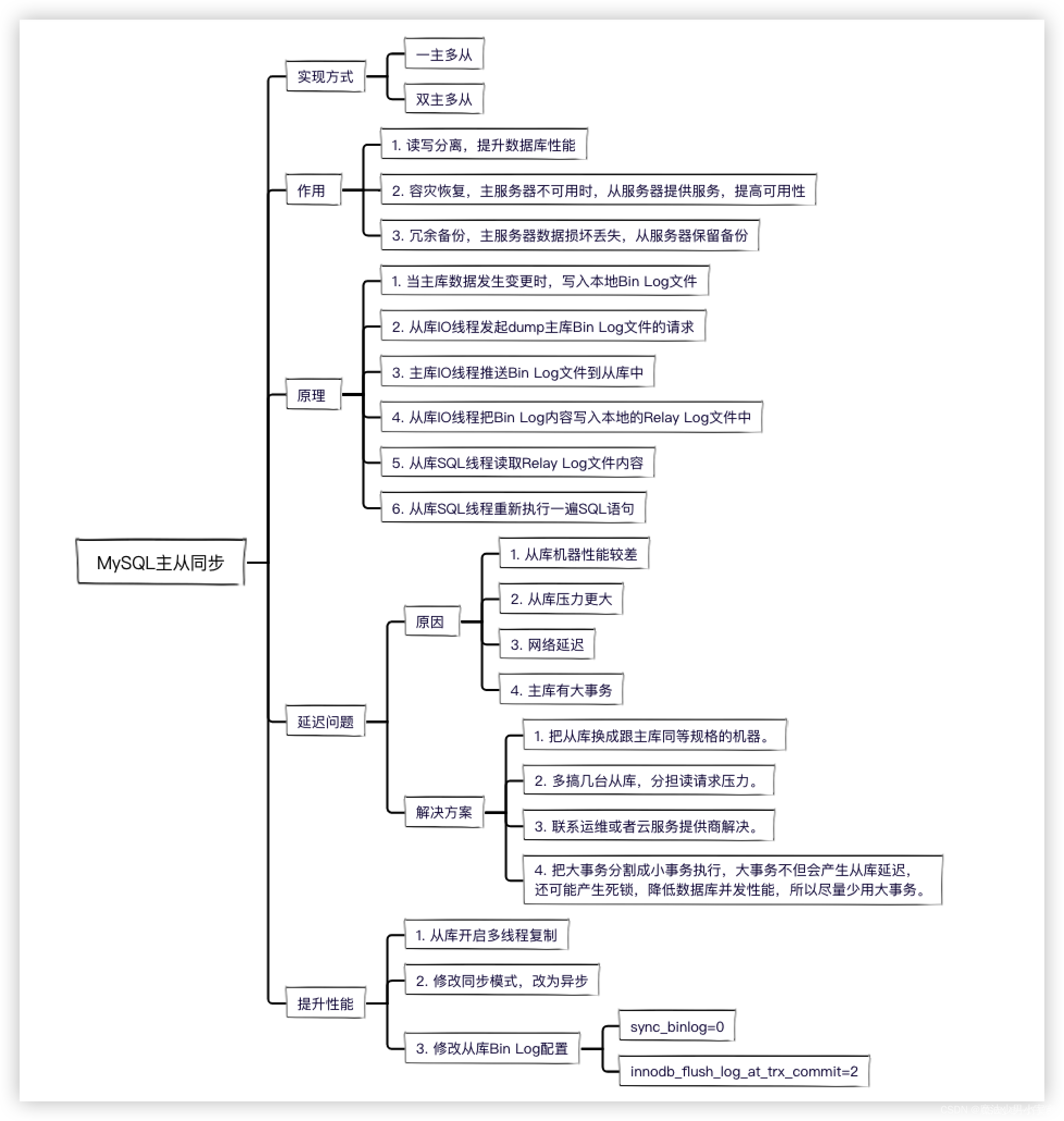
数据同步原理
原文参考: https://blog.csdn.net/murongguofu/article/details/125471420
-
当主库数据发生变更时,写入本地Bin Log文件
-
从库IO线程发起dump主库Bin Log文件的请求
-
主库IO线程推送Bin Log文件到从库中
-
从库IO线程把Bin Log内容写入本地的Relay Log文件中
-
从库SQL线程读取Relay Log文件内容
-
从库SQL线程重新执行一遍SQL语句
Mybatis
有几级缓存
原文参考: https://blog.csdn.net/m0_61961937/article/details/127070497
两级,一级缓存和二级缓存,
一级缓存都是自动开启的,不允许关闭,SqlSession级别,底层Hashmap存储
二级缓存,基于SqlSessionFactory级别的缓存,需要在mapper.xml中开启才能生效,只需要加入cache标签即可,同namespace共享一个缓存[HashMap 存储]
两次查询之间执行了任意的增删改,会使一级和二级缓存同时失效
一级缓存脏数据问题
原文参考: https://blog.csdn.net/qq_19439605/article/details/81195545
分布式环境下,一级缓存无法统一管理,导致不同的节点可能查询出现结果不一致的情况
