







索引概述
大纲

1、什么是索引
索引是一种帮助MySql高效获取数据的数据结构
1、mysql无索引的情况
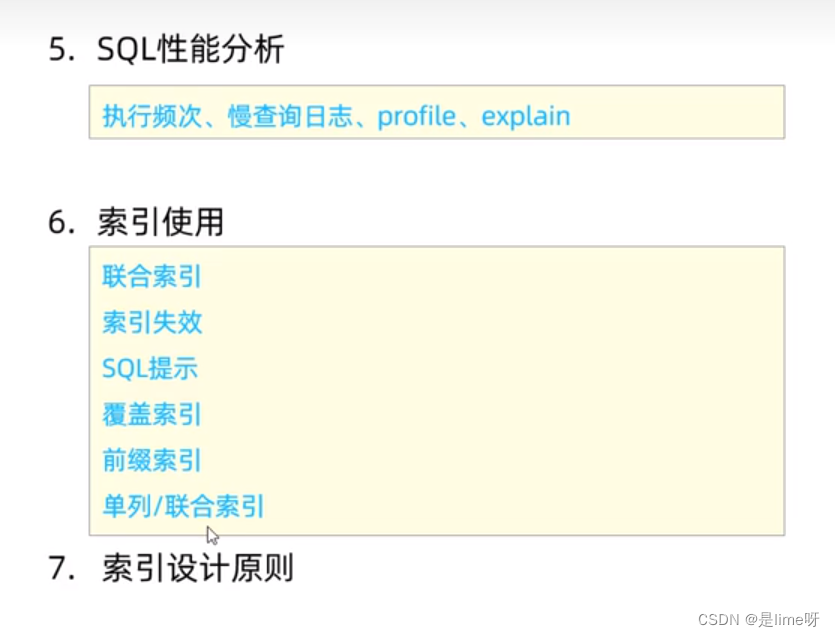
select * from user where age = 45
当数据库执行该语句时,会对全表进行扫描(即使找到一个数据,依旧会向下继续扫描,因为全表age=45的数据不一定只有一条),效率极低

2、mysql有索引的情况
如果要对age字段建立索引(例如二叉搜索树,并不是mysql真实的数据结构),根据age字段的数据建立二叉搜索树,查找时按照二叉搜索树的查找方法进行查找,45 ->36(走右子树),当找到45时,根据指向返回该条数据
2、索引的优缺点
- 优点
- 提高数据检索的效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗
- 缺点
- 索引列需要占用磁盘空间(MYI文件主要存储索引,account.ibd也会存储)
- 降低更新表的效率,当insert、update、delete时需要维护索引的数据结构(当insert时需要向索引结构中添加数据,update、delete都需要改变),影响增删改的效率
- 但是对于这两点缺点来说可以忽略不急,对于一个正常的业务系统来说,增删改的比例很小,主要是查询

2、索引结构
1、索引结构分类

2、不同的存储引擎对索引的支持情况

3、Innodb的B+树索引结构
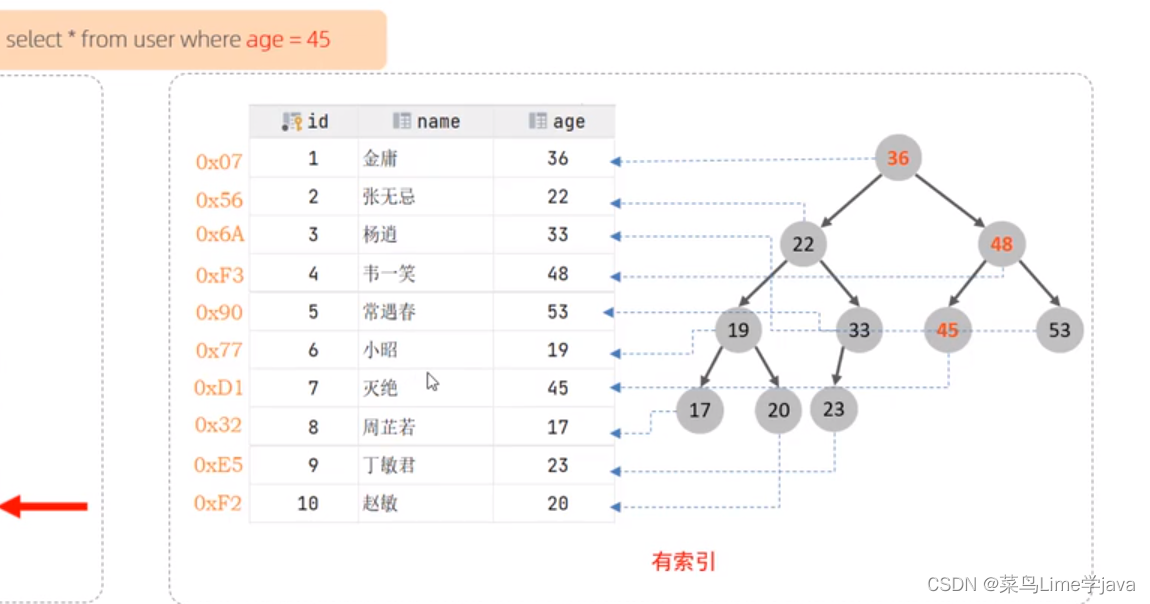
1、二叉树
2、B树
B树:B 树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树
B树的意义——减少磁盘访问次数
一棵m阶的B 树 (m叉树)的特性如下:

