







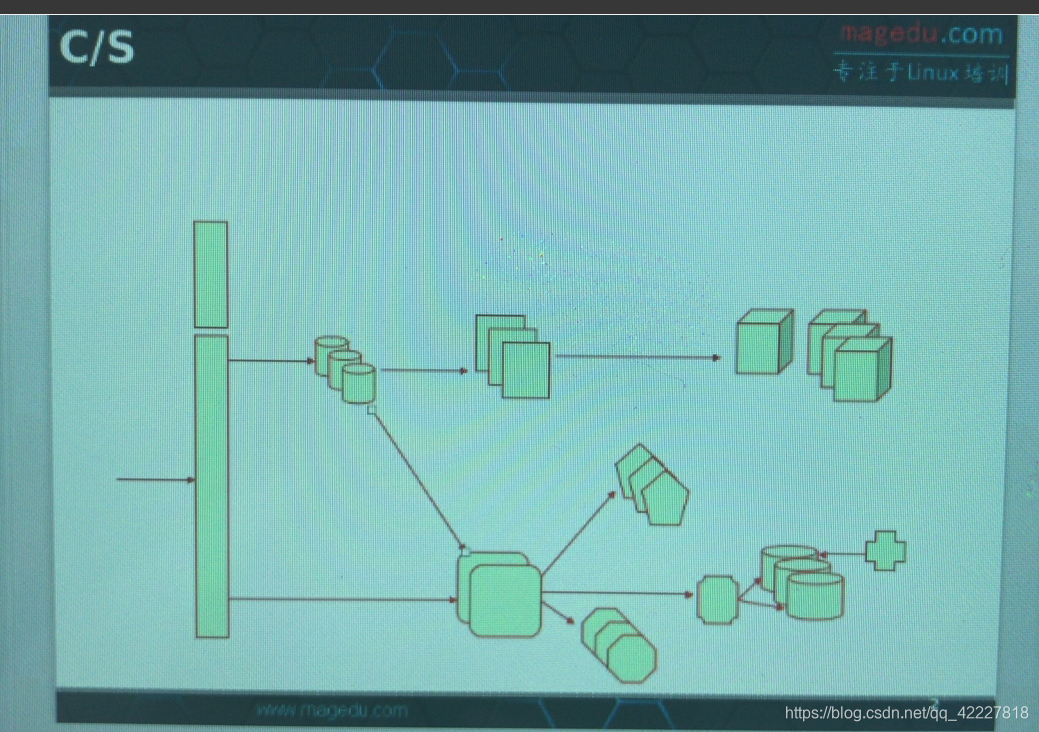
一个典型的站点,他的组成格式,我们大体很多环节已经完成了,
用户请求首先会到整个系统的接入段(通常是负载均衡器,所有应用都是通过http协议提供的,客户都安只需要通过浏览器就能访问应用,而现在的大多数应用都是类似于所谓的c/s结构的,尤其是服务端各种应用,包括移动段的的,大多数都是c/s,也是基本上基于http协议
现在的开发岗位也就是所谓的两大类,如果并不涉及到硬件本身,无非就是常见的前端开发,后端开发,(称为服务端)
还有应用开发(或者前后端开发,移动端开发),事实上这几种应用当中,前端和后端无非是在服务端当中利用美观的界面,并且能基于业务逻辑来处理用户请求并响应的这么一种组合方式,而对移动端来讲,无非是开发能够部署在用户移动设备上,同时也能通过网络协议连接至服务端进行交互的,展示方式不再是简单地看到的通过浏览器,css,js简单部署出来的这么个界面
而移动端开发,基于交互式设计组合起来的等等地一种展示方式,多数都是cs架构的,最主流的协议尤其是接入的时候,当属http协议,因此用户无论是通过移动端访问还是pc端接入通常而言都是通过http协议的,或者对应移动端的专用协议,向服务端发送请求,
而对服务端而言需要承载大量的并发用户链接,很显然,我们就需要调度,接入层,用于实现将用户请求分发至多个能处理用户请求到后端来实现
我们的资源大体分为两类,动态和静态,
动态的资源通常占比比较小,但执行速度会很慢,如果能做缓存的话,能实现更加高效的加速的效果,但是对静态内容来讲,更适合做缓存的
所以应该有一个缓存层,之前的的解决方案varnish,对站点来讲,有些资源用户不删除将会一直存在(指的是跟用户相关的数据而不是跟站点资源相关的内容,这个内容主要以图片和用户所生成的数据为主,
(如果是一个电商站点,有大量对应的商家,会上传很多图片,会生成很多描述性文字,这些分别保存在哪里,
先要存下来,还要用户请求时能给予展示)
如果是纯粹用户生成的数据这样的内容,一般而言要分为3类,结构化数据,半结构化数据,非结构化数据
所谓的结构化数据,一般存在关系型数据库中,以mysql为例,一般要扩展,需要做主从,做了主从,前面就要做读写分离,实现用户的请求分发至合理主机,一旦主机宕机,将会导致整个存储不可用,或者是写操作不可用
所以就需要一个MHA来提升一个从节点自动将其提升为主节点,这是结构化的数据
非结构化的数据,(如用户上传的图片,)/通常把这些非结构化数据放到存储上,每一副图片,存储方式,可以放在简单的文件系统里,事实上也可以放在对象存储系统上,让每一个数据,元数据和单独数据都存放在一起,而不像传统的文件系统,元数据有一个区域,数据有一个区域,靠总体的方式来管理,这种一般称为对象存储系统
为了使得前端的多个请求能高效并发,无论磁盘IO还是网络IO都不至于形成瓶颈,通常用一个分布式的对象存储,或者是文件系统来存储,分布式存储(可能是个文件系统,也可能是一个存储本身)
既然是分布式就有可能有中心节点,也有可能无中心节点,但是文件系统本身的数据是不可能跟缓存系统varnish进行交互的,varnish进行反代时也只能发出http请求,如果整个存储系统本身,拥有http接口,那就可以之接交互了,如果不能就需要加一个中间层,这个中间层向varnish一侧提供http协议,向存储端使用存储协议,这是一个转接器,可以这么去理解,
这个转接器可以用著名的web服务来提供如nginx,nginx可以基于模块来适配其他的协议,比如适配fastcgi协议,还包括memcached,如果能给nginx打一些补丁,能适配更多存储协议,需要安装第三方模块,很多存储的确提供了这些第三方模块,
