






一、语音质量与可懂度
质量只是语音信号众多属性当中的一个,可懂度是另一种属性,这两种属性并不等效。由于这个原因,就有了不同的评估方法用来估计语音的质量和可懂度。质量在本质上是高度主观的且很难被可靠地估计。部分原因是不同的测听者有着不同的自身标准,这就导致了测听者之间的评级得分的巨大差异。
质量评价是估计说话人“如何”发出一段话语,并且得知一些诸如自然度、刺耳度和沙哑度等属性。质量拥有太多的属性以致不能一一列举,根据实际的目的我们只需要知道语音质量的几个属性。可懂度评价是估计说话人说了“什么”,比如说出的单词的意思或内容。
不同于质量,语音可懂度不是主观的,并且通过向测听者展示语音材料(句子、单词等)和让他们分辨词汇可以很容易地被测量。通过计算单词和音素的正确识别数量可以量化可懂度。
我们还不能完全理解语音可懂度和语音质量的关系,部分原因是我们无法得知质量和可懂度在声学上的关系。
语音可以被很好地理解,即使在质量很差的情况下。例如使用少量(3~6个)正弦波合成的语音和使用少量(4个)调制噪声频带合成的语音,正弦波语音给人的感觉是很机械的,但却有很高的可懂度。
相反,有时语音有很好的质量,但却不能完全地被理解。例如,语音在IP(VoIP)网络中传输或者在传输过程中产生了大量的丢包。在接收端,由于某些词的丢失在语音感知时就产生了干扰,会降低语音的可懂度。然而,剩余的词的质量还是很好的。正如这些例子所阐释的,在估计语音质量和语音可懂度时需要不同的方法。
二、语音质量的主观评价方法
主观评价方法是基于一组测听者对原始语音与合成语音进行对比试听,然后根据某种事先规定好的尺度标准来对失真语音划分等级的,主要反映的是测听者主观上对语音质量或者可懂度的一种感知。主观评价分为语音质量的主观评价和语音可懂度的主观评价,常见的语音质量主观评价方法是平均意见得分MOS(Mean Opinion Score)。另外,还有判断满意度测量DAM(Diagnostic Acceptability Measure),它是对语音质量,例如样本自身的感知质量、背景情况及其他因素进行的多维测量。
三、语音可懂度的主观评价方法
常见的语音可懂度主观评价方法是判断韵字测试DRT(Diagnostic Rhyme Test),此外还有的方法是按照听懂的单词占所有单词的个数来计算的,比如100个单词听懂了75个,则主观可懂度为0.75或者75%。可懂度是语音信号的一个重要属性。
语音接受阈 SRT(Speech Reception Threshold)在测量语音可懂度方面可以被用于替代百分比得分。无论在安静环境下还是噪声环境下都可以测量出SRT。在安静环境下,SRT被定义为表示等级或者强度等级,此时测听者识别单词的准确率是50%。通过在从低到高的不同的强度等级的语音材料的表示和强度表现图可以得到SRT。在强度表现图中,我们规定50%这个点对应着SRT。
当在噪声环境下,SRT被定义为信噪(S/N)等级,此时测听者识别单词的准确率是50%。通过从消极信噪等级(如一10dBS/N)到积极信噪等级(如10dBS/N)的不同信噪等级语音的表示和得到一个信噪等级表示图可以得到SRT。从这个图中,我们也规定50%点处对应其SRT。显然,小的消极的信噪等级值意味着表现差,而大的积极的信噪等级值则意味着表现好。信噪表现函数是S形单调递增的,如图所示。
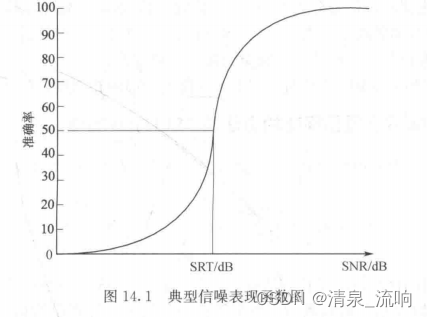
SRT的测量需要估计强度表现函数。然而,由于在不同的强度等级和信噪等级需要不断重复地做测试,这就需要耗费大量的时间才能获得强度表现函数和信噪表现函数。此外,为了得到50%点,信噪等级的范围仍是不清楚的。这就需要一个更实际更有效的方法来获得到SRT。幸运的是,存在这样一个算法且它是基于自适应心理物理程序。
这个程序是自适应的,它会根据测听者的反应系统地调节信噪等级或者安静条件下的强度等级。该程序也被称为up-down程序。语音材料最初是在高信噪等级条件下被提出的。如果测听者能够准确地识别出给出的单词,那么信噪等级就会减少一个固定的数值(即2dB),直到测听者不再识别出给出的单词。然后,信噪等级会增加相同的数值直到测听者不再识别出单词。这个过程的不断进行需要大量的实验跟踪信噪等级的改变。信噪等级从增加到减少或者从高到低的变化、从减少到增加的变化被称为反转。最初的两个反转通常被忽略,以减少最初点的偏差。最后8个反转的中间点做平均就得到了SRT。除了改变信噪等级,同样的程序可以用来得到安静环境下的SRT,我们系统地改变了声音强度等级。信噪等级或者强度等级增加还是减少的那个量称为步长,它需要仔细地选择。选择步长过大可能会使数据错误地置于相对于50%点的位置;步长太小又需要较长的时间来汇集数据。固定的步长(2~4dB)被认为是较好的。
四、语音质量客观评价方法
语音质量的主观评价提供了对语音的可靠评价指标。然而,这些方法费时,同时需要对听者进行训练。基于这些原因,一些研究人员开始探求客观的评价方法。理想情况下,客观评价算法需要在没有原始语音的情况下对语音进行评价。需要结合不同的处理过程的知识,包括低层处理和高层处理。理想的方法所得到的评价结果应与主观评价相一致。
现有的评价方法局限于要知道原始的语音信号,并且多数只能模拟低层的处理过程。尽管有这些局限性,一些评价方法与主观评价有很高的相似度。
在实现时,首先将语音信号分成10~30ms的时间帧,然后比较原始信号与处理信号之间的畸变度。将所有语音帧的畸变度进行平均。畸变度的计算可以在时域进行,也可以在频域进行。对于频域的方法,假设检测到的任何频域畸变都与质量有关。
一些客观评价方法与编码类型畸变的主观评价有很高的相似度,已经应用在编码领域。
4.1、信干噪比SINR(Signal to Interference plus Noise Ratio)
信干噪比SINR(Signal to Interference plus Noise Ratio),指的是系统中信号与干扰和噪声之和的比。
信号是指来自设备外部需要通过设备进行处理的电子信号。
干扰是指系统本身以及异系统带来的干扰,如同频干扰、多径干扰。
噪声是指经过设备后产生的原信号中并不存在的无规则的额外信号,这种信号与环境有关,不随原信号的变化而变化。
计算公式:
信干噪比的表达方式为:
SINR = 10lg[ PS /( PI + PN ) ],其中:
SINR:信干噪比,单位是dB。
PS:信号的有效功率。
PI:干扰信号的有效功率。
PN:噪声的有效功率。
4.2、信噪比(SIGNAL-NOISE RATIO)
英文名称叫做SNR或S/N(SIGNAL-NOISE RATIO),又称为讯噪比。是指一个电子设备或者电子系统中信号与噪声的比例。这里面的信号指的是来自设备外部需要通过这台设备进行处理的电子信号,噪声是指经过该设备后产生的原信号中并不存在的无规则的额外信号(或信息),并且该种信号并不随原信号的变化而变化。
计算公式:
信噪比是一个比值,也可以认为是一种倍数,在通信和电子工程中,我们希望的是信噪比越高越好。比如说信号噪声的强度是噪声的10倍、100倍、1000倍,由于这个数字可能是一个很大很大的数字,所以我们采用分贝(dB)来表示。其定义为:“两个同类功率量或可与功率类比的量之比值的常用对数乘以10等于1时的级差” 。公式如下:


4.3、时域分段信噪比(the time-domian segmental SNR,SNRseg)
时域分段信噪比(the time-domian segmental SNR,SNRseg)评价方法计算如下

式中,x(n)纯净语音信号,是处理语音信号,N是帧长(选为30ms,当采样率为8kbit/s时,采样点数为240),M是信号的帧数。该方法存在的问题之一是在语音信号的静音期,原始信号的能量非常小,使时域分段信噪比产生大的负值,使整个的测量结果产生偏差。所采用的补救方法是通过去除掉静音帧或在计算均值时,只考虑SNRseg在[-10,35]dB范围内的帧。
4.4、加权频带分段信噪比(the frequency-weighted segmental SNR,fwSNRseg)
加权频带分段信噪比(the frequency-weighted segmental SNR,fwSNRseg)计算如下
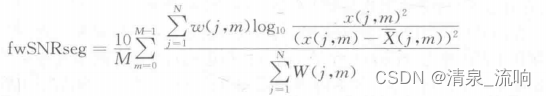
式中,W(j,m)是第j个频带的权重,K是频带数,M是信号的总的帧数,X(j,m)是第m帧中第j个频带的纯净信号的临界频带大小(激励谱),是相同频带中的处理信号相应的频谱绝对值。上式分子中的信噪比项被限定在[-10,35]dB。为了估计动态范围的影响,也可以限定SNR范围为[-15,20]、[-15,25]、[-15,30]、[-15,35]dB。选择[-10,35]dB有两个原因:①为了方便地比较前面的SNRseg方法,需要限定相同的范围;②选择这一范围是为了与一些研究中的语音的动态范围往往超过30dB相一致。
五、语音质量的感知评价方法(PESQ)
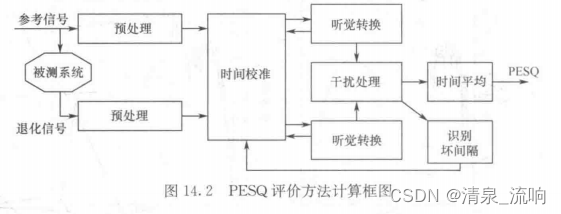
20世纪90年代中后期,在感知模型基础上针对之前一些方法对传输情况评价不准确的现象,ITU发起了一场语音评价方法的竞赛,ITU在2001年采用了PAMS的延时校准方法及PSQM99的感知模型,最后形成了PESQ方法。在众多的客观评价方法中,PESQ是在计算上最为复杂的。其计算如下:原始的纯信号和退化信号首先被置于相同的标准测听等级且经过一个滤波器的滤波,这些信号因为时间延迟要进行时间校准,然后通过一个听觉转换器的处理得到响度谱。原始信号和退化信号在响度上的差别通过时间和频率的计算和平均可以产生主观质量评级预测。PESQ产生一个1.0~4.5的得分,得分越高表示质量越好。来自互联网语音协议的应用中,大量的测试条件通过使用PESQ评价方法与主观测听测试达到了极高的相关度(r>0.92)。PESQ评价方法的结构如图所示。
参考文献:
数字语音处理及MATLAB仿真(第二版);张雪英(编著)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