- 树中每个结点最多含有m个孩子(m>=2);
- 除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
- 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
- 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null);(读者反馈@冷岳:这里有错,叶子节点只是没有孩子和指向孩子的指针,这些节点也存在,也有元素。@JULY:其实,关键是把什么当做叶子结点,因为如红黑树中,每一个NULL指针即当做叶子结点,只是没画出来而已)。
- 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,…,Kn,Pn)。其中:
a) Ki (i=1…n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
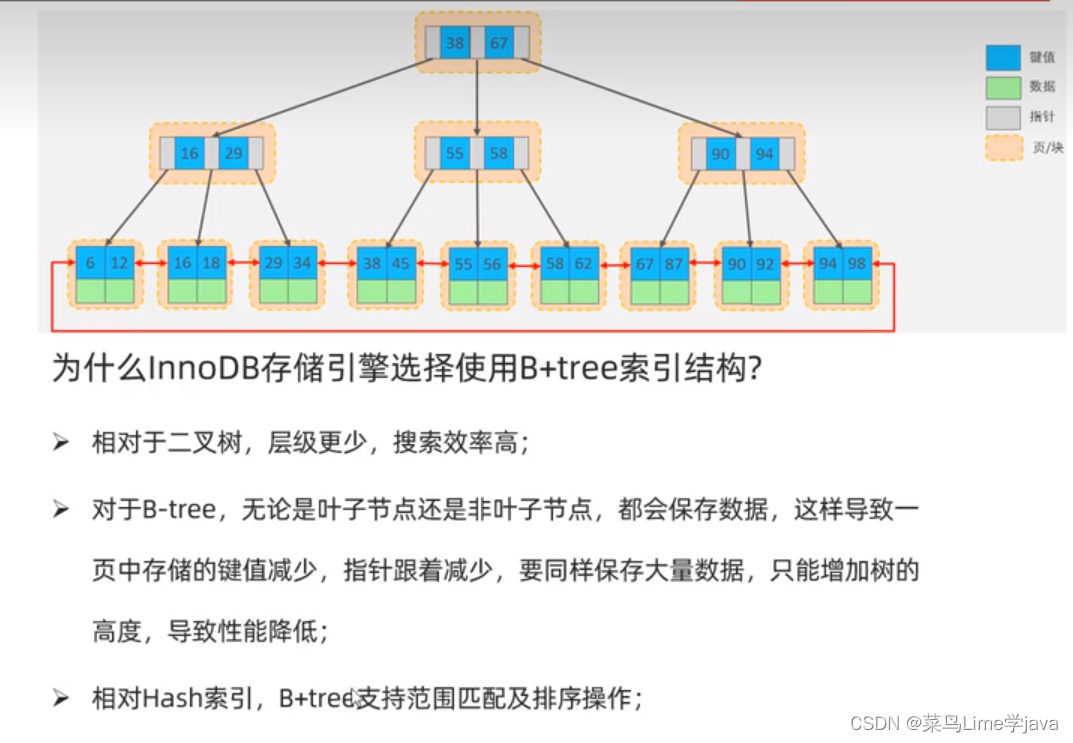
3、Mysql中的B+树(改进后的B+树)
特点:
- 所有的数据都会出现在叶子节点
- 非叶子节点只起到索引数据的效果,不存储具体的数据
- 数据存储在叶子节点
- 每一个节点存储在数据块中,也叫页,innodb的逻辑存储结构,表空间、段、区、页,一页的大小16kb,
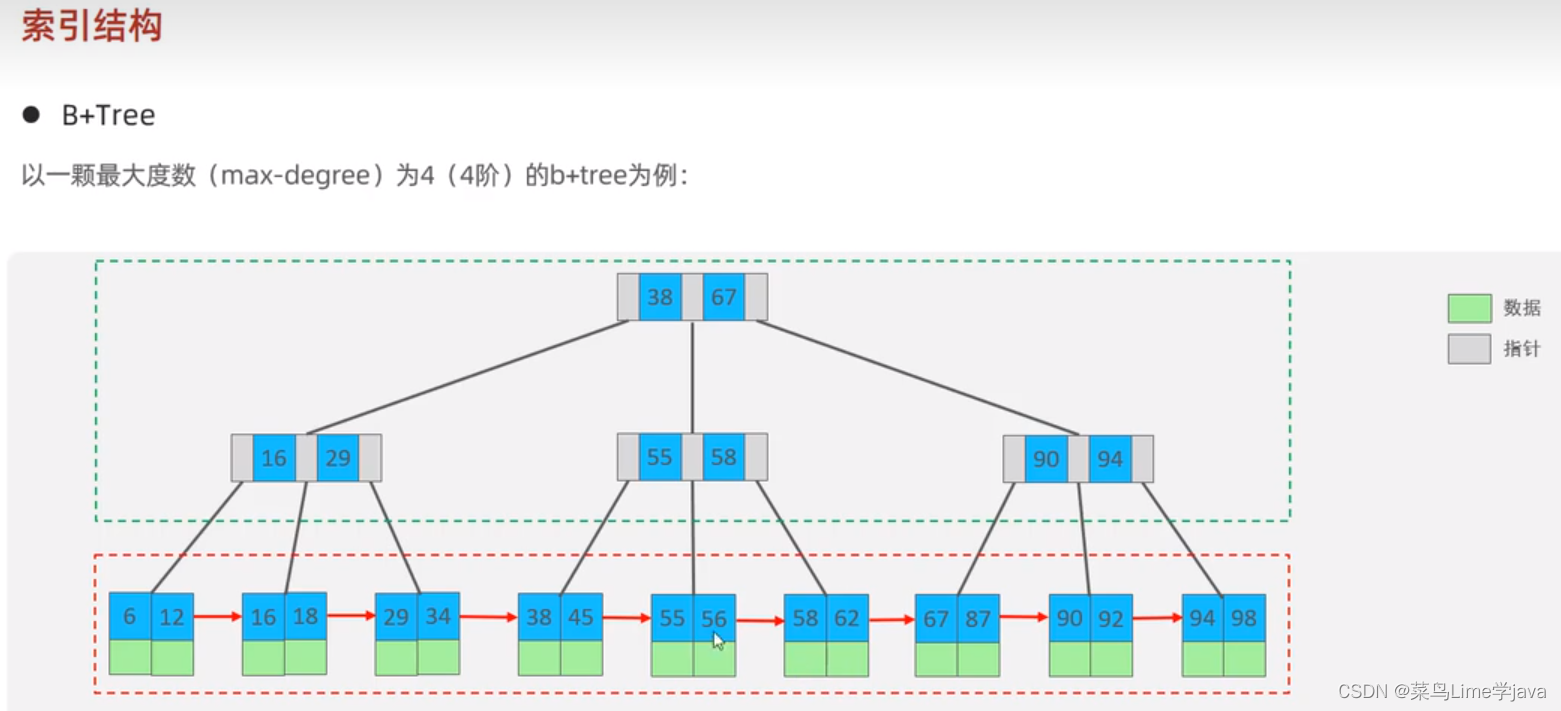