因此用户的请求到达varnish以后,可以反代给nginx,由nginx反代存储系统,如果存储系统能有一个统一的http接口,那就更加简单了,但多数情况下,都需要一个前端的反代,反代如果一个不够,一样需要做负载均衡做多台主机,这就是用户生成的数据的第二类,非结构化数据,
用户的访问还有可能生成第三类数据,如web服务器访问的日志,并发非常,日志生成速率也会非常高,这些数据存哪里,一般是放在本地文件系统之上,
但是放在本地文件系应有几个问题,
1.文件系统的存储能力差
2.web服务器有多台,如果想做日志的统一存储和分析,显然放在本地单台主机是很难做到的,有isyslog可以做统一的日志
存储服务器,isyslog存储依然是放在存储文件之上的,将来想做高效解析(如ip地址访问了哪些资源)将无法进行,这个时候通常要将这些信息放置在存储系统中,用户浏览站点后,站点肯定有数据处于白热化的访问呢
比如有一个商品,访问特别高,交易量非常高,就需要显示交易多少笔了,就需要用户在打开这个商品的时候给它一个数字,成交了多少笔 ,这些数字都需要快速修改的,通常只是个计数器,一般放置在关系型数据库当中,一次写操作,你的带价会非常高昂,而它的写操作是非常多的
(比如到双11,搞活动,对服务器压力会非常大 ,就需要很大的系统,由此对这些人来访问了,哪些商品比较热,这个计数器的变化速率可能是非常高的,很显然用关系型数据库存储没有必要,重要的是,这种存储,要求可能并不需要十分精确,显示多少,是否精确并不关键,但是能显示很重要,
因此这种数据就没有必要存储在关系型数据库当中,对此,目前生成了很多的系统,nosql,有诸多技术流派,
要很多系统来存储这堆数据,比如计数器数据,日志数据很可能分别需要不同的系统,如果后期需要复杂格式检索的话,基于任何关键词搜索,需要一个搜索引擎,搜索引擎首先是一个存储然后在存储之上构建一个索引完成搜索
比如标记为search engine ,著名的是elasticsearch,首先是一个存储,
存储计数器较多的,是redis或memcached,
但是memcached不能实现存储功能,要想实现关机数据还在,可以用一种性能不相上下的k/v存储,比如redis
称为nosql的不同流派的解决方案,这个只是两种解决方案
不管怎么将,他们的数据都是来自应用程序的服务器的,用户点击提交,购物,都会产生数据,这些数据都会记录下来,而这些数据的生成和记录一般是由我们的程序通过适配器链接我们的存储系统来完成的,但是不同的数据可能存在不同的存储系统当中,所以多种系统可能在统一个站点上可能会同时使用,
作为搜索引擎来讲,搜索的是日志,很有可能前端应用都在你这搜素,不光日志,还有商品本身也要搜索,这些内容都可能会被搜索
这是应用程序服务器,这个商品交易多少次则是由后端检索来完成的
不是用户生成的,如logo,称为页面资源文件,这些资源文件随着站点的引进会不断改版,这种引进会造成,我们的站点程序经常需要重新发布替换掉老版本,为了方便替换,一般不会放在由用户生成的数据之上,用户生成的数据除非用户明确要删除,否则数据将会一直存在,这些静态内容还是动态内容,无论是前端设计的程序还是后端设计 的程序通常应该部署在站点服务器之上,每个服务器上都有一份,他们不会变化,除非人为更新,
因次不需要共享存储之类的,每个服务器简单部署一份即可,有一些是不能查缓存的,由前端调度到服务器即可,有一些是可以被缓存的,如前端开发的内容,也可以经由varnish进行调度
分布式存储以及nosql中的代表产品redis还每讲到过
redis本身也需要分布式,
正常情况下单机提供的存储接口是,文件系统,而文件系统一般是内核级实现的,这个接口非常简洁,就是数据流接口