解决方案
- 设置Mybatis一级缓存为STATEMENT级别
在select标签里面设置flushCache="true"
二级缓存的脏数据问题
对于多表联合查询,如果不在同一个命名空间下,则数据容易出现脏读。使用MyBatis二级缓存有一个前提:必须保证所有的增删改查都在同一个命名空间下才行
解决方案
使用三方缓存,比如redis
Https的工作流程和加密方式
本文链接:https://blog.csdn.net/qq_64580912/article/details/131224709
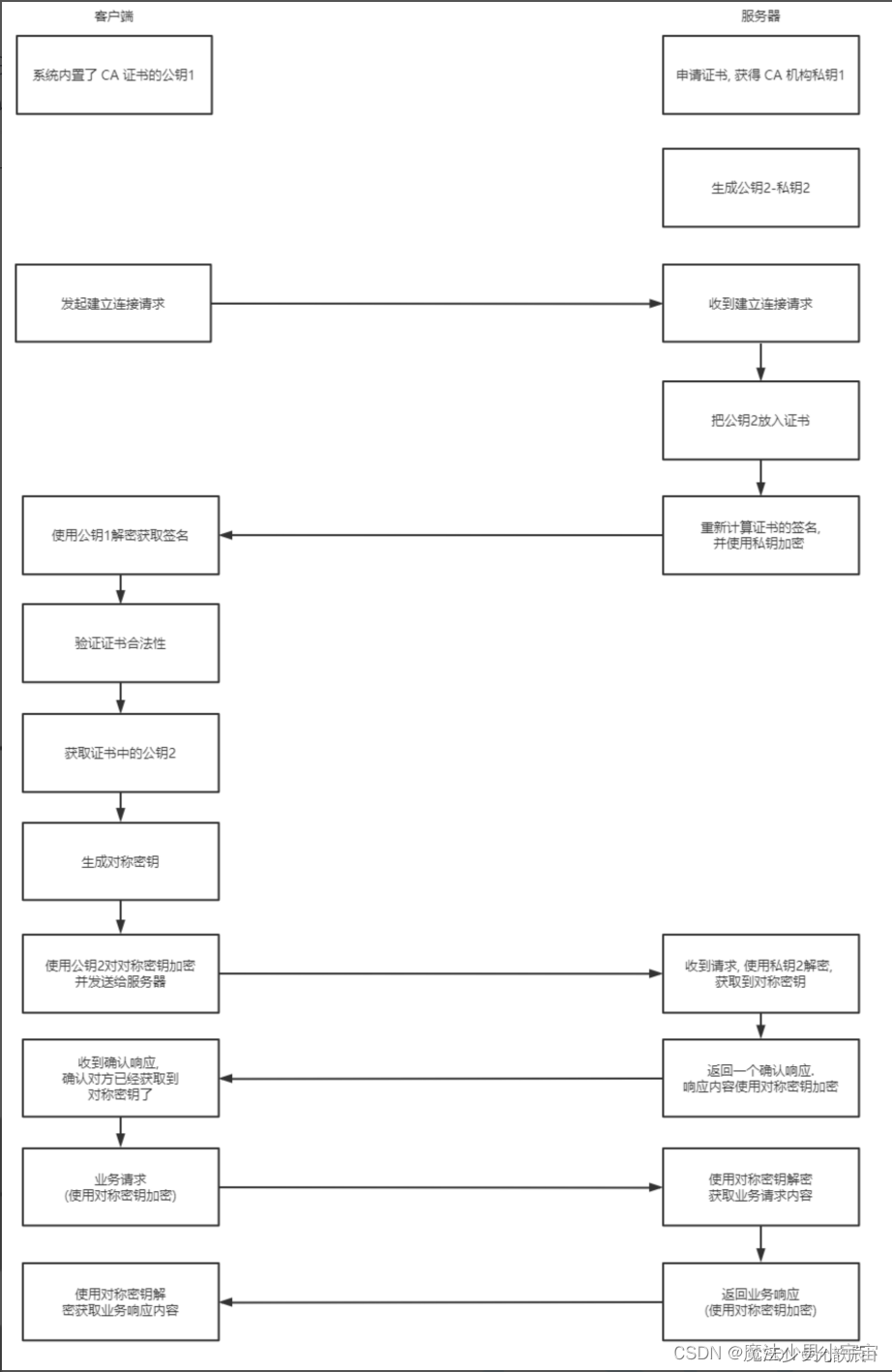
工作流程
- 客户端内置了CA机构的公钥( 操作系统包含了可信任的 CA 认证机构有哪些 , 同时持有对应的公钥)
- 服务端向CA机构申请了证书和并获取到了私钥1
- 在第二步基础上服务器端生成了公钥2和私钥2
- 客户端发送建立连接的请求,TCP三次握手建立了连接.然后服务器端将公钥2放到了证书中,并对证书内容用哈希函数(如MD5)计算哈希值作为证书的签名并用私钥1对签名进行了加密处理
- 客户端用公钥1对签名进行解密,并计算证书的MD5值,与签名中的MD5值进行对比,如果相同就说明证书的内容没有被修改过.然后客户端生成对称密钥
- 取出证书中的公钥2,对对称密钥进行加密并发送给服务端
- 服务端使用私钥2对对称密钥进行解密,此时服务器端和客户端就都获取到了一样的对称密钥,之后双方传输的数据就采用对称密钥进行加密.