改为双向链表后便于搜索和排序
4、hash

面试问题:为什么InnoDB存储引擎使用B+树索引
3、索引分类
3.1 索引分类
- 主键索引(PRIMARY):只能有一个
- 唯一索引:表中某列数据不能重复
- 常规索引
- 全文索引

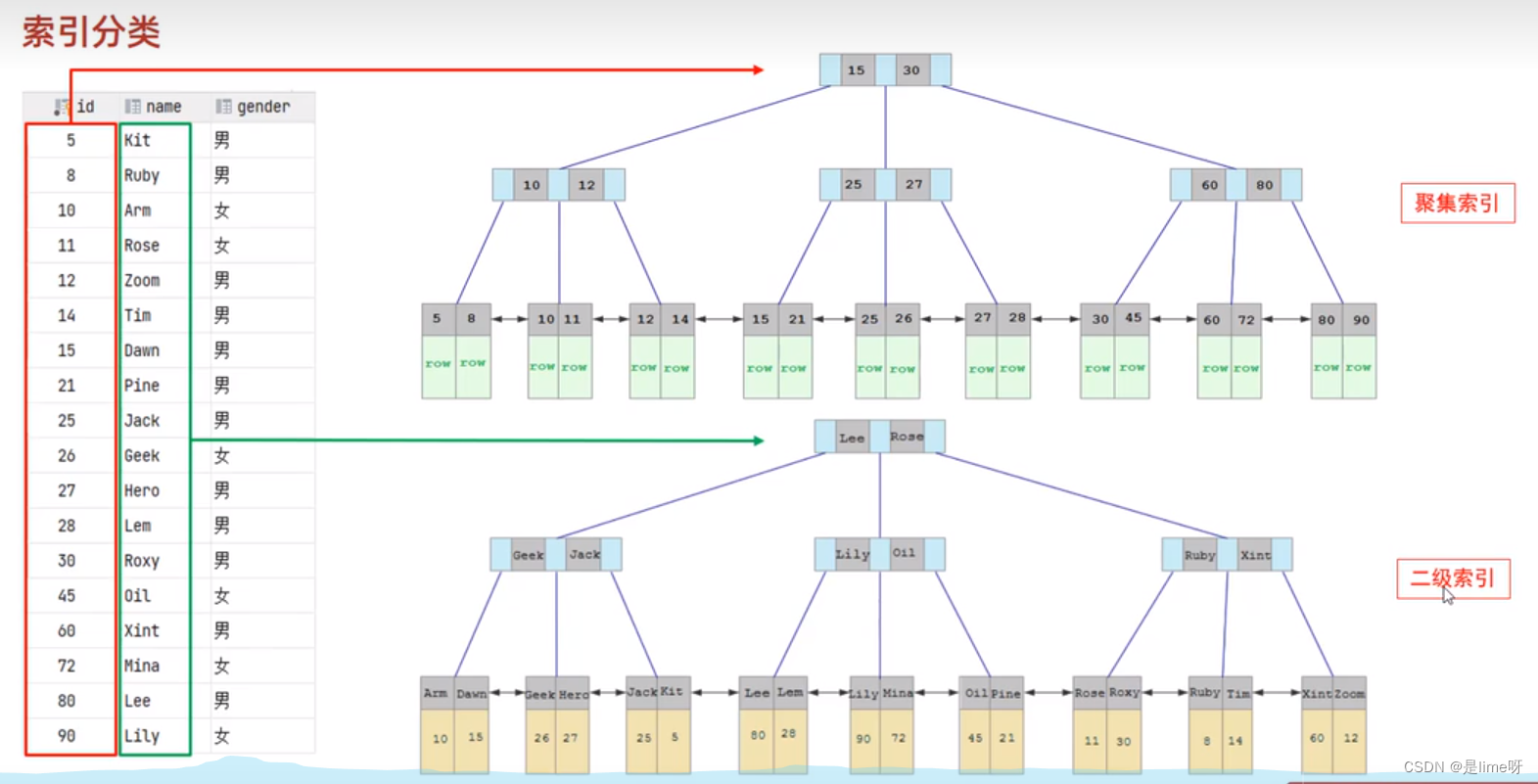
3.2 聚簇索引与非聚簇索引(二级索引)
InnoDB索引根据存储的结构又可分为:聚簇索引和非聚簇索引