要想实现更高级别的管理功能,就要提供更复杂的数据管理方案,所以需要把文件系统进一步抽象为其他的,
比如mysql就把文件系统抽象为表这样的接口
还可以抽象为其他的接口,比如像redis,就是一个kv存储
elasticsearch就是抽象的文档存储,他们所提供的界面各不相同,redis主要kv数据,所提供的api所调用的方式也是kv类型,而elasticsearch就是文档操作,所提供的就是json格式的数据项
所以不同的存储对于抽象界面是不相同的,
但是只有单机来存储时,存储能力通常非常有限,当需要给大量用户提供基于cs架构的用户存储和交换服务时,对网络io和磁盘io都有非常高的要求,
单机即便能向上扩展,又能扩展到何种程度呢,用PCIE接口硬盘,网络IO用万兆以太网或光纤,但也架不住并发访问量不断的上升,所以向上扩展总是有局限性
所以所外扩展才是正途,向外扩展,就称为分布式,文件系统也可以分布式,现在称为存储,因为如果能在文件系统之上构建一个抽象接口其实就是一个分布式的数据管理系统,如果没有提供数据管理系统,也可以理解为就是一个分布式存储,如果存储是分布式的,数据就有可能存储在多个节点上,客户端存储时该发往哪一个节点,
无非有两种方式,
1.有一个固定的节点,由它来决定由哪个节点来存储
2.发给集群中的任意节点,人人都是主人公
对第一种方式一般称为有中心节点的分布式存储,对第二方式称为,无中心节点的分布式存储,无中心节点就是每个节点都是中心,
但是对数据一般而言,由两部分组成,分别是数据和元数据(属性信息),我们要存取一个文件,最起码有文件标识,即便没有文件名,也需要有个文件id,而文件名和文件id显然不是文件内容本身,这些都通常称为元数据,还有属组属主,时间戳,对分布式文件系统来讲,这些功能可能不提供的
因为对于分布式文件系统来讲,我们要做到很完善,实际上是非常困难的
有中心节点,意味这个中心节点就知道当前集群当中有几个其他节点,中心节点负责元数据,其他节点负责存储数据
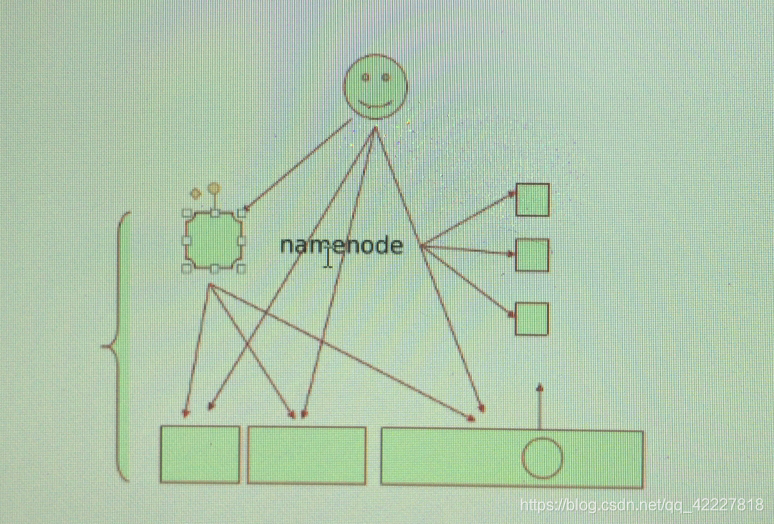
如果放在一个著名的分布式文件系统hdfs的上下文中,这个节点通常称为name node名称节点,专门存放文件名这样的元数据的,一个文件不但要存储他的名称,还要存储这个文件大体上被分割成了多少块,(本身单机系统也应该有很多索引指针,指向在磁盘上的哪些打他block来存储这些数据,但是在分布式文件系统中,这里还要进一步被抽象
(一个文件被存储时,首先文件的元数据不单包含文件名,还包含(我们把这个文件的大小给划分成固定的大小的块一般而言,这个固定大小的块和磁盘上的块不是一个概念,可以理解为此前讲的分片一样的概念,一个文件有64M为一块,存一个256的文件只要4块就够了,这4块数据,一块放在第一个几点,一块放在第二个节点,为什么说文件存储性能就高了,因为有多个不同的节点化整为零以后,只负责解决一部分问题,因此当用户存数据的时候,由这个中心节点,根据你所提供的元数据大小,来决定给你提供多少块,并决定将哪些数据放在哪些块上,一旦当其他用户再一次请求此文件的时候,通常中心节点会知道这些文件真正在哪些块上,
现在问题时存的是由名称节点存还是客户端去存。一般而言是由客户端自己去的,名称节点告诉你打算分几个块,每一块放在哪个节点上,由此客户端自己去负责找到这些节点去存下来
这样子名称节点压力不会太大,否则就是一个代理,这种方式非常类似于lvs的DR类型,(nat类型对于节点压力非常大),
是我们客户端自己去找的
对于这种应用来讲,要求我们客户端自己是智能的,必须要适配这种访问逻辑和存储协议
这就是分布式存储系统有名称节点的工作方式