加密方式
https既有对称加密也有非对称加密
对称加密的密钥使用的是非对称加密
传输实际内容使用的是对称加密
JVM
原文: https://blog.csdn.net/ashfiqa/article/details/122658797
怎么识别垃圾,哪些对象是根对象
原文链接:https://blog.csdn.net/vnjohn/article/details/131452881
垃圾识别
- 引用计数法
引用计数算法(Reference Counting):在对象中添加一个引用计数器,每当有一个其他对象引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的,譬如单纯的引用计数算法就很难解决对象之间相互引用的问题,例如:A->B、B->A,A、B 计数器的值都为 1,所以在当前算法来说不是垃圾,但从此看来,没有其他的引用会使用到它们,按理来说这几个都应该是为 “垃圾”
- 根可达性算法
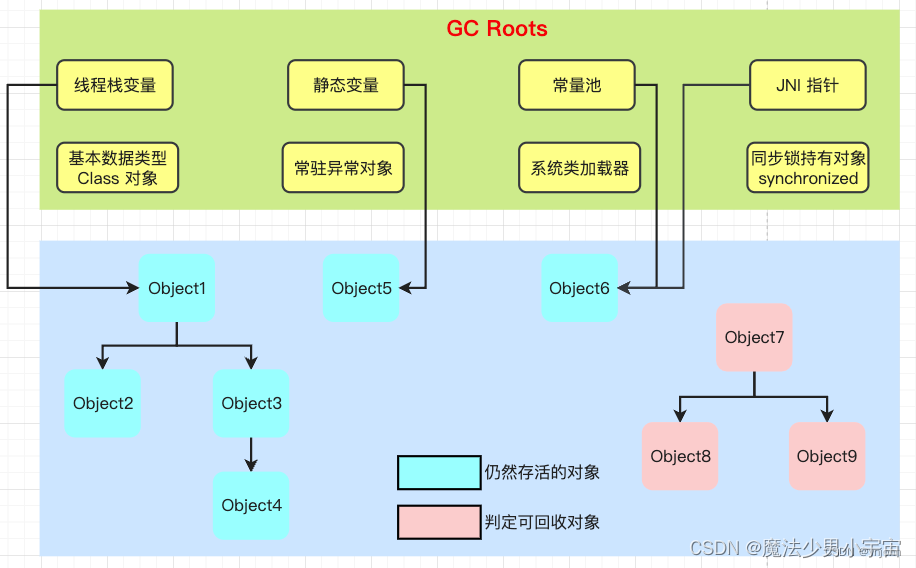
固定可作为 GC Roots 对象包括以下几种:
-
线程栈变量:在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等
比如:main 方法主线程开始运行,主线程栈中变量调用了其他的方法,主线程栈中的方法访问到的对象叫根对象 -
静态变量:在方法区类静态属性引用的对象,譬如 Java 类引用类型的静态变量,静态变量初始化,能够访问到的对象称之为根对象
-
常量池:在方法区中常量引用的对象,譬如字符串常量池(String Constant Pool)里面的引用,若一个 class 能够用到其他的 class 对象称之为根对象
-
JNI 指针:在本地方法栈中 JNI(Java Native Interface)方法引用的对象
-
基础数据类型 Class 对象*:Java 虚拟机内部的引用,如 int 类型对应 Class 对象是 Integer.TYPE 或 int.class、long 类型对应 Class 对象是 Long.TYPE 或 long.class*
-
常驻异常对象:Java 虚拟机内部的引用,如 NullPointException、OutOfMemoryError
-
系统类加载器
-
同步锁持有对象:被同步锁 synchronized 持有的对象
Java 虚拟机并不是通过引用计数算法来判断对象是否存活的
JDK 8 默认使用的垃圾收集器:Parallel Scavenge、Parallel Old
Java中常见的垃圾收集器,如:Serial、Parallel、CMS、G1 等,并不使用引用计数算法,而是采用基于可达性分析的算法来进行垃圾回收
元空间的保存了哪些信息
原文链接:https://blog.csdn.net/Hicodden/article/details/115997210
类信息、常量、静态变量,即时编译器编译后的代码缓存等
元空间的直接内存
原文参考: https://blog.csdn.net/Ethan_199402/article/details/110431404
1.8后,取消了永久代对方法区的实现,改用了元空间来实现方法区,元空间的内存不属于JVM内存,属于堆外内存,某种程度上也就是指DirectByteBuffer对象占用的堆外内存。unsafe类接口直接调用操作系统的malloc分配内存,然后将内存的起始地址和大小保存下来,据此就可以直接操作内存空间,直接内存的大小并不受到java堆大小的限制,甚至不受到JVM进程内存大小的限制。它只受限于本机总内存(RAM及SWAP区或者分页文件)大小以及处理器寻址空间的限制
使用直接内存的原因
- 这块内存真正的分配并不在 Java 堆中,堆中只有一个很小的对象引用,这种方式能减轻 GC 压力
- 对于堆内对象,进行IO操作(Socket、文件读写)时需要先把对象复制一份到堆外内存再写入 Socket 或者文件,而当 DirectByteBuffer 就在堆外分配内存时可以省掉一次从堆内拷贝到堆外的操作,减少用户态到内核态的操作,性能表现会更好
- 之前永久代使用JVM内存的方式,这块内存不太可控,如果设置小了,系统运行过程中就容易出现内存溢出,设置大了又浪费内存
怎么回收
- 一般发生在年老代垃圾回收Full GC
- 代码显示调用System.gc的时候(不推荐,System.gc主动进行垃圾回收时一个非常危险的动作。因为它要停止所有的响应,才能检查内存中是否有可回收的对象,这对一个应用系统风险极大。 )
- 调用unsafe.freememory
G1垃圾回收器的特点
整体是标记整理算法、Region之间标记复制算法
截图截自: https://blog.csdn.net/qq_40991313/article/details/130232389

G1优先回收规则