聚簇索引叶子节点存储的是一行的值,二级索引叶子节点存储的是对应的id值,当查询数据时,在二级索引中查询到对应的id值,再到聚集索引中查询对应的数

4、数据库的索引失效有哪些
-
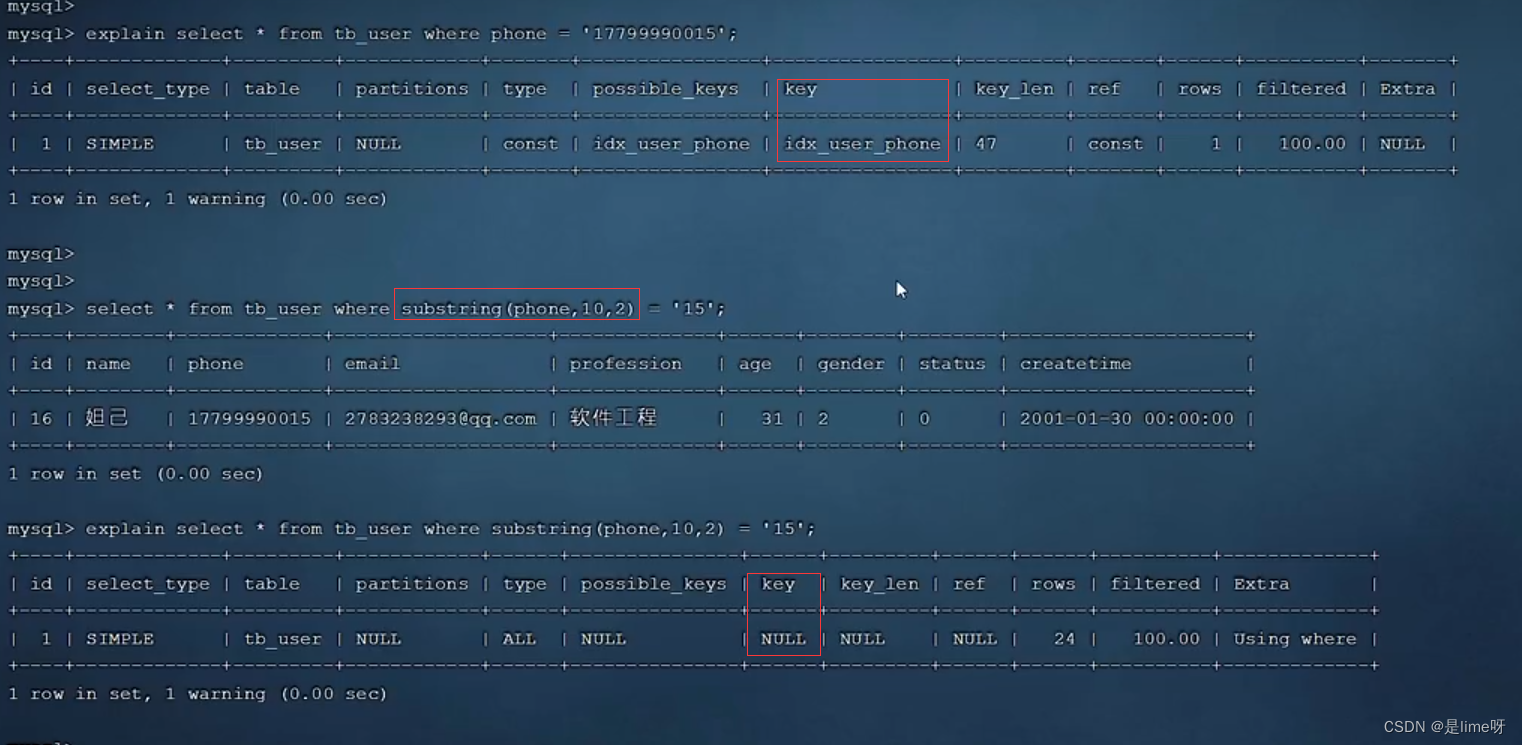
1、在索引列上进行运算操作
select * from tb_user where substring(phone, 10, 2) = '15此时该语句的执行没有使用索引
-
2、字符串没有加引号
字符串类型字段使用时不加引号,索引失效
情况一:select * from tb_user where phone = 17799990015