**但是万一一个节点崩了,单机出现故障平均概率3年一次,如果三台就是每年故障一次,主机越多出现故障的几率越大,像IDC机房当中几乎每天都有大量的服务器被上下架,被替换掉,因为坏了。
所以,鉴于此,如果一台主机坏掉了,这个数据就丢失一部分了,丢失一部分文件就不完整,文件不完整就打不开了,
因此能够实现数据的可用性,两种方式,节点级冗余,或者数据块级冗余
如果基于节点级管理,如果替换掉,要把整个节点中的数据全部同步,而且布局起来非常固化
数据块冗余,每一个块都至冗余一份或者两份,name node会保留每个文件分多少块,而且每一块,冗余的分布在哪些节点上都有记录
这就是分布式文件系统的工作逻辑,只要是分布式就一定会出现刚才所说的问题,明明已经存下来了,客户端要写入数据,名称系欸但告诉客户端应该把哪些数据放在哪些节点上,但需要客户端自己去进行,如果元数据此时存下来了,并等待客户端把数据存完,而客户端存数据的半道,网络崩溃(导致数据没存完),随后其他用户来访问,这个数据就是一个错误的数据,所以像数据本身的完整性,需要由校验码来确保,但是节点级冗余还是块级冗余
究竟是让客户端把每一份数据都一次性写上,还是由这个块,或者节点来自行同步,显然如果让客户端去这个数据可靠性会更高,但对客户端来讲,影响可能会更大,于是我们让节点自己同步,(如果我们存到第一个节点上的时候,按照我们此前说的异步方式来做,如果有人访问时,对我们的名称节点发送它的冗余块上 ,这里的数据与我们真正的数据,是否一样,意味着,你同步过程当中,就有人来访问了,而我们这里已经开始调度了,有可能用户会访问到不同的数据,很有可能发生的,)
(还有一个关键问题,一旦我们发生分区该怎么办,如果是无中心节点的,就有可能找不到了,脑裂了
为了避免脑裂出现严重后果,quorum机制,法定票数,一旦发生脑裂,避免双方各自为势,各自为战,定义总票数,哪一方得票能大于半数总票数的一半,拥有法定合法席位,否则就认为失去合法席位,这样就避免出现脑裂了,所有quorum机制是在分布式文件系统中必须用到的机制,否则一旦脑裂,后果就非常严重,因为这毕竟是存储系统。)
这是有中心节点分布式存储系统
**
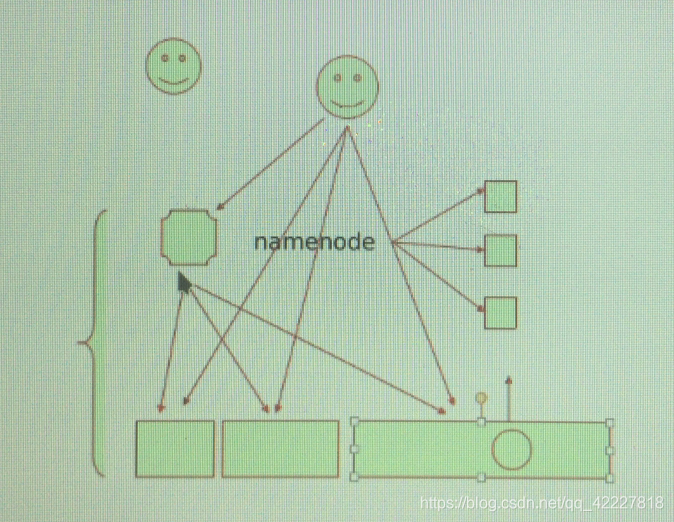
而无中心节点的,大家各自都是中心,客户端去请求任何一个节点都能得到数据,但这样以来比较麻烦,通常意味着自由即责任,你有了选择的自由,就有为选择担负后果的责任,这是很正常的
如果客户端可以随意 地找任何一个服务端来实现数据访问,万一访问的服务端数据蹦了,任意一个都能访问,意味着你就要去访问一个,你的选择范围很大,但是你总得选择一个
当你没选的时候是个概率事件,谁的可能性都有,但是一旦选定了,另外的概率就不存在
(如果了解过量子理论的话,这种事情在大千数据无处不在,整个社会的物理运作机制就是概率)
所以刚开始的时候,你从中肯定需要选择一个,
但是1.要知道哪些可选
2.选了一个之后,如果这个节点宕了,还需要从剩余的部分当中用某种概率再去选择一个(怎么选就是一个问题了)
(这就是涉及到服务发现的问题,客户端需要访问某一服务,现在最起码先知道服务在哪里,然后才能去访问,这个逻辑称为服务发现,也可以配置写死一个,但是这个服务宕了,就不能访问了,
就需要希望这个过程是个动态的,就得去发现找到谁是服务方 服务发现service discovery,,最起码有一个总线,上面有注册的内容,让大家知道哪些是可得的,可用, 如果有一个位置,服务启动会向位置说明,如果有客户端访问,你告诉它我在那里就可以了,更重要的时候,在注册的时候,这个过程是动态的,意思就是自己在这里注册的所有节点,一旦发生变化,会立即实时反馈到存储系统当中,客户端真正访问存储时,不会直接去找服务,因为不知道服务在哪里,但是可以去位置去找