首先,jvm有一个 参数 -XX:MaxGCPauseMillis=默认0.2s,表示用户期望的最大stw时间,他是一个建议值,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。G1跟踪各Region里垃圾的回收价值(回收空间大小和预计回收时长),在后台维护一个优先级列表,G1会根据这个参考值,在这个值的范围内,找到回收时间最小和空间最有的region回收,达到优先回收的目的,
比如一个 Region 回收需要花费 200ms, 能释放 10M 的空间,回收另一个 Region 需要花费 50ms, 能释放 20M 空间,G1 会优先回收后面的 Region
G1和CMS垃圾回收器的读写屏障
G1有读写屏障,CMS只有写后屏障,
详情见:https://blog.csdn.net/qq_40991313/article/details/130232389
分布式事务
参考:
https://zhuanlan.zhihu.com/p/183753774
https://blog.csdn.net/zhoupenghui168/article/details/130410815
2PC和3PC,TCC
2PC 和 3PC 都是数据库层面的事务,TCC 是业务层面的分布式事务
3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题, 3PC 相对于 2PC 做了一定的改进:引入了参与者超时机制,并且增加了预提交阶段使得故障恢复之后协调者的决策复杂度降低,但整体的交互过程更长了,性能有所下降,并且还是会存在数据不一致问题。
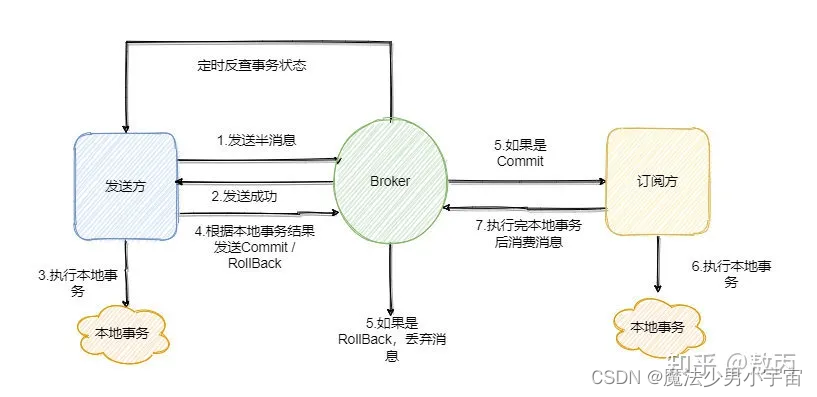
基于RocketMQ实现
- 第一步先给 Broker 发送事务消息即半消息,半消息不是说一半消息,而是这个消息对消费者来说不可见,然后发送成功后发送方再执行本地事务。
- 再根据本地事务的结果向 Broker 发送 Commit 或者 RollBack 命令。
- 并且 RocketMQ 的发送方会提供一个反查事务状态接口,如果一段时间内半消息没有收到任何操作请求,那么 Broker 会通过反查接口得知发送方事务是否执行成功,然后执行 Commit 或者 RollBack 命令。
IO
什么是NIO,NIO有哪些特点
原文链接 : https://blog.csdn.net/K_520_W/article/details/123454627
也可以参考: https://blog.csdn.net/qq_40378034/article/details/119710529
NIO 叫New IO 也叫 non-blocking IO,意思是同步非阻塞的IO,传统BIO必须一个线程处理一个客户端连接,线程在读写IO期间不能干其他事情,如果服务器一直没有数据传输过来,线程就一直阻塞.
而NIO中可以配置socket为非阻塞模式,使用selector(IO多路复用器),监听多个客户端的连接请求,每个请求都会有个用于传输数据的channel,读写数据针对buffer,channel没有数据时,也不会一直阻塞线程,而是根据事件去处理那些有数据的channel
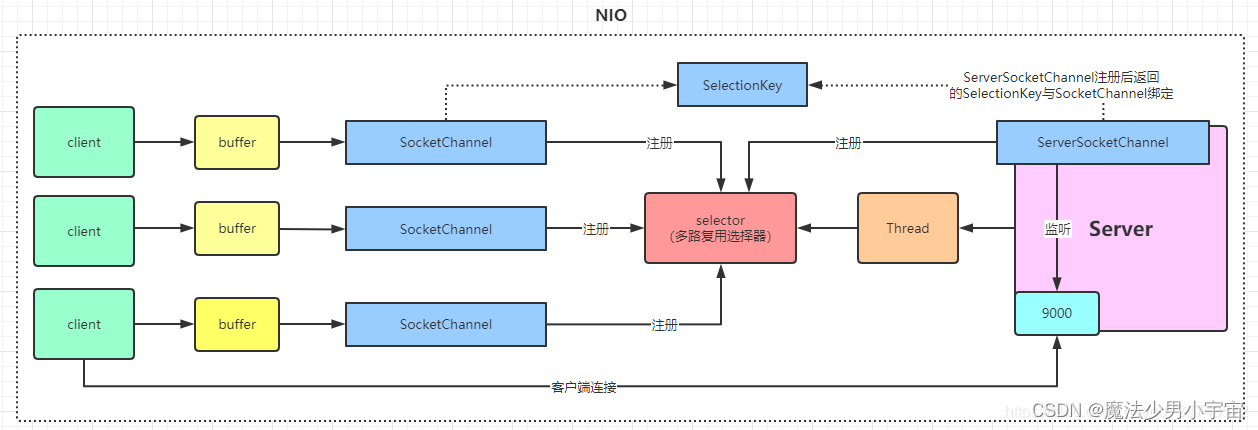
图片来源于: https://blog.csdn.net/qq_33743572/article/details/110209722
NIO和AIO的不同点
Java AIO(NIO 2.0)异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由操作系统先完成了再通知服务器应用去启动线程进行处理,
与NIO不同,当进行读写操作时,只须直接调用API的read或write方法即可,这两种方法均为异步的,对于读操作而言,当有流可读取时,操作系统会将可读的流传入read方法的缓冲区,对于写操作而言,当操作系统将write方法传递的流写入完毕时,操作系统主动通知应用程序
即可以理解为,read/write方法都是异步的,完成后会主动调用回调函数。在JDK1.7中,这部分内容被称作NIO 2.0,主要在Java.nio.channels包下增加了下面四个异步通道:
- AsynchronousSocketChannel
- AsynchronousServerSocketChannel
- AsynchronousFileChannel
- AsynchronousDatagramChannel
原文链接:https://blog.csdn.net/qq_40378034/article/details/119710529
NIO BIO AIO 各自适用场景
- BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解。
- NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
- AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。Netty!