情况二:联合索引某个字符类型字段使用时没有加引号


-
3、进行模糊查询,如果仅在末尾进行模糊匹配,索引不会失效,如果在头部模糊匹配,索引失效
3.1在尾部进行模糊匹配,索引不失效
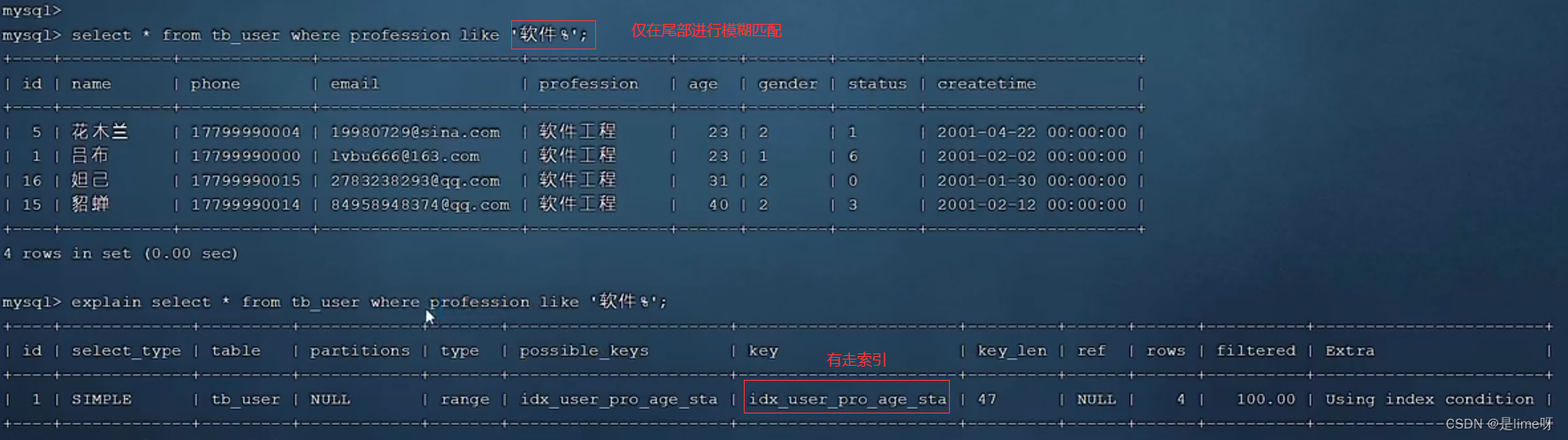
3.2在头部进行模糊匹配,索引失效

3.3前后都模糊也失效 -
4、or连接的条件
用or分割开的条件,如果or前的条件的列有索引,or后的条件的列没有索引,则涉及的索引都不会被用到

解决方法,在该字段上建立索引

-
5、当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效。
如果mysql估计使用全表扫描要比使用索引快,则不使用索引

-
6、在索引列上使用 IS NULL 或 IS NOT NULL操作。
索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可。(此处是错误的!)

-
7、在索引字段上使用not,<>,!=。
不等于操作符是永远不会用到索引的,因此对它的处理只会产生全表扫描。 优化方法: key<>0 改为 key>0 or key<0。

索引使用
1、SQL提示

2、覆盖索引
查询返回的列在索引中都包含了,不需要再回表查询
创建一个索引,该索引包含查询中用到的所有字段,称为“覆盖索引”。
使用覆盖索引,MySQL 只需要通过索引就可以查找和返回查询所需要的数据,而不必进行回表操作。
- mysql覆盖索引和联合索引的区别
- 覆盖索引是指查询的列可以直接通过索引提取,比如只查询主键的列!或者查询联合索引的所有列或者左边开始的部分列(注意有顺序的)!
- 联合索引并不一定只从索引中能获取到所有的数据,这个取决于你所查询的列。比如select * from table where ××××××;的方式就不太可能是覆盖索引。因此如果你查询的列能用到联合索引,且你查询的列都能通过联合索引获取,比如你只查询联合索引所在的列或者左边开始的部分列,这就相当于覆盖索引了。通常为了让查询能用到覆盖索引,就将要查询的多列数据设置成联合索引。


3、回表查询
在查询时,先走二级索引查询到这行数据的id值,再根据id值在聚簇索引中查询
4、前缀索引
使用场景:当遇到一些字符串长度较长或大文本字段时,可以在这些字段上建立前缀索引,缩小索引的体积,减小检索的效率
很多情况下,我们需要根据一个长字符串类型的字段去查找记录,比如身份证,邮箱,为了避免全表扫描,就需要为字符串字段添加索引,当要索引的列字符很多时 索引则会很大且变慢。
选择一个字段的部分字符作为索引,往往是针对过长字符型字段建立,这样建立起来的索引更小,所以查询起来更快
//整个字段
alter table T add index index1(email)
//前缀索引
alter table T add index index1(email(6))
5、单列和联合索引
- 单列索引:一个索引只包含了一个字段
- 联合索引:一个索引包含了多个字段
在业务场景中,如果有多个查询条件,考虑对查询条件建立索引时,建议建立联合索引,而非单列索引
索引的设计原则

















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