(每一台主机可以去总线上注册自己的服务,当有人需要用这个服务的时候,只需要在这个总线上发现即可,因此会看到又这么多节点都在提供服务,于是就随便找一个,一旦服务器宕机了,我们可以定义一个超时机制,重新回到总线上再找一次即可)
(但是集市(总线)被炸了如何,集市被强拆了,被夷为平地,就需要冗余)对于计算机信息系统来讲,这个集市指的是,还是一个服务,为了避免服务主机当掉,大家谁也找不到谁了,做冗余),通常需要三个节点,两个为何不行
因为万一发生分区了,要确保有一方得票数能大于半数,所有分布系统都会遇到这个问题的
能做为这个总线的服务,解决访问有很多个(主要记住即可,zookeeper=zk,动物饲养员,(hadoop这个集群当中有很多组件都是分布式的,每一个组件的LOGO都是一动物,为了能让动物美好生活在一起,因此发展一个项目,专门协调这些,就是所说的总线,所以叫zookeeper)
zk使用java语言研发,特别适用于各自java系统环境,目前位置,替换这种解释器的,有运行时环境的,更加高效的编程语言叫go,用go开发高性能服务器程序,越来越流行了,基本上多数都在转向go,go开发的分布式应用,也需要总线
(etcd,是用来服务注册的解决方案,不但能注册服务发现,也能让各个牲口良好生活一起,也是一个分布式管理的协调器,不同的是任何分布式系统,有中心节点的,一旦节点出现故障,抖动了,原来中心节点挂了,选一个节点称为新的中心节点,需要一个投票或者协议)
他们各自需要一个协调协议来实现,zk使用的zab协议(zookeeper原子广播协议)
etcd是raft协议
有个著名的协议鼻祖,paxos,怕克索斯协议,其实就是用来实现分布式系统协调的,但是paxos太复杂了,太难用,于是大神级的解决方案,google公司的chubby,是paxos的实践版,zk就是它的一个山寨版本
对于分布式基础来讲,是讲的一个基本概念、
对于 分布式系统来讲,有几个问题,需要解决
1.一旦网络发生分区,余下的部分能否继续代表集群进行工作,两方如果都工作叫做脑裂,单方工作基于qurom继续工作,
分区容错,容忍失去部分节点,
2.如果数据是分布存储的,通常要在分布式系统上做冗余,冗余的时候你的数据不止在一个存储节点上有,存的时候存了AB节点,别人访问的时候只需要访问A节点即可
恰好别人找的节点,和主节点发生数据不一致该如何(存在数据不一致,就像mysql一样,主节点存完了还需要同步到从节点,在同步完成之前,主节点和从节点的数据就是不一样的,不一致时必然存在的)
数据是分布式存在各个节点上的,真正能否用这个数据,取决于最慢的一个块是什么时候到达的,
(比如三个节点,第一个节点很空,瞬间响应完成,2用了2s,3节点太忙迟迟不予响应,数据拿不到,我们就始终访问不了没准还有出现了网络延迟和故障,各种故障,可能就找不到这个节点了,或者隐隐约约才能找到这个节点,这个访问迟迟得不到正确响应
很显然对我们而言,是不能容忍的
(美国加拿大大学有一个教授发表过一篇著名的论文,任何分布式系统都仅能实现三种特性中的两种
1.P分区容错性
2.A.可用性
3.C。一致性
任何分布式系统都仅能满足三种特性的两个,一般而言,可用是最基本的,
所以系统一般是AP,AC
AP,可用而且能容错,一旦发生分区还能用,但是数据有可能不一致
AC可用能一致,但不能容错
所以现阶段系统都是在这两者之间做的这种,一般而言以AP可用性和分区容错性为主,但不是不要一致性,而是做弱一致性,允许一段数据是不一致的,比如mysql的主从,强调最终一致性,允许一个时间窗口内部的数据不一致
亚马逊的工程师发表了,一个分布式系统在实践中应该遵循base法则,(事务性存储引擎要满足ACID(尖酸刻薄)测试,base表示碱)