多路复用什么意思
参考: https://blog.csdn.net/v123411739/article/details/124699602
参考2: https://blog.csdn.net/ChineseSoftware/article/details/123812179
零拷贝技术
参考 :
https://blog.csdn.net/weixin_44188399/article/details/137150788
https://blog.csdn.net/weixin_42096901/article/details/103017044
传统IO
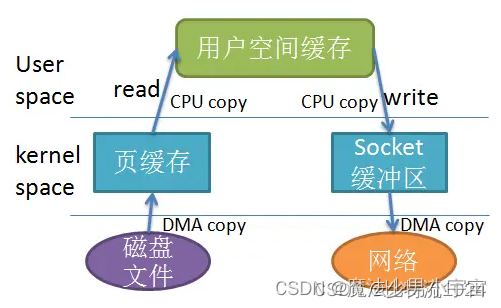
零拷贝的IO
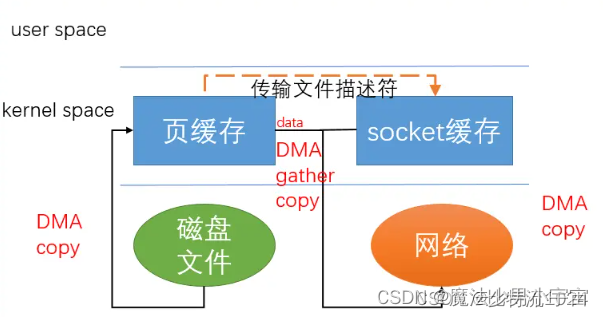
图片来源: https://blog.csdn.net/weixin_44188399/article/details/137150788
什么是DMA
参考: https://blog.csdn.net/qq_40989769/article/details/134900151
不需要CPU执行拷贝的拷贝技术,当需要拷贝时,CPU向DMA控制下下发拷贝指令,然后CPU干其他的去了,DMA将数据拷贝到内存后,向CPU发送中断,告诉已经拷贝完成了,这个时候CPU再次介入.
响应式什么意思,有什么特点
- 响应式流的两个核心特点:异步非阻塞,以及基于“回压”机制的流量控制
- 而事件驱动、数据流和异步编程是响应式编程的关键概念和组成部分
高并发
项目的高并发怎么解决的
- 前端cdn静态缓存
- nginx负载均衡
- 容器水平服务扩展
- 响应式mvc 异步非阻塞
- dynatrace动态流量和响应监控
- 超过阈值流量进入等待页面(限流)
高并发有哪些解决方案
1.限流,熔断,降级,缓存
- 前端cdn缓存,静态资源缓存
- nginx做负载均衡
- 服务水平扩容
- 读写分离,es查询,mysql落库
- MQ异步
- redis集群和热点数据缓存
- zookeeper/redisson分布式锁保证原子性
- rocket分布式事务保证事务
- mysql集群,主从复制
- 页面滚动分页 ,避免深度分页,跳页
高并发下,电商项目中的读写分离怎么做的,数据怎么保持同步的 todo
这个实际我们就是es查询,mysql落库,但是我只负责es的查询, 落库的操作确实不是我这边处理的,我能想到的就是
杂项
jdk8以上的特性了解哪些
我能记的到的
- var 写变量
""" """表示文本块,不再需要使用转义字符- 设置G1为JVM默认垃圾收集器 9
- Optional新增orElseThrow()
try-with-resources资源的书写顺序
资源关闭会按声明时的相反顺序被执行
SpringMVC和响应式编程的特点和差异
- 命令式的、同步阻塞【spring-webmvc + servlet + Tomcat】
- 响应式的、异步非阻塞【spring-webflux + Reactor + Netty】
设计模式
DDD了解吗,他的层级是什么样子的 todo
DDD中entity和vo的关系和异同 todo
补充知识点:
Spring & Springboot
spring IOC的底层原理
首先IOC叫做控制反转,把之前需要自己new出来的对象可以统一交给第三方(容器管理),实现低耦合的目的,反转体现在对依赖对象的管理变成了从IOC自动注入,IOC也被叫做DI(依赖注入)
底层实现:解析xml或者注解,通过反射的方式创建对象,并且放在容器中
springAop的底层原理
aop,即是面向切面编程,核心目的是在不嵌入耦合原业务代码的基础上,实现额外的功能.使用的话定义好切面和切点和通知方法,
从源码中我们也可以大概梳理一下aop的流程,
1.首先一个启用AOP的注解 @EnableAspectJAutoProxy,他会给容器注册一个
AnnotationAwareAspectJAutoProxyCreator,
2.该类的作用是在bean创建的流程中,实例化之后初始化之前调用beforeInstanation,尝试返回一个对象或者代理对象,
3.实例化之后调用afterInstanation,根据wrpaifnessary判断是否需要创建一个代理对象,判断逻辑是先查找该类是否有满足条件的增强方法,如果有对这些方法排序,
4.有增强方法则创建代理对象,根据目标类是实现的接口(jdk)还是无接口(cjlib)创建代理对象,
5.执行时,根据方法拦截器,通过代理对象调用执行对应通知方法和实际方法
spring事务的底层原理
利用@EnableTransactionManagement导入两个组件
1.一个autoproxyRegister,跟aop一样用于在实例化之后生成一个代理对象,
2.ProxyTransactionManagementConfiguration,给容器中注册事务增强器,包括事务方法拦截器是事务管理器
3.执行带事务的方法的时候,就会进入方法拦截器中,根据执行目标成功与否选择提交或者回滚事务
Springboot自动配置原理
@SpringbootApplication注解为入口,该注解点进去还有几个注解,核心是将项目下的有注解的类和META-INF/spring.factories(spi机制)中获取各个组件的自动配置类的全限定名,根据条件condition,统统加入bedefination中,然后根据spring创建bean的流程,自动将bean纳入spring的管理中.其中自动配置类的属性都会在对应的properties文件中定义
自定义starter
官方的STARTER – SPRINGBOOT-STARTER-XXX
自定义的STARTER XXX-SPRING-BOOT-STARTER
- xxx-spring-boot-starter只用来做依赖导入,pom中依赖自动配置模块
- xxx-spring-boot-starte-autoconfigure 具体的业务逻辑
SpringMVC中什么部分用到了什么设计模式
- 简单工厂模式
Spring中用到的简单工厂模式就是我们经常用到的BeanFactory。 - 工厂方法模式
Spring中用到的工厂方法模式就是FactoryBean。 - 适配器模式
Spring中的拦截器就用到了适配器模式。
*装饰器模式(包装器模式)
Spring中的各种Wrapper和Decorator就用到了装饰器模式。 - 代理模式
Spring中的AOP就用到了代理模式,代理模式有两种实现:JDK动态代理、Cglib动态代理。 - 观察者模式
Spring中的ApplicationListener就用到了观察者模式 - 策略模式
Sping在实例化对象的时候就用到了策略模式 - 模板方法模式
Spring中的JdbcTemplate、RestTemplate、RedisTemplate
…
Java基础
java多线程,执行interrupt()方法后会发生什么?对于抛出异常后,若一直没有人处理,异常会一直一直向上抛,最后会怎么办?
