







一、爬虫的概念
1、什么是爬虫?(对于程序员和互联网)
程序员:写程序,然后去互联网上抓取数据的过程
互联网:网,由好多的a连接组成的,网的节点就是每一个a连接 url(统一资源定位符)
2、那些语言可以实现爬虫
- php,,可以做,号称世界上最优美的语言,多进程,多线程支持的不好
- java,也可以做爬虫,但是代码臃肿,重构的成本大
- c、c++,这个是你能力的体现,不是良好的选择
- python,世界上最美丽的语言,语法简单,代码优美,学习成本低,支持的模块多,非常强大的框架,scrapy
3、分类
(1)通用爬虫:百度,360,搜狐,谷歌,必应…
-
原理:
- 抓取网页
- 采集数据
- 数据处理
- 提供检索服务
-
通用爬虫如何抓取新网站
- 主动提交url
- 设置友情链接
- 百度回合DNS服务商合作抓取新网站
-
检索排名
- 竞价排名
- 根据pagerank值、访问量、点击量(SEO)
-
robots.txt
如果不想让百度爬去,可以编写robots.txt,这个协议是口头上的协议,自己写的爬虫程序不需要遵从
(2)聚焦爬虫
代替浏览器上网
二、http协议
1、概念
是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
2、http和https的区别
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
3、http请求
(1)http请求
一个完整的HTTP请求包括如下内容:一个请求行、若干消息头、以及实体内容

(2)请求行
请求方式有:POST、GET、HEAD、OPTIONS、DELETE、TRACE、PUT,常用的有: GET、 POST
- get和post的区别
- 一般在浏览器中输入网址访问资源都是通过GET方式;在FORM提交中,可以通过Method指定提交方式为GET或者POST,默认为GET提交
- GET提交,请求的数据会附在URL之后,以?分割URL和传输数据,多个参数用&连接; POST提交,把提交的数据放置在是HTTP包的包体中。因此,GET提交的数据会在地址栏中显示出来,而POST提交,地址栏不会改变
- GET方式的特点:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K;如果请求方式为POST方式,则可以在请求的实体内容中向服务器发送数据,Post方式的特点:传送的数据量无限制。
- 安全性:POST的安全性要比GET的安全性高。
- get是从服务器上获取数据,post是向服务器传送数据。
(3)请求头
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
4、HTTP响应包括的内容
一个HTTP响应代表服务器向客户端回送的数据,它包括: 一个状态行、若干消息头、以及实体内容 。
(1)状态行
·
状态行格式: HTTP版本号 状态码 原因叙述
举例:HTTP/1.1 200 OK
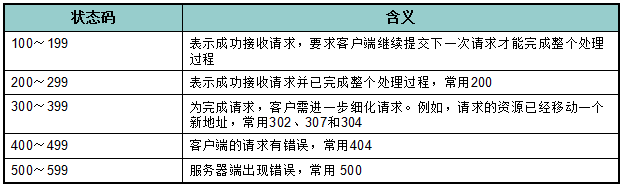
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
400 (错误请求) 服务器不理解请求的语法。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
408 (请求超时) 服务器等候请求时发生超时。
499 情况就是后端服务器很慢,用户自己取消了。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
(2)HTTP响应细节——常用响应头
HTTP响应中的常用响应头(消息头)
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
三、urllib库
python3:urllib.request urllib.parse
1、字符串和字节类型之间的转换
- encode()字符串–>字节类型
若小括号里面不写参数,默认是utf8;若写就写gbk - decode()字节类型–>字符串
2、urllib.request
urlopen(url)
urlretrieve(url,image_path)
内置函数
response
read() 读取相应的内容,内容是字节类型
geturl() 获取请求的url
getheaders() 获取头部信息,列表里面有元组
getcode() 获取状态码
readlines() 按行读取,返回列表,都是字节类型
import urllib.request
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url=url) 打开网页
print(response.geturl()) # 获取请求的url
print(dict(response.getheaders())) #获取头部信息,列表里面有元组
print(response.getcode()) #获取状态码
print(response.readlines()) #按行读取,返回列表,都是字节类型
print(response.read().decode()) #读取响应的内容,内容是字节类型
with open('baidu.html','w',encoding='utf8') as fp: #把读取的内容写到html文件中
fp.write(response.read().decode())
image_url = 'https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=47daca436409c93d07f209f1a7069fe1/0b46f21fbe096b6378e9de1d0f338744eaf8ac8f.jpg' #某图片地址
response = urllib.request.urlopen(image_url) #打开网页
with open('lvs1.jpg','wb') as fp:
fp.write(response.read())
urllib.request.urlretrieve(image_url,'lvs.jpg') #将url内容直接下载到本地
3、urllib.parse
urllib.parse
quote url编码函数,讲中文进行转化为%xxx
unquote url解码函数,将%xxx转化为指定字符
urlencode 给定一个字典,将字典拼接为query_string,并且实现了编码的功能
import urllib.parse
import urllib.request
image_url = 'https://gss2.bdstatic.com/-fo3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=47daca436409c93d07f209f1a7069fe1/0b46f21fbe096b6378e9de1d0f338744eaf8ac8f.jpg'
url = 'http://www.baidu.com/index.html?name=狗蛋&pwd=123345'
ret =urllib.parse.quote(url)
re = urllib.parse.unquote(ret)
print(re)
word = input('请输入你想要搜索的内容:')
url = 'http://www.baidu.com/s?'
data = {
'ie': 'utf-8',
'wd': word,
}
query_string = urllib.parse.urlencode(data)
url += query_string
response = urllib.request.urlopen(url)
filename = word + '.html'
with open(filename, 'wb') as fp:
fp.write(response.read())
url = 'http://www.baidu.com/index.html?name=狗蛋&pwd=123345'
name = 'goudan'
age = 18
sex = 'nv'
heigth = '180'
date = {
'name': name,
'age': age,
'sex': sex,
'height': 180,
}
lt = []
for k, v in date.items():
lt.append(k + '=' + str(v))
query_string = '&'.join(lt)
query_string = urllib.parse.urlencode(date)
print(query_string)
url = url + '?' + query_string
print(url)

4、构建头部信息(这是反爬的第一步)
伪装自己的UA(User Agent),让服务器端认为你是浏览器在上网
构建请求对象:urllib.request.Request()
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_default_https_context
url = 'http://www.baidu.com/'
#伪装头部信息user-agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36'
}
#创建请求信息
request = urllib.request.Request(url=url,headers=headers)
#发送请求
response = urllib.request.urlopen(request)
print(response.read().decode())
















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