意味着强一致通常示满足ACID测试的,现在的系统都是base理论描述的结果
base分成几个单词
BA基本可用 basic
S:软状态 soft 允许一个数据在一个时间窗口的是不一致的
E:最终一致
base是由cap演化而来

CAP、BASE
CAP:
2000年,PODC(Principle of Distributed Computing)会议, Brewer
Consistency、Availablity、Partition tolerence
C:多个数据节点上的数据一致;
A:用户发出请求后的有限时间范围内返回结果;
P:network partition,网络发生分区后,服务是否依然可用;
CAP理论:一个分布式系统不可能同时满足C、A、P三个特性,最多可同时满足其中两者;
对于分布式系统满足分区容错性几乎是必须的。
AP:
C:弱一致性;
CP:
BASE:BA,S,E,基于CAP演化而来
BA:Basically Available,基本可用;
S:Soft state,软状态/柔性事务,即状态可以在一个时间窗口内是不同步的;
E:Eventually consistency,最终一致性;
NoSQL
(设计本身是为了满足新时代数据存储的新特性而设立的4V)
ACID:
原子性、一致性、隔离性、持久性;
2phase commit, 3phase comit, …
non SQL, Not Only SQL; Web 2.0
www.nosql-databases.org
https://db-engines.com/en/ranking
4V特性:数据量大、数据变化非常快(数据增长快、流量分布变化大、数据间耦合结构变化快)、数据源(很多地方都能生成数据)很多;
所以并发访问量会非常大,而且存取速率比较高,重要的是存从数据量还比较大,
为了解决问题,不得不考虑分布式的解决方案、
于是有了BASE,CAP这两种基础理论支撑,来支持实现分布式存储


而nosql ,not only sql,不仅仅是sql,事实上它不是sql
对于nosql而言,其实有很多的解决方案
nosql不像sql,是一种单一的解决方案,mysql,sqlserver,整体的工作逻辑都是一样的,
但nosql不是
下一代存储系统
为了解决非关系型,分布式,开源,水平扩展(横向扩展)这些痛点,
主要设计的出发点就是为了解决现在web架构当中所出现的各种各样的痛点
现代web规模的数据库系统
大致有几个特点方案自由 schema-free(mysql表字段定义好了,每一行都要遵守,严格要按照schema机制的)
schema-free表中的每一行都可以拥有不同的字段,没有严格方案限定
easy replication support, 简单 折叠支持
simple API, 简单API
eventually consistent / BASE (not ACID), 遵循base和acid
a huge amount of data 海量数据
即便如此,有几个大方向,是大家约定俗成需要遵循的
1。列示存储 Wide Column Store / Column Families
**NoSQL:Not Only SQL
即便如此,有几个大方向,是大家约定俗成需要遵循的
1.column Family:列式数据库,
著名代表: hbase,Cassandra,Hypertable,monetdb simpledb(amazon比较有名的)
2,document Store:
文档存储数据库,mongodb(最流行的非关系型数据库),elastic