打断阻塞状态的线程 (wait join sleep)会清空打断标记
正常运行的线程被打断不会真正被打断,只会设置打断标志,可以用打断标志位判断是否该停止线程
如果异常未被处理,最终被jvm的默认异常捕获,并打印堆栈信息,如果是在锁里,可能导致死锁,阻塞代码
java多线程,执行sleep()函数后会发生什么?
1. 线程变为阻塞状态
2. 并且有锁的情况下也不会释放锁
你在什么情况下会用到equals和hashcode
equals一般会在比较对象时使用,比较的是对象的地址值,
hashcode一般会在散列表的比较中使用,比如hashtable,hashset,hashmap, 放数据都是先根据hash出得值计算桶的位置
比如hashmap,存储的是一个对象,先比较hashcod是否相同,hashcode相同则比较equals,二者皆相同表示数据重复,会覆盖数据,所以重写了equals最好重写hashcode,保证equals相同则hashcode一定相同
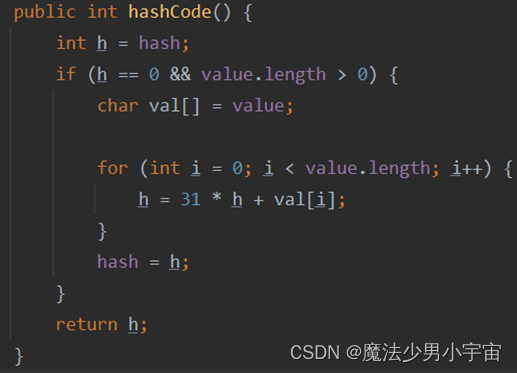
int类型和String类型的hashCode分别是什么
int类型的hashcode就是int的值本身
String的hashcode
mysql
mysql数据库隔离级别
- 读未提交(存在脏读幻读不可重复读)
- 读已提交 (解决脏读)
- 可重复读(解决脏读 不可重复读)
- 串行化(解决脏度幻读不可重复读)
可重复读实现原理(MVCC)
解决方式是通过mvcc快照方式
快照的实现:
- 首先数据库行会有隐藏的列,包括行id,回滚指针,事务id,回滚指针指向undolog
- 快照的话主要是 活跃事务id 最小事务id 将分配事务id,和创建快照的事务id
通过对比数据的事务id 确定数据可不可见
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
1)如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
2)如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。
3)如果被访问版本的trx_id属性值大于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。
4)如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问
innodb执行引擎和MyIsAm执行引擎的区别
- 对事务的支持,myisam不支持事务
- 查询总数时myisam有专门的的列保存count 直接返回
- 锁的支持 myisam不支持行级锁,只支持表锁
- Innodb是聚簇索引,myisam不是, MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
- Innodb必须有唯一键
- MyISAM数据恢复困难
数据库索引的实现原理?B+树和红黑树的区别
目前mysql常用的索引数据结构为
FULLTEXT,HASH,BTREE,RTREE
Innodb和myisam都选择了B+树, 但是Innodb的主键索引是聚簇索引,而辅助索引才是非聚簇索引, myisam都是非聚簇索引,聚簇索引就是在叶子节点会保存数据,非聚簇只会保存指向主键和对应的索引列/或者地址值,聚簇索引的查询更高效,不需要回表,范围查询更友好,因为聚簇索引一般使用自增的id做主键,且相邻节点是双向链表结构,范围查询更高效,如果主键不是自增id的话,可能导致页分裂的情况,使索引维护成本增加,查询缓慢
为什么用B+树而不是红黑树和B树呢?
首先B+树是B树的升级版,在B树的基础上,只有叶子节点保存数据,并且相邻节点互相指向形成了双向链表,使范围查询更加快速, 而且B树支持多路存储,数据量太大时不一定能一次性加载到内存中,这样就可以一次只加载一个节点内容来查找,所以在内存中红黑树可能会更快,但是考虑到内存,还是选择B+树
数据库索引有哪些?主键索引和唯一索引的区别?
主键索引(同唯一索引,数据不重复,且以主键作为索引)
唯一索引(数据不能重复,联合唯一索引也不能重复,允许有空值)
普通索引(数据可重复,普通单个索引和联合索引)
全文索引(只能用于myisam, char,varchar,text)
网络
http1.0和http1.1的区别?
原文: https://blog.csdn.net/wtl666_6/article/details/128697770
- 新增长连接(流水线和非流水线两种模式)
- 新增状态响应码409,410,
- 新增断点续传
- 新增range报头,允许部分响应
- Cache-control
Http2.0支持IO多路复用,和服务器主动push到c端
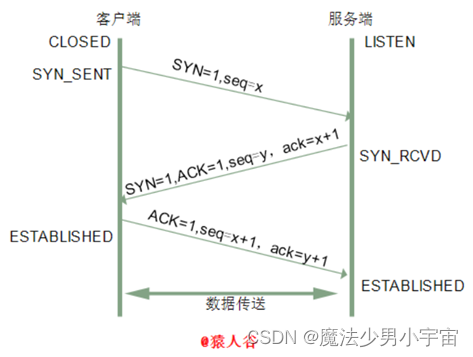
画三次握手,四次分手的图
参考: https://blog.csdn.net/hyg0811/article/details/102366854
三次握手
四次挥手
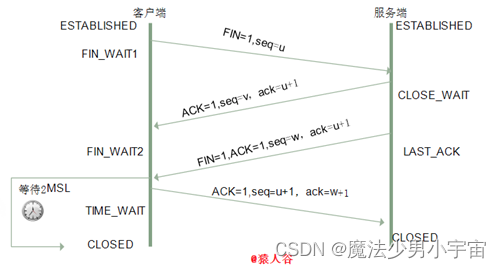
四次挥手释放连接时,等待2MSL的意义?
MSL是MaximumSegmentLifetime的英文缩写,可译为"最长报文段寿命”,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
为了保证客户端发送的最后一个ACK报文段能够到达服务器。因为这个ACK有可能丢失,从而导致处在LAST-ACK状态的服务器收不到对FIN-ACK的确认报文。服务器会超时重传这个FIN-ACK,接着客户端再重传一次确认,重新启动时间等待计时器。最后客户端和服务器都能正常的关闭。假设客户端不等待2MSL,而是在发送完ACK之后直接释放关闭,一但这个ACK丢失的话,服务器就无法正常的进入关闭连接状态。
两个理由:
- 证客户端发送的最后一个ACK报文段能够到达服务端。
这个ACK报文段有可能丢失,使得处于LAST-ACK状态的B收不到对已发送的FIN+ACK报文段的确认,服务端超时重传FIN+ACK报文段,而客户端能在2MSL时间内收到这个重传的FIN+ACK报文段,接着客户端重传一次确认,重新启动2MSL计时器,最后客户端和服务端都进入到CLOSED状态,若客户端在TIME-WAIT状态不等待一段时间,而是发送完ACK报文段后立即释放连接,则无法收到服务端重传的FIN+ACK报文段,所以不会再发送一次确认报文段,则服务端无法正常进入到CLOSED状态。 - 防止“已失效的连接请求报文段”出现在本连接中。
客户端在发送完最后一个ACK报文段后,再经过2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现这种旧的连接请求报文段
为什么TIME_WAIT状态需要经过2MSL才能返回到CLOSE状态?
理论上,四个报文都发送完毕,就可以直接进入CLOSE状态了,但是可能网络是不可靠的,有可能最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。
SYN泛洪攻击的应对
缩短超时(SYN Timeout)时间
增加最大半连接数
过滤网关防护
SYN cookies技术
UDP和TCP的区别?
TCP和UDP都属于TCP/IP协议族
UDP和TCP的不同
- TCP是面向连接的,UDP是面向无连接的
- TCP是可靠的,UDP是不可靠的
- TCP是面向字节流的,UDP是面向报文的
- TCP只有一对一的传输方式,而UDP不仅可以一对一,还可以一对多,多对多
- UDP的头部开销小,TCP的头部开销大2.6TCP会产生粘包问题,UDP会产生丢包问题
- TCP粘包(粘包问题的最本质原因在与接收对等方无法分辨消息与消息之间的边界在哪)
- UDP丢包问题(UDP是没有应答和重传机制,因此包很容易传丢了也不知道)
主要丢包原因:接收端处理时间过长导致丢包:调用recv方法接收端收到数据后,处理数据花了一些时间,处理完后再次调用recv方法,在这二次调用间隔里,发过来的包可能丢失。对于这种情况可以修改接收端,将包接收后存入一个缓冲区,然后迅速返回继续recV。发送的包巨大丢包:虽然send方法会帮你做大包切割成小包发送的事情,但包太大也不行。例如超过50K的一个udp包,不切割直接通过send方法发送也会导致这个包丢失。这种情况需要切割成小包再逐个send。.发送的包较大,超过接受者缓存导致丢包:包超过mtu size(mtu表示最大传输单元)数倍,几个大的udp包可能会超过接收者的缓冲,导致丢包。这种情况可以设置socket接收缓冲。以前遇到过这种问题,我把接收缓冲设置成64K就解决了。4.发送的包频率太快:虽然每个包的大小都小于mtusize但是频率太快,例如40多个mutsize的包连续发送中间不sleep,也有可能导致丢包。