**
**3,Key Value / Tuple Store 源组存储,键值
k/v:DynamoDB(亚马逊), redis(支持主从复制,支持很多数据结构,list列表,sets集合,sorted sets有序集合,hashes映射(关联数组),queues队列) **

4.第四种解决方案GraphDB:图式数据库,Neo4j,trinity,titan
** 第5种。Multimodel Databases:多模型的
Time Series / Streaming Databases:时间序列数据流存储数据库,主要是用来存储时序数据的,时序数据在监控系统种最为常用,服务器访问过程种,日志生成也是时序的,这种数据可以用时序诗句更加高效的存储下来
最著名的influxdata**

redis是一种k/v store的解决方案
遵循BSD开源协定,基于内存的数据结构存储,可用作数据库或缓存,或消息队列,
一般用于三个功能,存储,缓存,消息潜客
支持string,hashes,lists,sets,sorteds sets
辐射查询,以自己为中心,像周边进行查询 radius queries
lua spriting lua 脚本
LRU 最近最少使用的存储项淘汰
transaction 支持事务
不同级别的磁盘持久功能
high availability高可用
redis sentinel就是redis的MHA, redis自带不用安装
redis cluset redis 是一个横向扩展集群,无中心节点的分布式存储

redis:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database,
cache and message broker.
开源、内存存储、数据结构存储;
数据库、缓存、消息队列;
It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps,
hyperloglogs and geospatial indexes with radius queries.
数据结构:字符串、列表(数组)、hashes(关联数组)、集合、有序集合、bitmaps、hyperloglogs、空间索引;
Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels
of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning
with Redis Cluster.
内建的复制、Lua scripting、LRU、事务、持久存储、高可用(Sentinel,Redis Cluster)
REmote DIctionary Server:数据结构服务器,k/v,数据结构;
内存存储:in-memroy
持久化
主从(sentinel)
Cluster(shard)
数据结构服务器:
Strings, Lists, Hashs, Sets, Sorted Sets, Bitmaps, Hyperloglogs
PUB/SUB
单进程:只能有效使用单cpu核心
CPU并非瓶颈;有可能成为瓶颈的是IO
持久化:两种机制
snapshotting 快照持久
AOF append only file 仅追加文件
Replication:支持主从,前面也要做读写分离,需要一个读写分离器
主/从
主:rw
从:read-only
学任何一个存储,第一交互式接口有哪些命令















 5491
5491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