Springcloud
熔断限流和降级
参考: https://blog.csdn.net/BruceLiu_code/article/details/129122169
限流和熔断最终都会通过降级实现
熔断
调用三方服务, 出现超时/错误率过高/错误次数过多时,采用不调用三方服务(熔断),走自己的fallback逻辑(降级)
Closed状态: 来自应用程序的请求被 Proxy 操作。Proxy 维护最近故障次数的计数,如果对操作的调用不成功,Proxy 会增加这个计数。如果在给定的时间段内最近故障的次数超过了指定的阈值,Proxy 将进入Open状态。此时,Proxy 启动一个超时计时器,当计时器到达阈值时,Proxy 将进入Half-Open状态。(这里 Proxy 代指 Resilience4j、Sentinel、Hystrix类似框架)
Open状态: 来自应用程序的请求立即失败,并向应用程序返回异常。
Half-Open状态: 应用程序允许有限数量的请求通过并调用操作。如果这些请求成功,假定之前导致失败的故障已经修复,将切换到Closed状态(故障计数器被重置)。如果任何请求失败,会认为故障仍然存在,因此它会回退到Open状态,并重新启动超时计时器,为系统提供进一步的时间来从故障中恢复。
原文链接:https://blog.csdn.net/weixin_47189009/article/details/131966565
限流
比如说A能承载的连接数为5,但是目前的并发有6个请求同时进行,前5请求能正常请求,最后一个会直接拒绝,执行fallback降级逻辑
以下是常见的限流算法:
固定窗口计数限流算法(Fixed Window Counter): 在固定的时间窗口内,限制请求的数量。例如,在1秒内最多允许处理10个请求,当窗口满时,后续请求将被拒绝。
滑动窗口计数限流算法(Sliding Window Counter): 设置一个滑动时间窗口,计算在该时间窗口内的请求数量,并限制其在指定范围内。与固定窗口计数算法相比,滑动窗口算法允许更加灵活的流量控制。
令牌桶算法(Token Bucket): 令牌桶算法通过将请求放入令牌桶中来控制流量。每个请求需要从令牌桶中获取令牌,如果桶中没有足够的令牌,则请求被拒绝。令牌桶算法允许突发流量一定程度的处理,并平滑了请求的速率。
原文链接:https://blog.csdn.net/weixin_47189009/article/details/131966565
降级
fallback逻辑
分布式高并发商城
秒杀系统设计
原文:https://blog.csdn.net/qq_35190492/article/details/103105780
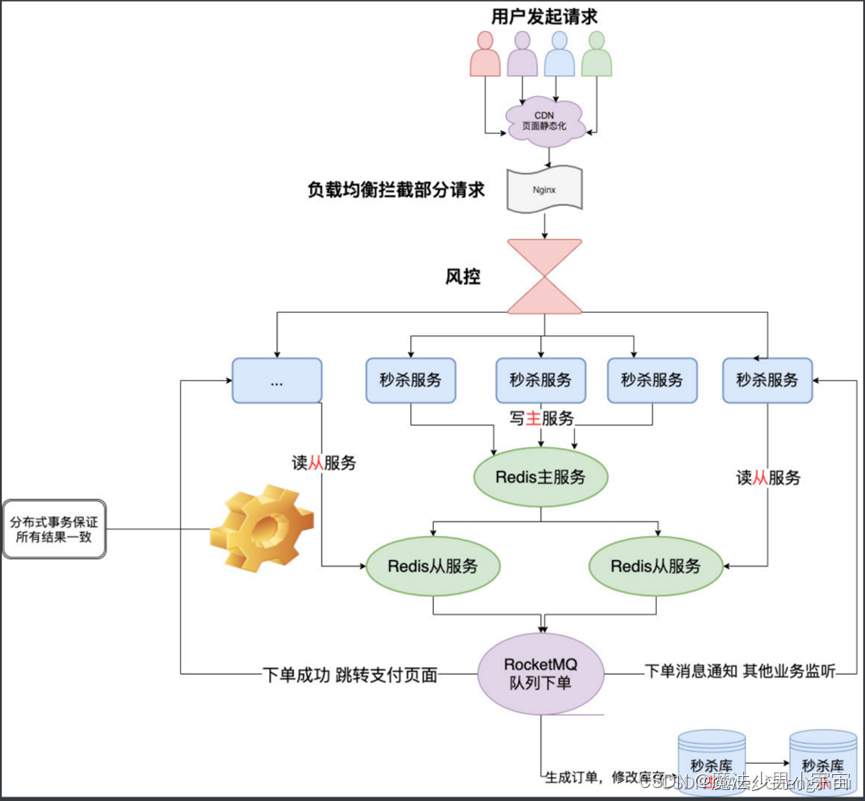
大促系统设计
如何防止超卖
库存扣减的时机
参考 https://blog.csdn.net/weixin_41605937/article/details/125762408
下单减库存
优势: 下单减库存是最简单的减库存方式,也是控制最精确的一种
劣势: 竞争对手通过恶意下单的方式将该商品全部下单,导致库存清零,恶意下单的人是不会真正付款的
付款减库存
优势: 一定实际售卖
劣势: 因为下单时不会减库存,可能出现200人下单只有100人能成功支付的情况,用户体验不好
预扣库存(推荐)
优势: 一定程度缓解上面两种方式的劣势
劣势: 针对恶意下单的场景,虽然可以把有效付款时间设置为 10 分钟,但恶意买家完全可以在 10 分钟之后再次下单
完整流程
- 前端限流(置灰,答题,图形验证码等多种方式)
- nginx负载均衡到不同的秒杀服务节点(负载均衡)
- 风控
- 后端sentinel限流,比如允许1000个请求进来,多余请求走降级逻辑,比如服务忙,重试等
- redis单机,预减库存,lua就可以(先查有无库存,有库存则减)
- 支付成功的发mq,mysql实际减库存(秒杀成功表下单信息 用户id和商品id做唯一索引,避免重复下单,更新库存时使用乐观锁,并且设置库存为无符号整数,保证库存一定不为负数)
- 定时任务跑支付失败的和支付超时的,恢复mysql库存
- redis中的库存下于0则秒杀结束
集合面试题
原文: https://blog.csdn.net/qq_45966440/article/details/122284123


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









